 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaired Image to Image Translation for Strikethrough Removal From Handwritten Words
Jan 24, 2022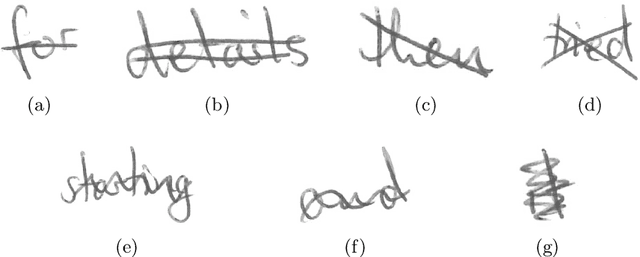
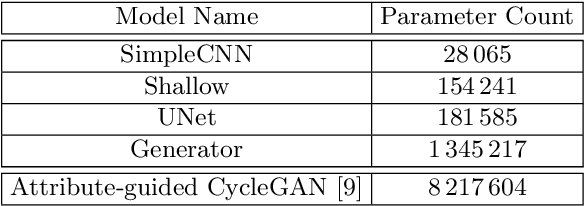
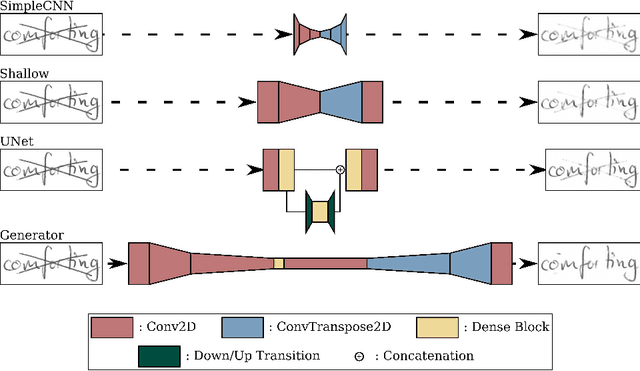

Transcribing struck-through, handwritten words, for example for the purpose of genetic criticism, can pose a challenge to both humans and machines, due to the obstructive properties of the superimposed strokes. This paper investigates the use of paired image to image translation approaches to remove strikethrough strokes from handwritten words. Four different neural network architectures are examined, ranging from a few simple convolutional layers to deeper ones, employing Dense blocks. Experimental results, obtained from one synthetic and one genuine paired strikethrough dataset, confirm that the proposed paired models outperform the CycleGAN-based state of the art, while using less than a sixth of the trainable parameters.
Radial Line Fourier Descriptor for Historical Handwritten Text Representation
Mar 20, 2018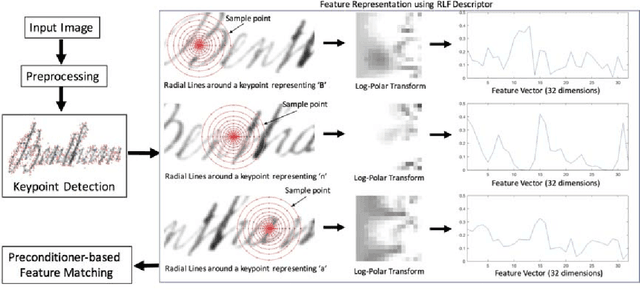
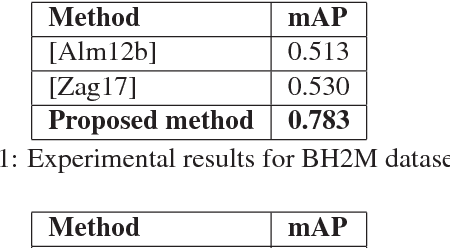

