 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^2$-LLM: An End-to-end Conversational Audio Avatar Large Language Model
Feb 04, 2026Developing expressive and responsive conversational digital humans is a cornerstone of next-generation human-computer interaction. While large language models (LLMs) have significantly enhanced dialogue capabilities, most current systems still rely on cascaded architectures that connect independent modules. These pipelines are often plagued by accumulated errors, high latency, and poor real-time performance. Lacking access to the underlying conversational context, these pipelines inherently prioritize rigid lip-sync over emotional depth. To address these challenges, we propose A$^2$-LLM, an end-to-end conversational audio avatar large language model that jointly reasons about language, audio prosody, and 3D facial motion within a unified framework. To facilitate training, we introduce FLAME-QA, a high-quality multimodal dataset designed to align semantic intent with expressive facial dynamics within a QA format. By leveraging deep semantic understanding, A$^2$-LLM generates emotionally rich facial movements beyond simple lip-synchronization. Experimental results demonstrate that our system achieves superior emotional expressiveness while maintaining real-time efficiency (500 ms latency, 0.7 RTF).
Not All Tokens Are What You Need In Thinking
May 23, 2025Modern reasoning models, such as OpenAI's o1 and DeepSeek-R1, exhibit impressive problem-solving capabilities but suffer from critical inefficiencies: high inference latency, excessive computational resource consumption, and a tendency toward overthinking -- generating verbose chains of thought (CoT) laden with redundant tokens that contribute minimally to the final answer. To address these issues, we propose Conditional Token Selection (CTS), a token-level compression framework with a flexible and variable compression ratio that identifies and preserves only the most essential tokens in CoT. CTS evaluates each token's contribution to deriving correct answers using conditional importance scoring, then trains models on compressed CoT. Extensive experiments demonstrate that CTS effectively compresses long CoT while maintaining strong reasoning performance. Notably, on the GPQA benchmark, Qwen2.5-14B-Instruct trained with CTS achieves a 9.1% accuracy improvement with 13.2% fewer reasoning tokens (13% training token reduction). Further reducing training tokens by 42% incurs only a marginal 5% accuracy drop while yielding a 75.8% reduction in reasoning tokens, highlighting the prevalence of redundancy in existing CoT.
