 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging point annotations in segmentation learning with boundary loss
Nov 06, 2023This paper investigates the combination of intensity-based distance maps with boundary loss for point-supervised semantic segmentation. By design the boundary loss imposes a stronger penalty on the false positives the farther away from the object they occur. Hence it is intuitively inappropriate for weak supervision, where the ground truth label may be much smaller than the actual object and a certain amount of false positives (w.r.t. the weak ground truth) is actually desirable. Using intensity-aware distances instead may alleviate this drawback, allowing for a certain amount of false positives without a significant increase to the training loss. The motivation for applying the boundary loss directly under weak supervision lies in its great success for fully supervised segmentation tasks, but also in not requiring extra priors or outside information that is usually required -- in some form -- with existing weakly supervised methods in the literature. This formulation also remains potentially more attractive than existing CRF-based regularizers, due to its simplicity and computational efficiency. We perform experiments on two multi-class datasets; ACDC (heart segmentation) and POEM (whole-body abdominal organ segmentation). Preliminary results are encouraging and show that this supervision strategy has great potential. On ACDC it outperforms the CRF-loss based approach, and on POEM data it performs on par with it. The code for all our experiments is openly available.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
A Study of Augmentation Methods for Handwritten Stenography Recognition
Mar 05, 2023One of the factors limiting the performance of handwritten text recognition (HTR) for stenography is the small amount of annotated training data. To alleviate the problem of data scarcity, modern HTR methods often employ data augmentation. However, due to specifics of the stenographic script, such settings may not be directly applicable for stenography recognition. In this work, we study 22 classical augmentation techniques, most of which are commonly used for HTR of other scripts, such as Latin handwriting. Through extensive experiments, we identify a group of augmentations, including for example contained ranges of random rotation, shifts and scaling, that are beneficial to the use case of stenography recognition. Furthermore, a number of augmentation approaches, leading to a decrease in recognition performance, are identified. Our results are supported by statistical hypothesis testing. Links to the publicly available dataset and codebase are provided.
Cross-Modality Sub-Image Retrieval using Contrastive Multimodal Image Representations
Jan 10, 2022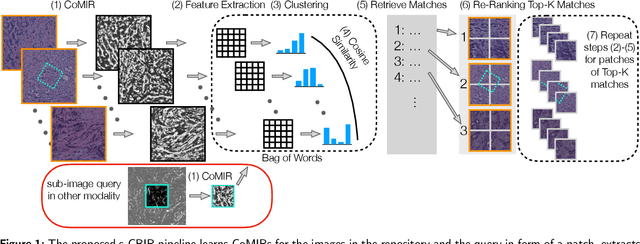
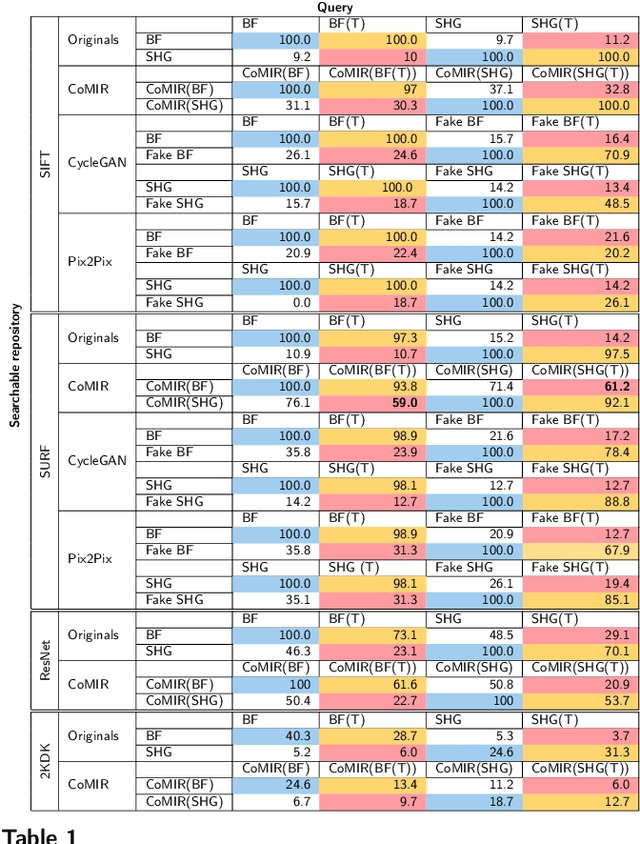
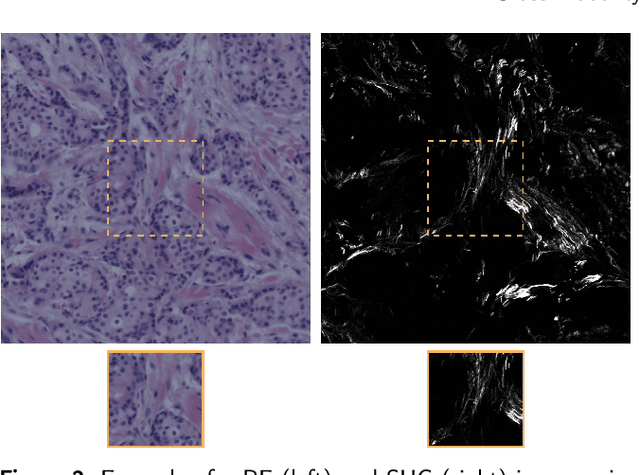

In tissue characterization and cancer diagnostics, multimodal imaging has emerged as a powerful technique. Thanks to computational advances, large datasets can be exploited to improve diagnosis and discover patterns in pathologies. However, this requires efficient and scalable image retrieval methods. Cross-modality image retrieval is particularly demanding, as images of the same content captured in different modalities may display little common information. We propose a content-based image retrieval system (CBIR) for reverse (sub-)image search to retrieve microscopy images in one modality given a corresponding image captured by a different modality, where images are not aligned and share only few structures. We propose to combine deep learning to generate representations which embed both modalities in a common space, with classic, fast, and robust feature extractors (SIFT, SURF) to create a bag-of-words model for efficient and reliable retrieval. Our application-independent approach shows promising results on a publicly available dataset of brightfield and second harmonic generation microscopy images. We obtain 75.4% and 83.6% top-10 retrieval success for retrieval in one or the other direction. Our proposed method significantly outperforms both direct retrieval of the original multimodal (sub-)images, as well as their corresponding generative adversarial network (GAN)-based image-to-image translations. We establish that the proposed method performs better in comparison with a recent sub-image retrieval toolkit, GAN-based image-to-image translations, and learnt feature extractors for the downstream task of cross-modal image retrieval. We highlight the shortcomings of the latter methods and observe the importance of equivariance and invariance properties of the learnt representations and feature extractors in the CBIR pipeline. Code will be available at github.com/MIDA-group.