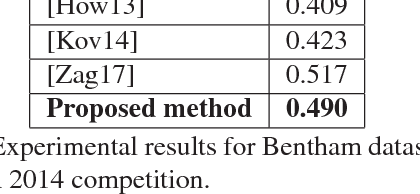
Automatic recognition of historical handwritten manuscripts is a daunting task due to paper degradation over time. Recognition-free retrieval or word spotting is popularly used for information retrieval and digitization of the historical handwritten documents. However, the performance of word spotting algorithms depends heavily on feature detection and representation methods. Although there exist popular feature descriptors such as Scale Invariant Feature Transform (SIFT) and Speeded Up Robust Features (SURF), the invariant properties of these descriptors amplify the noise in the degraded document images, rendering them more sensitive to noise and complex characteristics of historical manuscripts. Therefore, an efficient and relaxed feature descriptor is required as handwritten words across different documents are indeed similar, but not identical. This paper introduces a Radial Line Fourier (RLF) descriptor for handwritten word representation, with a short feature vector of 32 dimensions. A segmentation-free and training-free handwritten word spotting method is studied herein that relies on the proposed RLF descriptor, takes into account different keypoint representations and uses a simple preconditioner-based feature matching algorithm. The effectiveness of the RLF descriptor for segmentation-free handwritten word spotting is empirically evaluated on well-known historical handwritten datasets using standard evaluation measures.
Learning Surrogate Models of Document Image Quality Metrics for Automated Document Image Processing
Dec 11, 2017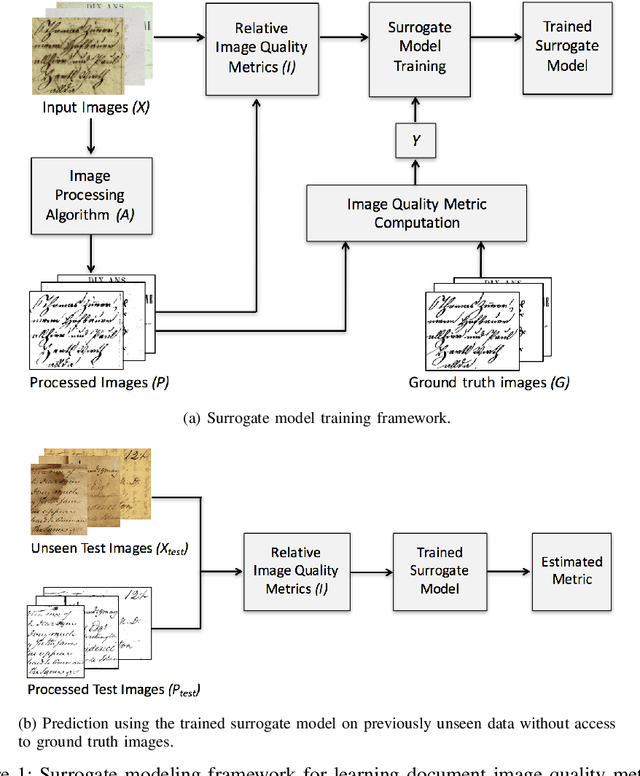
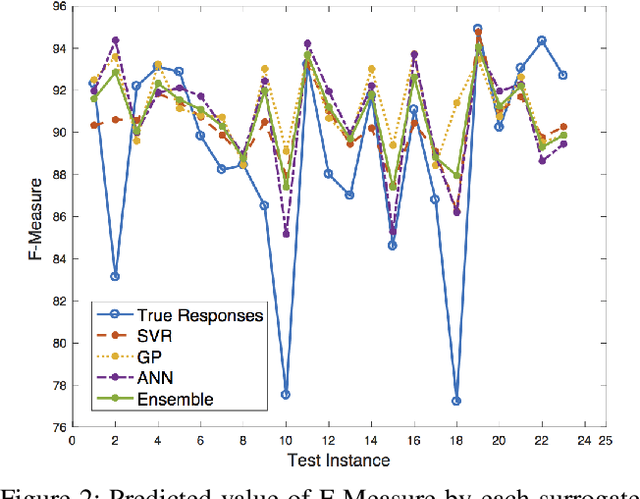


Computation of document image quality metrics often depends upon the availability of a ground truth image corresponding to the document. This limits the applicability of quality metrics in applications such as hyperparameter optimization of image processing algorithms that operate on-the-fly on unseen documents. This work proposes the use of surrogate models to learn the behavior of a given document quality metric on existing datasets where ground truth images are available. The trained surrogate model can later be used to predict the metric value on previously unseen document images without requiring access to ground truth images. The surrogate model is empirically evaluated on the Document Image Binarization Competition (DIBCO) and the Handwritten Document Image Binarization Competition (H-DIBCO) datasets.
TexT - Text Extractor Tool for Handwritten Document Transcription and Annotation
Nov 22, 2017



This paper presents a framework for semi-automatic transcription of large-scale historical handwritten documents and proposes a simple user-friendly text extractor tool, TexT for transcription. The proposed approach provides a quick and easy transcription of text using computer assisted interactive technique. The algorithm finds multiple occurrences of the marked text on-the-fly using a word spotting system. TexT is also capable of performing on-the-fly annotation of handwritten text with automatic generation of ground truth labels, and dynamic adjustment and correction of user generated bounding box annotations with the word being perfectly encapsulated. The user can view the document and the found words in the original form or with background noise removed for easier visualization of transcription results. The effectiveness of TexT is demonstrated on an archival manuscript collection from well-known publicly available dataset.
Automatic Document Image Binarization using Bayesian Optimization
Oct 21, 2017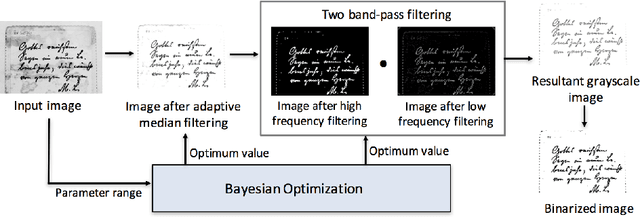


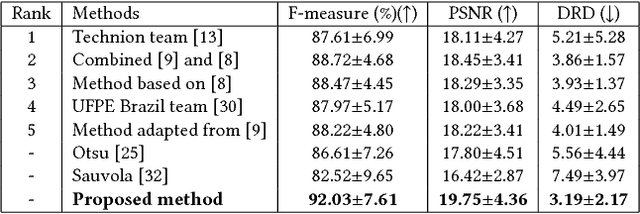
Document image binarization is often a challenging task due to various forms of degradation. Although there exist several binarization techniques in literature, the binarized image is typically sensitive to control parameter settings of the employed technique. This paper presents an automatic document image binarization algorithm to segment the text from heavily degraded document images. The proposed technique uses a two band-pass filtering approach for background noise removal, and Bayesian optimization for automatic hyperparameter selection for optimal results. The effectiveness of the proposed binarization technique is empirically demonstrated on the Document Image Binarization Competition (DIBCO) and the Handwritten Document Image Binarization Competition (H-DIBCO) datasets.