 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneFlowSBI: One Model, Many Queries for Simulation-Based Inference
Jan 30, 2026We introduce \textit{OneFlowSBI}, a unified framework for simulation-based inference that learns a single flow-matching generative model over the joint distribution of parameters and observations. Leveraging a query-aware masking distribution during training, the same model supports multiple inference tasks, including posterior sampling, likelihood estimation, and arbitrary conditional distributions, without task-specific retraining. We evaluate \textit{OneFlowSBI} on ten benchmark inference problems and two high-dimensional real-world inverse problems across multiple simulation budgets. \textit{OneFlowSBI} is shown to deliver competitive performance against state-of-the-art generalized inference solvers and specialized posterior estimators, while enabling efficient sampling with few ODE integration steps and remaining robust under noisy and partially observed data.
Exploiting the Asymmetric Uncertainty Structure of Pre-trained VLMs on the Unit Hypersphere
May 16, 2025Vision-language models (VLMs) as foundation models have significantly enhanced performance across a wide range of visual and textual tasks, without requiring large-scale training from scratch for downstream tasks. However, these deterministic VLMs fail to capture the inherent ambiguity and uncertainty in natural language and visual data. Recent probabilistic post-hoc adaptation methods address this by mapping deterministic embeddings onto probability distributions; however, existing approaches do not account for the asymmetric uncertainty structure of the modalities, and the constraint that meaningful deterministic embeddings reside on a unit hypersphere, potentially leading to suboptimal performance. In this paper, we address the asymmetric uncertainty structure inherent in textual and visual data, and propose AsymVLM to build probabilistic embeddings from pre-trained VLMs on the unit hypersphere, enabling uncertainty quantification. We validate the effectiveness of the probabilistic embeddings on established benchmarks, and present comprehensive ablation studies demonstrating the inherent nature of asymmetry in the uncertainty structure of textual and visual data.
ConDiSim: Conditional Diffusion Models for Simulation Based Inference
May 13, 2025We present a conditional diffusion model - ConDiSim, for simulation-based inference of complex systems with intractable likelihoods. ConDiSim leverages denoising diffusion probabilistic models to approximate posterior distributions, consisting of a forward process that adds Gaussian noise to parameters, and a reverse process learning to denoise, conditioned on observed data. This approach effectively captures complex dependencies and multi-modalities within posteriors. ConDiSim is evaluated across ten benchmark problems and two real-world test problems, where it demonstrates effective posterior approximation accuracy while maintaining computational efficiency and stability in model training. ConDiSim offers a robust and extensible framework for simulation-based inference, particularly suitable for parameter inference workflows requiring fast inference methods.
Bayesian Robust Aggregation for Federated Learning
May 05, 2025Federated Learning enables collaborative training of machine learning models on decentralized data. This scheme, however, is vulnerable to adversarial attacks, when some of the clients submit corrupted model updates. In real-world scenarios, the total number of compromised clients is typically unknown, with the extent of attacks potentially varying over time. To address these challenges, we propose an adaptive approach for robust aggregation of model updates based on Bayesian inference. The mean update is defined by the maximum of the likelihood marginalized over probabilities of each client to be `honest'. As a result, the method shares the simplicity of the classical average estimators (e.g., sample mean or geometric median), being independent of the number of compromised clients. At the same time, it is as effective against attacks as methods specifically tailored to Federated Learning, such as Krum. We compare our approach with other aggregation schemes in federated setting on three benchmark image classification data sets. The proposed method consistently achieves state-of-the-art performance across various attack types with static and varying number of malicious clients.
