 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAEL: Leveraging Large Language Models with Adaptive Mixture-of-Experts for Smart Contract Vulnerability Detection
Jul 30, 2025With the increasing security issues in blockchain, smart contract vulnerability detection has become a research focus. Existing vulnerability detection methods have their limitations: 1) Static analysis methods struggle with complex scenarios. 2) Methods based on specialized pre-trained models perform well on specific datasets but have limited generalization capabilities. In contrast, general-purpose Large Language Models (LLMs) demonstrate impressive ability in adapting to new vulnerability patterns. However, they often underperform on specific vulnerability types compared to methods based on specialized pre-trained models. We also observe that explanations generated by general-purpose LLMs can provide fine-grained code understanding information, contributing to improved detection performance. Inspired by these observations, we propose SAEL, an LLM-based framework for smart contract vulnerability detection. We first design targeted prompts to guide LLMs in identifying vulnerabilities and generating explanations, which serve as prediction features. Next, we apply prompt-tuning on CodeT5 and T5 to process contract code and explanations, enhancing task-specific performance. To combine the strengths of each approach, we introduce an Adaptive Mixture-of-Experts architecture. This dynamically adjusts feature weights via a Gating Network, which selects relevant features using TopK filtering and Softmax normalization, and incorporates a Multi-Head Self-Attention mechanism to enhance cross-feature relationships. This design enables effective integration of LLM predictions, explanation features, and code features through gradient optimization. The loss function jointly considers both independent feature performance and overall weighted predictions. Experiments show that SAEL outperforms existing methods across various vulnerabilities.
Towards Practical Defect-Focused Automated Code Review
May 23, 2025
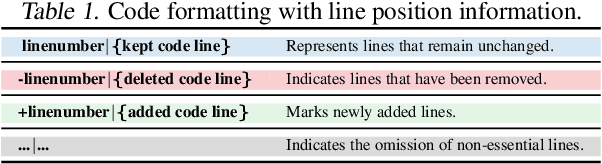
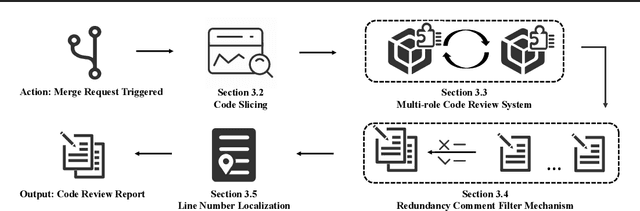
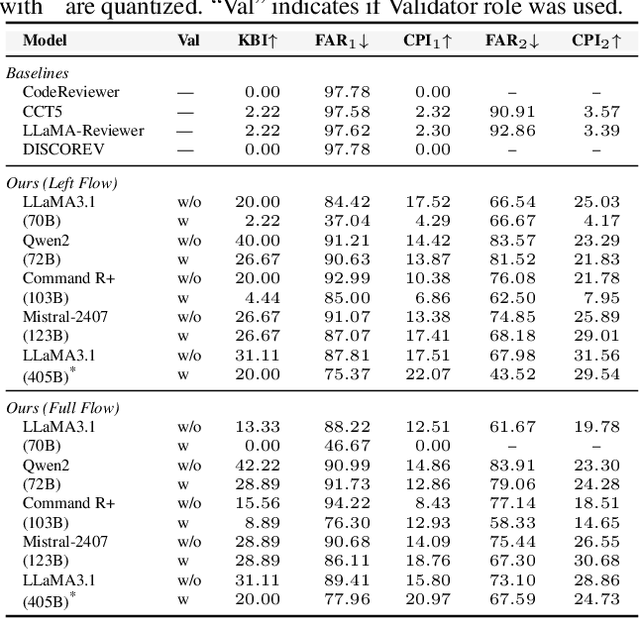
The complexity of code reviews has driven efforts to automate review comments, but prior approaches oversimplify this task by treating it as snippet-level code-to-text generation and relying on text similarity metrics like BLEU for evaluation. These methods overlook repository context, real-world merge request evaluation, and defect detection, limiting their practicality. To address these issues, we explore the full automation pipeline within the online recommendation service of a company with nearly 400 million daily active users, analyzing industry-grade C++ codebases comprising hundreds of thousands of lines of code. We identify four key challenges: 1) capturing relevant context, 2) improving key bug inclusion (KBI), 3) reducing false alarm rates (FAR), and 4) integrating human workflows. To tackle these, we propose 1) code slicing algorithms for context extraction, 2) a multi-role LLM framework for KBI, 3) a filtering mechanism for FAR reduction, and 4) a novel prompt design for better human interaction. Our approach, validated on real-world merge requests from historical fault reports, achieves a 2x improvement over standard LLMs and a 10x gain over previous baselines. While the presented results focus on C++, the underlying framework design leverages language-agnostic principles (e.g., AST-based analysis), suggesting potential for broader applicability.
