 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten Stenography Recognition and the LION Dataset
Aug 15, 2023
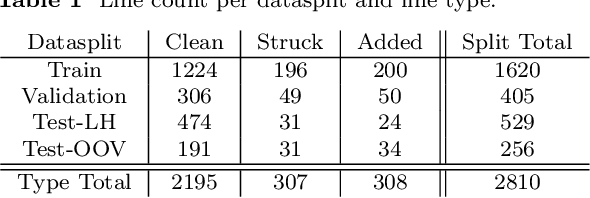

Purpose: In this paper, we establish a baseline for handwritten stenography recognition, using the novel LION dataset, and investigate the impact of including selected aspects of stenographic theory into the recognition process. We make the LION dataset publicly available with the aim of encouraging future research in handwritten stenography recognition. Methods: A state-of-the-art text recognition model is trained to establish a baseline. Stenographic domain knowledge is integrated by applying four different encoding methods that transform the target sequence into representations, which approximate selected aspects of the writing system. Results are further improved by integrating a pre-training scheme, based on synthetic data. Results: The baseline model achieves an average test character error rate (CER) of 29.81% and a word error rate (WER) of 55.14%. Test error rates are reduced significantly by combining stenography-specific target sequence encodings with pre-training and fine-tuning, yielding CERs in the range of 24.5% - 26% and WERs of 44.8% - 48.2%. Conclusion: The obtained results demonstrate the challenging nature of stenography recognition. Integrating stenography-specific knowledge, in conjunction with pre-training and fine-tuning on synthetic data, yields considerable improvements. Together with our precursor study on the subject, this is the first work to apply modern handwritten text recognition to stenography. The dataset and our code are publicly available via Zenodo.
A Study of Augmentation Methods for Handwritten Stenography Recognition
Mar 05, 2023One of the factors limiting the performance of handwritten text recognition (HTR) for stenography is the small amount of annotated training data. To alleviate the problem of data scarcity, modern HTR methods often employ data augmentation. However, due to specifics of the stenographic script, such settings may not be directly applicable for stenography recognition. In this work, we study 22 classical augmentation techniques, most of which are commonly used for HTR of other scripts, such as Latin handwriting. Through extensive experiments, we identify a group of augmentations, including for example contained ranges of random rotation, shifts and scaling, that are beneficial to the use case of stenography recognition. Furthermore, a number of augmentation approaches, leading to a decrease in recognition performance, are identified. Our results are supported by statistical hypothesis testing. Links to the publicly available dataset and codebase are provided.
Paired Image to Image Translation for Strikethrough Removal From Handwritten Words
Jan 24, 2022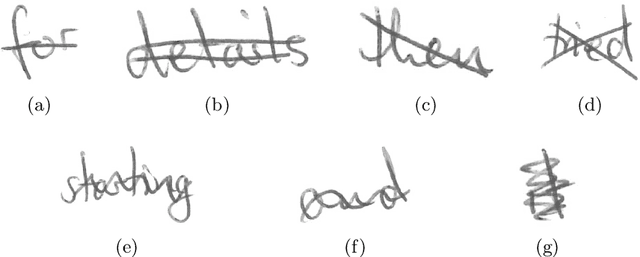
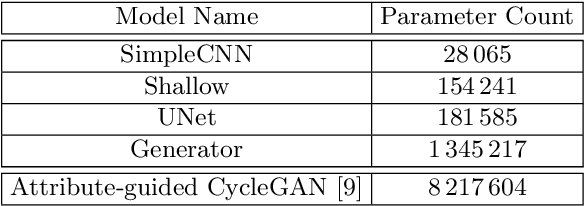
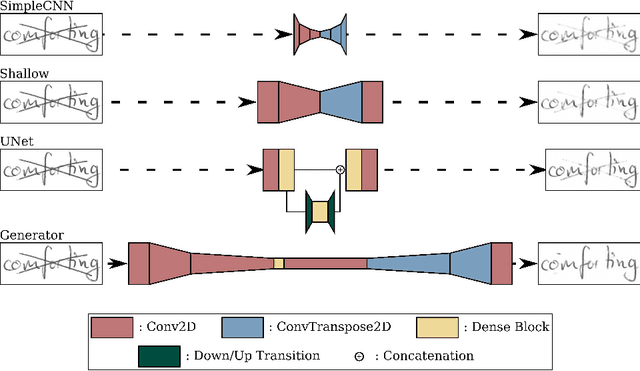

Transcribing struck-through, handwritten words, for example for the purpose of genetic criticism, can pose a challenge to both humans and machines, due to the obstructive properties of the superimposed strokes. This paper investigates the use of paired image to image translation approaches to remove strikethrough strokes from handwritten words. Four different neural network architectures are examined, ranging from a few simple convolutional layers to deeper ones, employing Dense blocks. Experimental results, obtained from one synthetic and one genuine paired strikethrough dataset, confirm that the proposed paired models outperform the CycleGAN-based state of the art, while using less than a sixth of the trainable parameters.