Interpretable machine learning-guided design of Fe-based soft magnetic alloys
Apr 28, 2025We present a machine-learning guided approach to predict saturation magnetization (MS) and coercivity (HC) in Fe-rich soft magnetic alloys, particularly Fe-Si-B systems. ML models trained on experimental data reveals that increasing Si and B content reduces MS from 1.81T (DFT~2.04 T) to ~1.54 T (DFT~1.56T) in Fe-Si-B, which is attributed to decreased magnetic density and structural modifications. Experimental validation of ML predicted magnetic saturation on Fe-1Si-1B (2.09T), Fe-5Si-5B (2.01T) and Fe-10Si-10B (1.54T) alloy compositions further support our findings. These trends are consistent with density functional theory (DFT) predictions, which link increased electronic disorder and band broadening to lower MS values. Experimental validation on selected alloys confirms the predictive accuracy of the ML model, with good agreement across compositions. Beyond predictive accuracy, detailed uncertainty quantification and model interpretability including through feature importance and partial dependence analysis reveals that MS is governed by a nonlinear interplay between Fe content, early transition metal ratios, and annealing temperature, while HC is more sensitive to processing conditions such as ribbon thickness and thermal treatment windows. The ML framework was further applied to Fe-Si-B/Cr/Cu/Zr/Nb alloys in a pseudo-quaternary compositional space, which shows comparable magnetic properties to NANOMET (Fe84.8Si0.5B9.4Cu0.8 P3.5C1), FINEMET (Fe73.5Si13.5B9 Cu1Nb3), NANOPERM (Fe88Zr7B4Cu1), and HITPERM (Fe44Co44Zr7B4Cu1. Our fundings demonstrate the potential of ML framework for accelerated search of high-performance, Co- and Ni-free, soft magnetic materials.
PARIC: Probabilistic Attention Regularization for Language Guided Image Classification from Pre-trained Vison Language Models
Mar 14, 2025



Language-guided attention frameworks have significantly enhanced both interpretability and performance in image classification; however, the reliance on deterministic embeddings from pre-trained vision-language foundation models to generate reference attention maps frequently overlooks the intrinsic multivaluedness and ill-posed characteristics of cross-modal mappings. To address these limitations, we introduce PARIC, a probabilistic framework for guiding visual attention via language specifications. Our approach enables pre-trained vision-language models to generate probabilistic reference attention maps, which align textual and visual modalities more effectively while incorporating uncertainty estimates, as compared to their deterministic counterparts. Experiments on benchmark test problems demonstrate that PARIC enhances prediction accuracy, mitigates bias, ensures consistent predictions, and improves robustness across various datasets.
Machine learning driven search of hydrogen storage materials
Mar 06, 2025
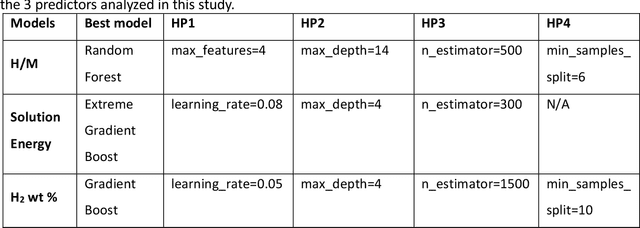
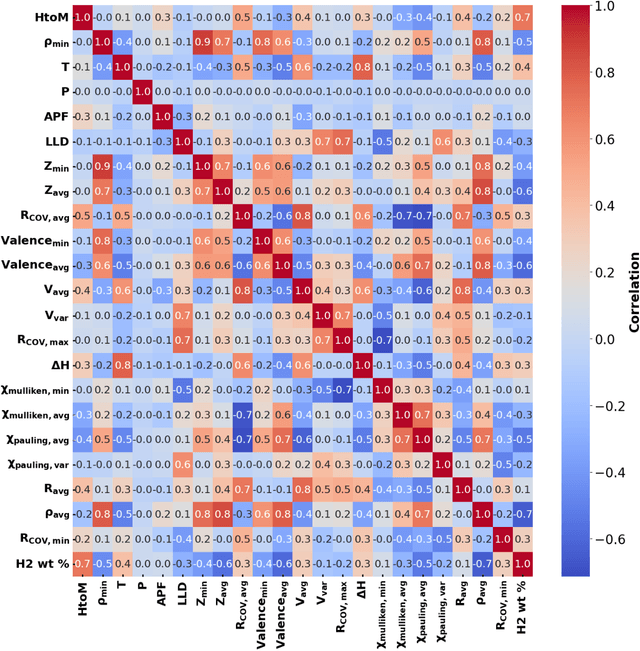

The transition to a low-carbon economy demands efficient and sustainable energy-storage solutions, with hydrogen emerging as a promising clean-energy carrier and with metal hydrides recognized for their hydrogen-storage capacity. Here, we leverage machine learning (ML) to predict hydrogen-to-metal (H/M) ratios and solution energy by incorporating thermodynamic parameters and local lattice distortion (LLD) as key features. Our best-performing ML model provides improvements to H/M ratios and solution energies over a broad class of ternary alloys (easily extendable to multi-principal-element alloys), such as Ti-Nb-X (X = Mo, Cr, Hf, Ta, V, Zr) and Co-Ni-X (X = Al, Mg, V). Ti-Nb-Mo alloys reveal compositional effects in H-storage behavior, in particular Ti, Nb, and V enhance H-storage capacity, while Mo reduces H/M and hydrogen weight percent by 40-50%. We attributed to slow hydrogen kinetics in molybdenum rich alloys, which is validated by our pressure-composition isotherm (PCT) experiments on pure Ti and Ti5Mo95 alloys. Density functional theory (DFT) and molecular simulations also confirm that Ti and Nb promote H diffusion, whereas Mo hinders it, highlighting the interplay between electronic structure, lattice distortions, and hydrogen uptake. Notably, our Gradient Boosting Regression model identifies LLD as a critical factor in H/M predictions. To aid material selection, we present two periodic tables illustrating elemental effects on (a) H2 wt% and (b) solution energy, derived from ML, and provide a reference for identifying alloying elements that enhance hydrogen solubility and storage.
