 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Fair Graph Neural Networks Via Dual-Teacher Knowledge Distillation
Nov 30, 2024Graph Neural Networks (GNNs) have demonstrated strong performance in graph representation learning across various real-world applications. However, they often produce biased predictions caused by sensitive attributes, such as religion or gender, an issue that has been largely overlooked in existing methods. Recently, numerous studies have focused on reducing biases in GNNs. However, these approaches often rely on training with partial data (e.g., using either node features or graph structure alone), which can enhance fairness but frequently compromises model utility due to the limited utilization of available graph information. To address this tradeoff, we propose an effective strategy to balance fairness and utility in knowledge distillation. Specifically, we introduce FairDTD, a novel Fair representation learning framework built on Dual-Teacher Distillation, leveraging a causal graph model to guide and optimize the design of the distillation process. Specifically, FairDTD employs two fairness-oriented teacher models: a feature teacher and a structure teacher, to facilitate dual distillation, with the student model learning fairness knowledge from the teachers while also leveraging full data to mitigate utility loss. To enhance information transfer, we incorporate graph-level distillation to provide an indirect supplement of graph information during training, as well as a node-specific temperature module to improve the comprehensive transfer of fair knowledge. Experiments on diverse benchmark datasets demonstrate that FairDTD achieves optimal fairness while preserving high model utility, showcasing its effectiveness in fair representation learning for GNNs.
Multi-Cause Deconfounding for Recommender Systems with Latent Confounders
Oct 16, 2024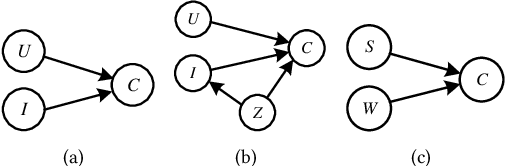



In recommender systems, various latent confounding factors (e.g., user social environment and item public attractiveness) can affect user behavior, item exposure, and feedback in distinct ways. These factors may directly or indirectly impact user feedback and are often shared across items or users, making them multi-cause latent confounders. However, existing methods typically fail to account for latent confounders between users and their feedback, as well as those between items and user feedback simultaneously. To address the problem of multi-cause latent confounders, we propose a multi-cause deconfounding method for recommender systems with latent confounders (MCDCF). MCDCF leverages multi-cause causal effect estimation to learn substitutes for latent confounders associated with both users and items, using user behaviour data. Specifically, MCDCF treats the multiple items that users interact with and the multiple users that interact with items as treatment variables, enabling it to learn substitutes for the latent confounders that influence the estimation of causality between users and their feedback, as well as between items and user feedback. Additionally, we theoretically demonstrate the soundness of our MCDCF method. Extensive experiments on three real-world datasets demonstrate that our MCDCF method effectively recovers latent confounders related to users and items, reducing bias and thereby improving recommendation accuracy.
Towards Fair Graph Representation Learning in Social Networks
Oct 15, 2024
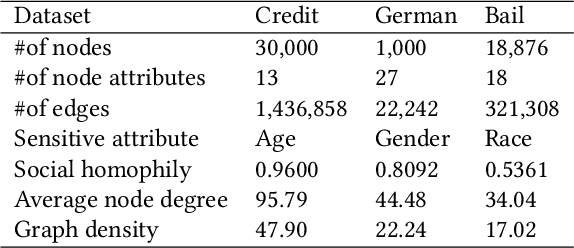
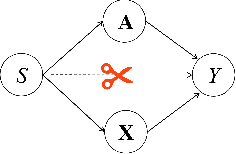
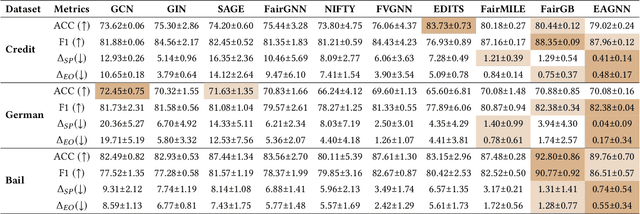
With the widespread use of Graph Neural Networks (GNNs) for representation learning from network data, the fairness of GNN models has raised great attention lately. Fair GNNs aim to ensure that node representations can be accurately classified, but not easily associated with a specific group. Existing advanced approaches essentially enhance the generalisation of node representation in combination with data augmentation strategy, and do not directly impose constraints on the fairness of GNNs. In this work, we identify that a fundamental reason for the unfairness of GNNs in social network learning is the phenomenon of social homophily, i.e., users in the same group are more inclined to congregate. The message-passing mechanism of GNNs can cause users in the same group to have similar representations due to social homophily, leading model predictions to establish spurious correlations with sensitive attributes. Inspired by this reason, we propose a method called Equity-Aware GNN (EAGNN) towards fair graph representation learning. Specifically, to ensure that model predictions are independent of sensitive attributes while maintaining prediction performance, we introduce constraints for fair representation learning based on three principles: sufficiency, independence, and separation. We theoretically demonstrate that our EAGNN method can effectively achieve group fairness. Extensive experiments on three datasets with varying levels of social homophily illustrate that our EAGNN method achieves the state-of-the-art performance across two fairness metrics and offers competitive effectiveness.
Mitigating Propensity Bias of Large Language Models for Recommender Systems
Sep 30, 2024