DeepCRCEval: Revisiting the Evaluation of Code Review Comment Generation
Dec 24, 2024Code review is a vital but demanding aspect of software development, generating significant interest in automating review comments. Traditional evaluation methods for these comments, primarily based on text similarity, face two major challenges: inconsistent reliability of human-authored comments in open-source projects and the weak correlation of text similarity with objectives like enhancing code quality and detecting defects. This study empirically analyzes benchmark comments using a novel set of criteria informed by prior research and developer interviews. We then similarly revisit the evaluation of existing methodologies. Our evaluation framework, DeepCRCEval, integrates human evaluators and Large Language Models (LLMs) for a comprehensive reassessment of current techniques based on the criteria set. Besides, we also introduce an innovative and efficient baseline, LLM-Reviewer, leveraging the few-shot learning capabilities of LLMs for a target-oriented comparison. Our research highlights the limitations of text similarity metrics, finding that less than 10% of benchmark comments are high quality for automation. In contrast, DeepCRCEval effectively distinguishes between high and low-quality comments, proving to be a more reliable evaluation mechanism. Incorporating LLM evaluators into DeepCRCEval significantly boosts efficiency, reducing time and cost by 88.78% and 90.32%, respectively. Furthermore, LLM-Reviewer demonstrates significant potential of focusing task real targets in comment generation.
Smart-LLaMA: Two-Stage Post-Training of Large Language Models for Smart Contract Vulnerability Detection and Explanation
Nov 09, 2024With the rapid development of blockchain technology, smart contract security has become a critical challenge. Existing smart contract vulnerability detection methods face three main issues: (1) Insufficient quality of datasets, lacking detailed explanations and precise vulnerability locations. (2) Limited adaptability of large language models (LLMs) to the smart contract domain, as most LLMs are pre-trained on general text data but minimal smart contract-specific data. (3) Lack of high-quality explanations for detected vulnerabilities, as existing methods focus solely on detection without clear explanations. These limitations hinder detection performance and make it harder for developers to understand and fix vulnerabilities quickly, potentially leading to severe financial losses. To address these problems, we propose Smart-LLaMA, an advanced detection method based on the LLaMA language model. First, we construct a comprehensive dataset covering four vulnerability types with labels, detailed explanations, and precise vulnerability locations. Second, we introduce Smart Contract-Specific Continual Pre-Training, using raw smart contract data to enable the LLM to learn smart contract syntax and semantics, enhancing their domain adaptability. Furthermore, we propose Explanation-Guided Fine-Tuning, which fine-tunes the LLM using paired vulnerable code and explanations, enabling both vulnerability detection and reasoned explanations. We evaluate explanation quality through LLM and human evaluation, focusing on Correctness, Completeness, and Conciseness. Experimental results show that Smart-LLaMA outperforms state-of-the-art baselines, with average improvements of 6.49% in F1 score and 3.78% in accuracy, while providing reliable explanations.