Long-Short Chain-of-Thought Mixture Supervised Fine-Tuning Eliciting Efficient Reasoning in Large Language Models
May 06, 2025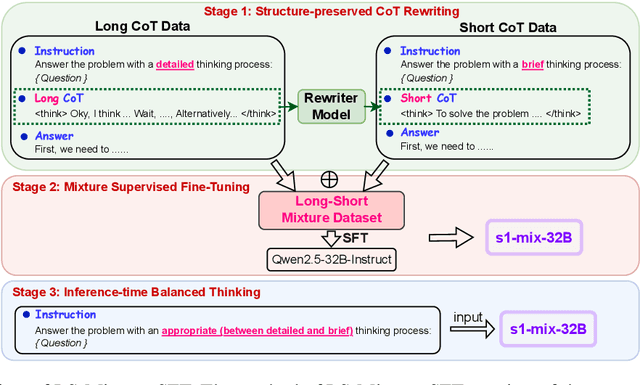
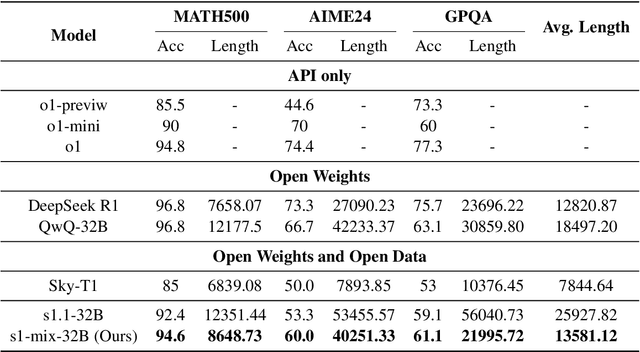
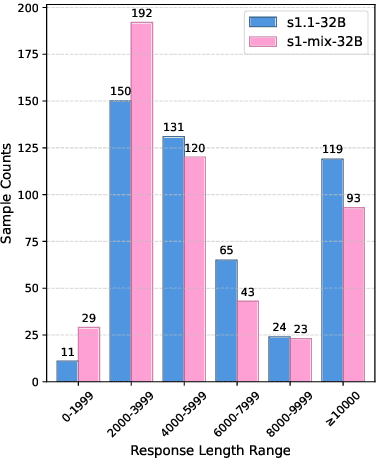
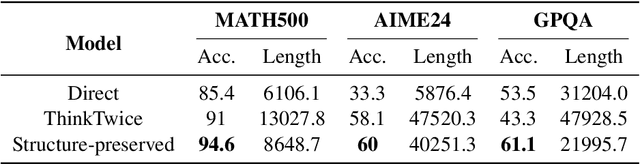
Recent advances in large language models have demonstrated that Supervised Fine-Tuning (SFT) with Chain-of-Thought (CoT) reasoning data distilled from large reasoning models (e.g., DeepSeek R1) can effectively transfer reasoning capabilities to non-reasoning models. However, models fine-tuned with this approach inherit the "overthinking" problem from teacher models, producing verbose and redundant reasoning chains during inference. To address this challenge, we propose \textbf{L}ong-\textbf{S}hort Chain-of-Thought \textbf{Mixture} \textbf{S}upervised \textbf{F}ine-\textbf{T}uning (\textbf{LS-Mixture SFT}), which combines long CoT reasoning dataset with their short counterparts obtained through structure-preserved rewriting. Our experiments demonstrate that models trained using the LS-Mixture SFT method, compared to those trained with direct SFT, achieved an average accuracy improvement of 2.3\% across various benchmarks while substantially reducing model response length by approximately 47.61\%. This work offers an approach to endow non-reasoning models with reasoning capabilities through supervised fine-tuning while avoiding the inherent overthinking problems inherited from teacher models, thereby enabling efficient reasoning in the fine-tuned models.
Fréchet Cumulative Covariance Net for Deep Nonlinear Sufficient Dimension Reduction with Random Objects
Feb 21, 2025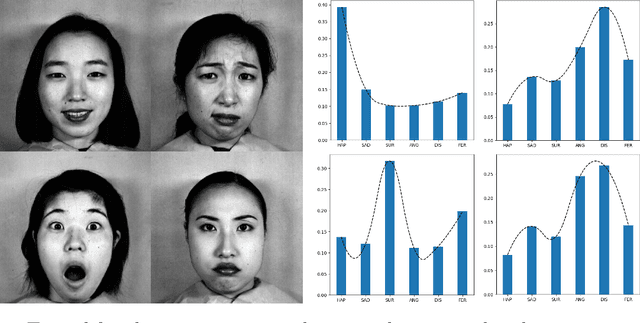
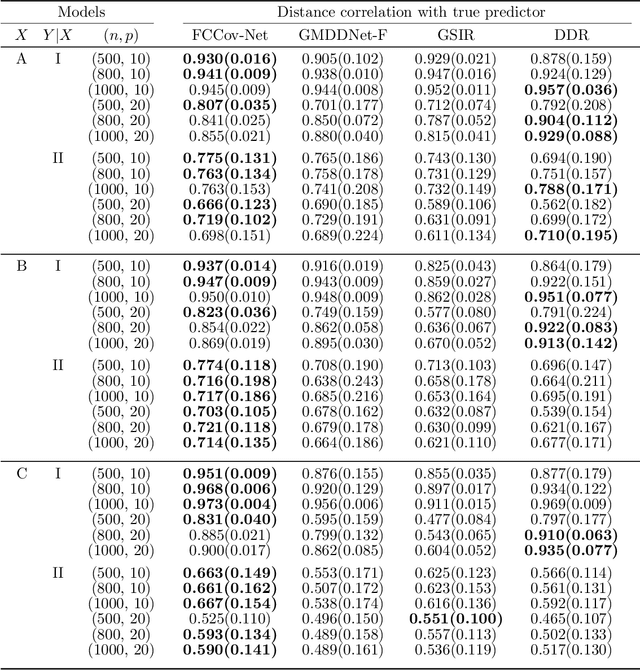
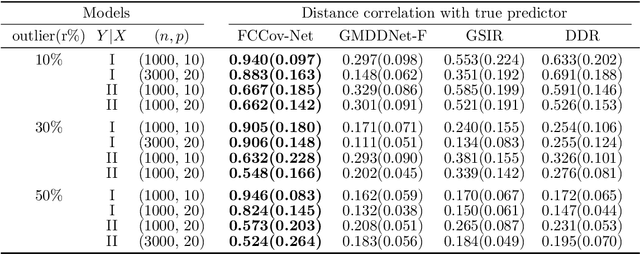
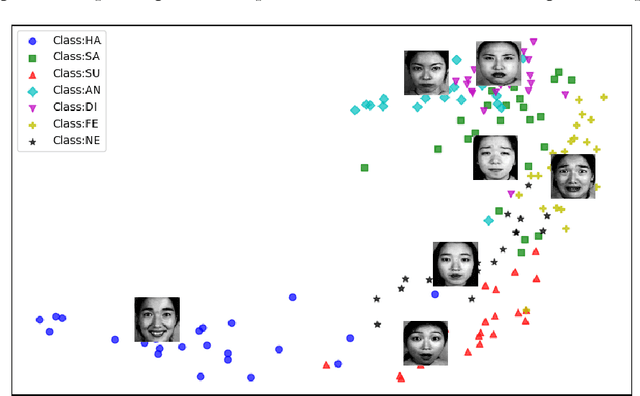
Nonlinear sufficient dimension reduction\citep{libing_generalSDR}, which constructs nonlinear low-dimensional representations to summarize essential features of high-dimensional data, is an important branch of representation learning. However, most existing methods are not applicable when the response variables are complex non-Euclidean random objects, which are frequently encountered in many recent statistical applications. In this paper, we introduce a new statistical dependence measure termed Fr\'echet Cumulative Covariance (FCCov) and develop a novel nonlinear SDR framework based on FCCov. Our approach is not only applicable to complex non-Euclidean data, but also exhibits robustness against outliers. We further incorporate Feedforward