 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAEL: Leveraging Large Language Models with Adaptive Mixture-of-Experts for Smart Contract Vulnerability Detection
Jul 30, 2025With the increasing security issues in blockchain, smart contract vulnerability detection has become a research focus. Existing vulnerability detection methods have their limitations: 1) Static analysis methods struggle with complex scenarios. 2) Methods based on specialized pre-trained models perform well on specific datasets but have limited generalization capabilities. In contrast, general-purpose Large Language Models (LLMs) demonstrate impressive ability in adapting to new vulnerability patterns. However, they often underperform on specific vulnerability types compared to methods based on specialized pre-trained models. We also observe that explanations generated by general-purpose LLMs can provide fine-grained code understanding information, contributing to improved detection performance. Inspired by these observations, we propose SAEL, an LLM-based framework for smart contract vulnerability detection. We first design targeted prompts to guide LLMs in identifying vulnerabilities and generating explanations, which serve as prediction features. Next, we apply prompt-tuning on CodeT5 and T5 to process contract code and explanations, enhancing task-specific performance. To combine the strengths of each approach, we introduce an Adaptive Mixture-of-Experts architecture. This dynamically adjusts feature weights via a Gating Network, which selects relevant features using TopK filtering and Softmax normalization, and incorporates a Multi-Head Self-Attention mechanism to enhance cross-feature relationships. This design enables effective integration of LLM predictions, explanation features, and code features through gradient optimization. The loss function jointly considers both independent feature performance and overall weighted predictions. Experiments show that SAEL outperforms existing methods across various vulnerabilities.
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
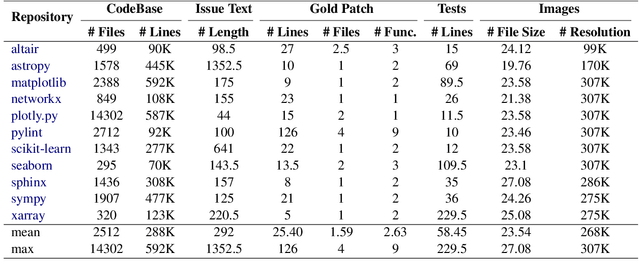
Apr 03, 2025The task of issue resolving is to modify a codebase to generate a patch that addresses a given issue. However, existing benchmarks, such as SWE-bench, focus almost exclusively on Python, making them insufficient for evaluating Large Language Models (LLMs) across diverse software ecosystems. To address this, we introduce a multilingual issue-resolving benchmark, called Multi-SWE-bench, covering Java, TypeScript, JavaScript, Go, Rust, C, and C++. It includes a total of 1,632 high-quality instances, which were carefully annotated from 2,456 candidates by 68 expert annotators, ensuring that the benchmark can provide an accurate and reliable evaluation. Based on Multi-SWE-bench, we evaluate a series of state-of-the-art models using three representative methods (Agentless, SWE-agent, and OpenHands) and present a comprehensive analysis with key empirical insights. In addition, we launch a Multi-SWE-RL open-source community, aimed at building large-scale reinforcement learning (RL) training datasets for issue-resolving tasks. As an initial contribution, we release a set of 4,723 well-structured instances spanning seven programming languages, laying a solid foundation for RL research in this domain. More importantly, we open-source our entire data production pipeline, along with detailed tutorials, encouraging the open-source community to continuously contribute and expand the dataset. We envision our Multi-SWE-bench and the ever-growing Multi-SWE-RL community as catalysts for advancing RL toward its full potential, bringing us one step closer to the dawn of AGI.
CodeV: Issue Resolving with Visual Data
Dec 23, 2024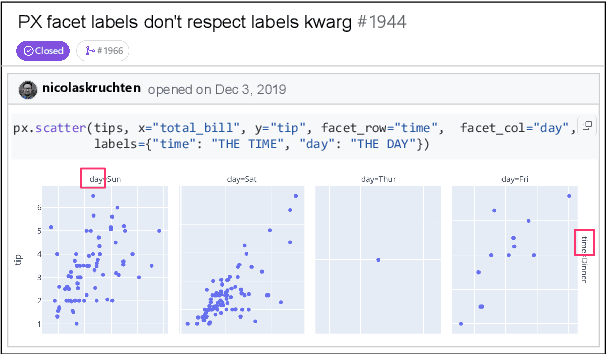


Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.
Smart-LLaMA: Two-Stage Post-Training of Large Language Models for Smart Contract Vulnerability Detection and Explanation
Nov 09, 2024With the rapid development of blockchain technology, smart contract security has become a critical challenge. Existing smart contract vulnerability detection methods face three main issues: (1) Insufficient quality of datasets, lacking detailed explanations and precise vulnerability locations. (2) Limited adaptability of large language models (LLMs) to the smart contract domain, as most LLMs are pre-trained on general text data but minimal smart contract-specific data. (3) Lack of high-quality explanations for detected vulnerabilities, as existing methods focus solely on detection without clear explanations. These limitations hinder detection performance and make it harder for developers to understand and fix vulnerabilities quickly, potentially leading to severe financial losses. To address these problems, we propose Smart-LLaMA, an advanced detection method based on the LLaMA language model. First, we construct a comprehensive dataset covering four vulnerability types with labels, detailed explanations, and precise vulnerability locations. Second, we introduce Smart Contract-Specific Continual Pre-Training, using raw smart contract data to enable the LLM to learn smart contract syntax and semantics, enhancing their domain adaptability. Furthermore, we propose Explanation-Guided Fine-Tuning, which fine-tunes the LLM using paired vulnerable code and explanations, enabling both vulnerability detection and reasoned explanations. We evaluate explanation quality through LLM and human evaluation, focusing on Correctness, Completeness, and Conciseness. Experimental results show that Smart-LLaMA outperforms state-of-the-art baselines, with average improvements of 6.49% in F1 score and 3.78% in accuracy, while providing reliable explanations.
Multi-Cause Deconfounding for Recommender Systems with Latent Confounders
Oct 16, 2024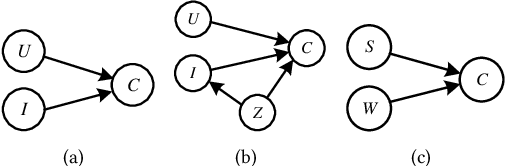



In recommender systems, various latent confounding factors (e.g., user social environment and item public attractiveness) can affect user behavior, item exposure, and feedback in distinct ways. These factors may directly or indirectly impact user feedback and are often shared across items or users, making them multi-cause latent confounders. However, existing methods typically fail to account for latent confounders between users and their feedback, as well as those between items and user feedback simultaneously. To address the problem of multi-cause latent confounders, we propose a multi-cause deconfounding method for recommender systems with latent confounders (MCDCF). MCDCF leverages multi-cause causal effect estimation to learn substitutes for latent confounders associated with both users and items, using user behaviour data. Specifically, MCDCF treats the multiple items that users interact with and the multiple users that interact with items as treatment variables, enabling it to learn substitutes for the latent confounders that influence the estimation of causality between users and their feedback, as well as between items and user feedback. Additionally, we theoretically demonstrate the soundness of our MCDCF method. Extensive experiments on three real-world datasets demonstrate that our MCDCF method effectively recovers latent confounders related to users and items, reducing bias and thereby improving recommendation accuracy.
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024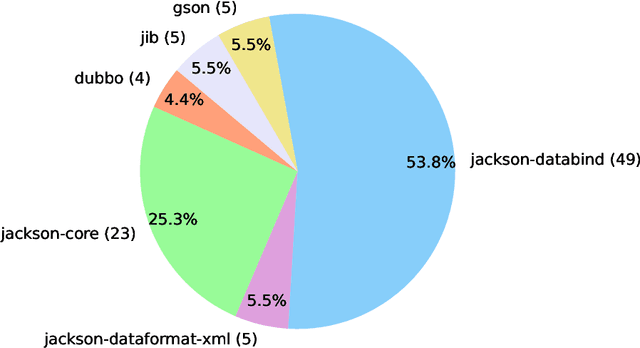



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
Data-driven Conditional Instrumental Variables for Debiasing Recommender Systems
Aug 19, 2024



In recommender systems, latent variables can cause user-item interaction data to deviate from true user preferences. This biased data is then used to train recommendation models, further amplifying the bias and ultimately compromising both recommendation accuracy and user satisfaction. Instrumental Variable (IV) methods are effective tools for addressing the confounding bias introduced by latent variables; however, identifying a valid IV is often challenging. To overcome this issue, we propose a novel data-driven conditional IV (CIV) debiasing method for recommender systems, called CIV4Rec. CIV4Rec automatically generates valid CIVs and their corresponding conditioning sets directly from interaction data, significantly reducing the complexity of IV selection while effectively mitigating the confounding bias caused by latent variables in recommender systems. Specifically, CIV4Rec leverages a variational autoencoder (VAE) to generate the representations of the CIV and its conditional set from interaction data, followed by the application of least squares to derive causal representations for click prediction. Extensive experiments on two real-world datasets, Movielens-10M and Douban-Movie, demonstrate that our CIV4Rec successfully identifies valid CIVs, effectively reduces bias, and consequently improves recommendation accuracy.
Debiased Contrastive Representation Learning for Mitigating Dual Biases in Recommender Systems
Aug 19, 2024



In recommender systems, popularity and conformity biases undermine recommender effectiveness by disproportionately favouring popular items, leading to their over-representation in recommendation lists and causing an unbalanced distribution of user-item historical data. We construct a causal graph to address both biases and describe the abstract data generation mechanism. Then, we use it as a guide to develop a novel Debiased Contrastive Learning framework for Mitigating Dual Biases, called DCLMDB. In DCLMDB, both popularity bias and conformity bias are handled in the model training process by contrastive learning to ensure that user choices and recommended items are not unduly influenced by conformity and popularity. Extensive experiments on two real-world datasets, Movielens-10M and Netflix, show that DCLMDB can effectively reduce the dual biases, as well as significantly enhance the accuracy and diversity of recommendations.