 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGBoost: Efficient Retrieval-Augmented Generation with Accuracy-Preserving Context Reuse
Nov 05, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with retrieved context but often suffers from downgraded prefill performance as modern applications demand longer and more complex inputs. Existing caching techniques either preserve accuracy with low cache reuse or improve reuse at the cost of degraded reasoning quality. We present RAGBoost, an efficient RAG system that achieves high cache reuse without sacrificing accuracy through accuracy-preserving context reuse. RAGBoost detects overlapping retrieved items across concurrent sessions and multi-turn interactions, using efficient context indexing, ordering, and de-duplication to maximize reuse, while lightweight contextual hints maintain reasoning fidelity. It integrates seamlessly with existing LLM inference engines and improves their prefill performance by 1.5-3X over state-of-the-art methods, while preserving or even enhancing reasoning accuracy across diverse RAG and agentic AI workloads. Our code is released at: https://github.com/Edinburgh-AgenticAI/RAGBoost.
A Survey of Graph Neural Networks for Drug Discovery: Recent Developments and Challenges
Sep 09, 2025Graph Neural Networks (GNNs) have gained traction in the complex domain of drug discovery because of their ability to process graph-structured data such as drug molecule models. This approach has resulted in a myriad of methods and models in published literature across several categories of drug discovery research. This paper covers the research categories comprehensively with recent papers, namely molecular property prediction, including drug-target binding affinity prediction, drug-drug interaction study, microbiome interaction prediction, drug repositioning, retrosynthesis, and new drug design, and provides guidance for future work on GNNs for drug discovery.
Privacy-Preserving Synthetic Review Generation with Diverse Writing Styles Using LLMs
Jul 24, 2025The increasing use of synthetic data generated by Large Language Models (LLMs) presents both opportunities and challenges in data-driven applications. While synthetic data provides a cost-effective, scalable alternative to real-world data to facilitate model training, its diversity and privacy risks remain underexplored. Focusing on text-based synthetic data, we propose a comprehensive set of metrics to quantitatively assess the diversity (i.e., linguistic expression, sentiment, and user perspective), and privacy (i.e., re-identification risk and stylistic outliers) of synthetic datasets generated by several state-of-the-art LLMs. Experiment results reveal significant limitations in LLMs' capabilities in generating diverse and privacy-preserving synthetic data. Guided by the evaluation results, a prompt-based approach is proposed to enhance the diversity of synthetic reviews while preserving reviewer privacy.
LLMs are Frequency Pattern Learners in Natural Language Inference
May 27, 2025



While fine-tuning LLMs on NLI corpora improves their inferential performance, the underlying mechanisms driving this improvement remain largely opaque. In this work, we conduct a series of experiments to investigate what LLMs actually learn during fine-tuning. We begin by analyzing predicate frequencies in premises and hypotheses across NLI datasets and identify a consistent frequency bias, where predicates in hypotheses occur more frequently than those in premises for positive instances. To assess the impact of this bias, we evaluate both standard and NLI fine-tuned LLMs on bias-consistent and bias-adversarial cases. We find that LLMs exploit frequency bias for inference and perform poorly on adversarial instances. Furthermore, fine-tuned LLMs exhibit significantly increased reliance on this bias, suggesting that they are learning these frequency patterns from datasets. Finally, we compute the frequencies of hyponyms and their corresponding hypernyms from WordNet, revealing a correlation between frequency bias and textual entailment. These findings help explain why learning frequency patterns can enhance model performance on inference tasks.
S2LPP: Small-to-Large Prompt Prediction across LLMs
May 26, 2025