$\texttt{InfoHier}$: Hierarchical Information Extraction via Encoding and Embedding
Jan 15, 2025



Analyzing large-scale datasets, especially involving complex and high-dimensional data like images, is particularly challenging. While self-supervised learning (SSL) has proven effective for learning representations from unlabelled data, it typically focuses on flat, non-hierarchical structures, missing the multi-level relationships present in many real-world datasets. Hierarchical clustering (HC) can uncover these relationships by organizing data into a tree-like structure, but it often relies on rigid similarity metrics that struggle to capture the complexity of diverse data types. To address these we envision $\texttt{InfoHier}$, a framework that combines SSL with HC to jointly learn robust latent representations and hierarchical structures. This approach leverages SSL to provide adaptive representations, enhancing HC's ability to capture complex patterns. Simultaneously, it integrates HC loss to refine SSL training, resulting in representations that are more attuned to the underlying information hierarchy. $\texttt{InfoHier}$ has the potential to improve the expressiveness and performance of both clustering and representation learning, offering significant benefits for data analysis, management, and information retrieval.
Variational Autoencoders for Efficient Simulation-Based Inference
Nov 21, 2024



We present a generative modeling approach based on the variational inference framework for likelihood-free simulation-based inference. The method leverages latent variables within variational autoencoders to efficiently estimate complex posterior distributions arising from stochastic simulations. We explore two variations of this approach distinguished by their treatment of the prior distribution. The first model adapts the prior based on observed data using a multivariate prior network, enhancing generalization across various posterior queries. In contrast, the second model utilizes a standard Gaussian prior, offering simplicity while still effectively capturing complex posterior distributions. We demonstrate the efficacy of these models on well-established benchmark problems, achieving results comparable to flow-based approaches while maintaining computational efficiency and scalability.
Efficient Resource Scheduling for Distributed Infrastructures Using Negotiation Capabilities
Feb 13, 2024In the past few decades, the rapid development of information and internet technologies has spawned massive amounts of data and information. The information explosion drives many enterprises or individuals to seek to rent cloud computing infrastructure to put their applications in the cloud. However, the agreements reached between cloud computing providers and clients are often not efficient. Many factors affect the efficiency, such as the idleness of the providers' cloud computing infrastructure, and the additional cost to the clients. One possible solution is to introduce a comprehensive, bargaining game (a type of negotiation), and schedule resources according to the negotiation results. We propose an agent-based auto-negotiation system for resource scheduling based on fuzzy logic. The proposed method can complete a one-to-one auto-negotiation process and generate optimal offers for the provider and client. We compare the impact of different member functions, fuzzy rule sets, and negotiation scenario cases on the offers to optimize the system. It can be concluded that our proposed method can utilize resources more efficiently and is interpretable, highly flexible, and customizable. We successfully train machine learning models to replace the fuzzy negotiation system to improve processing speed. The article also highlights possible future improvements to the proposed system and machine learning models. All the codes and data are available in the open-source repository.