Neural Networks (FNNs) and Convolutional Neural Networks (CNNs) to estimate nonlinear sufficient directions in the sample level. Theoretically, we prove that our method with squared Frobenius norm regularization achieves unbiasedness at the $\sigma$-field level. Furthermore, we establish non-asymptotic convergence rates for our estimators based on FNNs and ResNet-type CNNs, which match the minimax rate of nonparametric regression up to logarithmic factors. Intensive simulation studies verify the performance of our methods in both Euclidean and non-Euclidean settings. We apply our method to facial expression recognition datasets and the results underscore more realistic and broader applicability of our proposal.
Smart-LLaMA: Two-Stage Post-Training of Large Language Models for Smart Contract Vulnerability Detection and Explanation
Nov 09, 2024With the rapid development of blockchain technology, smart contract security has become a critical challenge. Existing smart contract vulnerability detection methods face three main issues: (1) Insufficient quality of datasets, lacking detailed explanations and precise vulnerability locations. (2) Limited adaptability of large language models (LLMs) to the smart contract domain, as most LLMs are pre-trained on general text data but minimal smart contract-specific data. (3) Lack of high-quality explanations for detected vulnerabilities, as existing methods focus solely on detection without clear explanations. These limitations hinder detection performance and make it harder for developers to understand and fix vulnerabilities quickly, potentially leading to severe financial losses. To address these problems, we propose Smart-LLaMA, an advanced detection method based on the LLaMA language model. First, we construct a comprehensive dataset covering four vulnerability types with labels, detailed explanations, and precise vulnerability locations. Second, we introduce Smart Contract-Specific Continual Pre-Training, using raw smart contract data to enable the LLM to learn smart contract syntax and semantics, enhancing their domain adaptability. Furthermore, we propose Explanation-Guided Fine-Tuning, which fine-tunes the LLM using paired vulnerable code and explanations, enabling both vulnerability detection and reasoned explanations. We evaluate explanation quality through LLM and human evaluation, focusing on Correctness, Completeness, and Conciseness. Experimental results show that Smart-LLaMA outperforms state-of-the-art baselines, with average improvements of 6.49% in F1 score and 3.78% in accuracy, while providing reliable explanations.