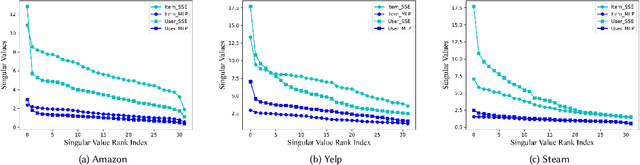
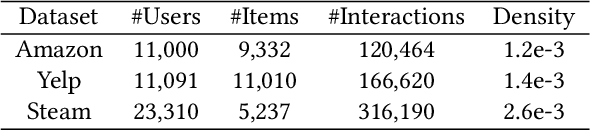
The rapid development of Large Language Models (LLMs) creates new opportunities for recommender systems, especially by exploiting the side information (e.g., descriptions and analyses of items) generated by these models. However, aligning this side information with collaborative information from historical interactions poses significant challenges. The inherent biases within LLMs can skew recommendations, resulting in distorted and potentially unfair user experiences. On the other hand, propensity bias causes side information to be aligned in such a way that it often tends to represent all inputs in a low-dimensional subspace, leading to a phenomenon known as dimensional collapse, which severely restricts the recommender system's ability to capture user preferences and behaviours. To address these issues, we introduce a novel framework named Counterfactual LLM Recommendation (CLLMR). Specifically, we propose a spectrum-based side information encoder that implicitly embeds structural information from historical interactions into the side information representation, thereby circumventing the risk of dimension collapse. Furthermore, our CLLMR approach explores the causal relationships inherent in LLM-based recommender systems. By leveraging counterfactual inference, we counteract the biases introduced by LLMs. Extensive experiments demonstrate that our CLLMR approach consistently enhances the performance of various recommender models.
Debiased Contrastive Representation Learning for Mitigating Dual Biases in Recommender Systems
Aug 19, 2024



In recommender systems, popularity and conformity biases undermine recommender effectiveness by disproportionately favouring popular items, leading to their over-representation in recommendation lists and causing an unbalanced distribution of user-item historical data. We construct a causal graph to address both biases and describe the abstract data generation mechanism. Then, we use it as a guide to develop a novel Debiased Contrastive Learning framework for Mitigating Dual Biases, called DCLMDB. In DCLMDB, both popularity bias and conformity bias are handled in the model training process by contrastive learning to ensure that user choices and recommended items are not unduly influenced by conformity and popularity. Extensive experiments on two real-world datasets, Movielens-10M and Netflix, show that DCLMDB can effectively reduce the dual biases, as well as significantly enhance the accuracy and diversity of recommendations.
Community-Centric Graph Unlearning
Aug 19, 2024



Graph unlearning technology has become increasingly important since the advent of the `right to be forgotten' and the growing concerns about the privacy and security of artificial intelligence. Graph unlearning aims to quickly eliminate the effects of specific data on graph neural networks (GNNs). However, most existing deterministic graph unlearning frameworks follow a balanced partition-submodel training-aggregation paradigm, resulting in a lack of structural information between subgraph neighborhoods and redundant unlearning parameter calculations. To address this issue, we propose a novel Graph Structure Mapping Unlearning paradigm (GSMU) and a novel method based on it named Community-centric Graph Eraser (CGE). CGE maps community subgraphs to nodes, thereby enabling the reconstruction of a node-level unlearning operation within a reduced mapped graph. CGE makes the exponential reduction of both the amount of training data and the number of unlearning parameters. Extensive experiments conducted on five real-world datasets and three widely used GNN backbones have verified the high performance and efficiency of our CGE method, highlighting its potential in the field of graph unlearning.