The high dimensional psychological profile and cultural bias of ChatGPT
May 06, 2024Given the rapid advancement of large-scale language models, artificial intelligence (AI) models, like ChatGPT, are playing an increasingly prominent role in human society. However, to ensure that artificial intelligence models benefit human society, we must first fully understand the similarities and differences between the human-like characteristics exhibited by artificial intelligence models and real humans, as well as the cultural stereotypes and biases that artificial intelligence models may exhibit in the process of interacting with humans. This study first measured ChatGPT in 84 dimensions of psychological characteristics, revealing differences between ChatGPT and human norms in most dimensions as well as in high-dimensional psychological representations. Additionally, through the measurement of ChatGPT in 13 dimensions of cultural values, it was revealed that ChatGPT's cultural value patterns are dissimilar to those of various countries/regions worldwide. Finally, an analysis of ChatGPT's performance in eight decision-making tasks involving interactions with humans from different countries/regions revealed that ChatGPT exhibits clear cultural stereotypes in most decision-making tasks and shows significant cultural bias in third-party punishment and ultimatum games. The findings indicate that, compared to humans, ChatGPT exhibits a distinct psychological profile and cultural value orientation, and it also shows cultural biases and stereotypes in interpersonal decision-making. Future research endeavors should emphasize enhanced technical oversight and augmented transparency in the database and algorithmic training procedures to foster more efficient cross-cultural communication and mitigate social disparities.
Alpha-GPT 2.0: Human-in-the-Loop AI for Quantitative Investment
Feb 15, 2024

Recently, we introduced a new paradigm for alpha mining in the realm of quantitative investment, developing a new interactive alpha mining system framework, Alpha-GPT. This system is centered on iterative Human-AI interaction based on large language models, introducing a Human-in-the-Loop approach to alpha discovery. In this paper, we present the next-generation Alpha-GPT 2.0 \footnote{Draft. Work in progress}, a quantitative investment framework that further encompasses crucial modeling and analysis phases in quantitative investment. This framework emphasizes the iterative, interactive research between humans and AI, embodying a Human-in-the-Loop strategy throughout the entire quantitative investment pipeline. By assimilating the insights of human researchers into the systematic alpha research process, we effectively leverage the Human-in-the-Loop approach, enhancing the efficiency and precision of quantitative investment research.
QuantAgent: Seeking Holy Grail in Trading by Self-Improving Large Language Model
Feb 06, 2024Autonomous agents based on Large Language Models (LLMs) that devise plans and tackle real-world challenges have gained prominence.However, tailoring these agents for specialized domains like quantitative investment remains a formidable task. The core challenge involves efficiently building and integrating a domain-specific knowledge base for the agent's learning process. This paper introduces a principled framework to address this challenge, comprising a two-layer loop.In the inner loop, the agent refines its responses by drawing from its knowledge base, while in the outer loop, these responses are tested in real-world scenarios to automatically enhance the knowledge base with new insights.We demonstrate that our approach enables the agent to progressively approximate optimal behavior with provable efficiency.Furthermore, we instantiate this framework through an autonomous agent for mining trading signals named QuantAgent. Empirical results showcase QuantAgent's capability in uncovering viable financial signals and enhancing the accuracy of financial forecasts.
Alpha-GPT: Human-AI Interactive Alpha Mining for Quantitative Investment
Jul 31, 2023



One of the most important tasks in quantitative investment research is mining new alphas (effective trading signals or factors). Traditional alpha mining methods, either hand-crafted factor synthesizing or algorithmic factor mining (e.g., search with genetic programming), have inherent limitations, especially in implementing the ideas of quants. In this work, we propose a new alpha mining paradigm by introducing human-AI interaction, and a novel prompt engineering algorithmic framework to implement this paradigm by leveraging the power of large language models. Moreover, we develop Alpha-GPT, a new interactive alpha mining system framework that provides a heuristic way to ``understand'' the ideas of quant researchers and outputs creative, insightful, and effective alphas. We demonstrate the effectiveness and advantage of Alpha-GPT via a number of alpha mining experiments.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.