The performance of pre-trained Large Language Models (LLMs) is often sensitive to nuances in prompt templates, requiring careful prompt engineering, adding costs in terms of computing and human effort. In this study, we present experiments encompassing multiple LLMs variants of varying sizes aimed at probing their preference with different prompts. Through experiments on Question Answering, we show prompt preference consistency across LLMs of different sizes. We also show that this consistency extends to other tasks, such as Natural Language Inference. Utilizing this consistency, we propose a method to use a smaller model to select effective prompt templates for a larger model. We show that our method substantially reduces the cost of prompt engineering while consistently matching performance with optimal prompts among candidates. More importantly, our experiment shows the efficacy of our strategy across fourteen LLMs and its applicability to a broad range of NLP tasks, highlighting its robustness
MMLongBench: Benchmarking Long-Context Vision-Language Models Effectively and Thoroughly
May 15, 2025The rapid extension of context windows in large vision-language models has given rise to long-context vision-language models (LCVLMs), which are capable of handling hundreds of images with interleaved text tokens in a single forward pass. In this work, we introduce MMLongBench, the first benchmark covering a diverse set of long-context vision-language tasks, to evaluate LCVLMs effectively and thoroughly. MMLongBench is composed of 13,331 examples spanning five different categories of downstream tasks, such as Visual RAG and Many-Shot ICL. It also provides broad coverage of image types, including various natural and synthetic images. To assess the robustness of the models to different input lengths, all examples are delivered at five standardized input lengths (8K-128K tokens) via a cross-modal tokenization scheme that combines vision patches and text tokens. Through a thorough benchmarking of 46 closed-source and open-source LCVLMs, we provide a comprehensive analysis of the current models' vision-language long-context ability. Our results show that: i) performance on a single task is a weak proxy for overall long-context capability; ii) both closed-source and open-source models face challenges in long-context vision-language tasks, indicating substantial room for future improvement; iii) models with stronger reasoning ability tend to exhibit better long-context performance. By offering wide task coverage, various image types, and rigorous length control, MMLongBench provides the missing foundation for diagnosing and advancing the next generation of LCVLMs.
Neutralizing Bias in LLM Reasoning using Entailment Graphs
Mar 14, 2025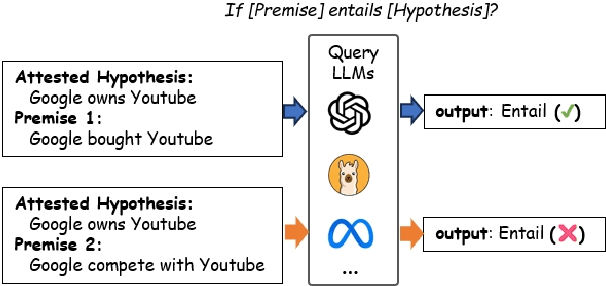


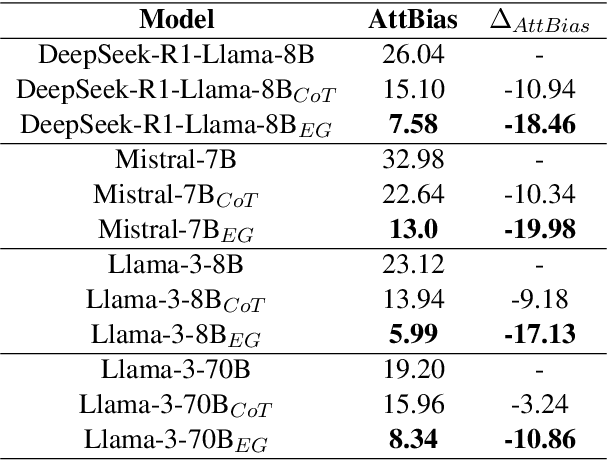
LLMs are often claimed to be capable of Natural Language Inference (NLI), which is widely regarded as a cornerstone of more complex forms of reasoning. However, recent works show that LLMs still suffer from hallucinations in NLI due to attestation bias, where LLMs overly rely on propositional memory to build shortcuts. To solve the issue, we design an unsupervised framework to construct counterfactual reasoning data and fine-tune LLMs to reduce attestation bias. To measure bias reduction, we build bias-adversarial variants of NLI datasets with randomly replaced predicates in premises while keeping hypotheses unchanged. Extensive evaluations show that our framework can significantly reduce hallucinations from attestation bias. Then, we further evaluate LLMs fine-tuned with our framework on original NLI datasets and their bias-neutralized versions, where original entities are replaced with randomly sampled ones. Extensive results show that our framework consistently improves inferential performance on both original and bias-neutralized NLI datasets.
Pathologist-like explainable AI for interpretable Gleason grading in prostate cancer
Oct 19, 2024



The aggressiveness of prostate cancer, the most common cancer in men worldwide, is primarily assessed based on histopathological data using the Gleason scoring system. While artificial intelligence (AI) has shown promise in accurately predicting Gleason scores, these predictions often lack inherent explainability, potentially leading to distrust in human-machine interactions. To address this issue, we introduce a novel dataset of 1,015 tissue microarray core images, annotated by an international group of 54 pathologists. The annotations provide detailed localized pattern descriptions for Gleason grading in line with international guidelines. Utilizing this dataset, we develop an inherently explainable AI system based on a U-Net architecture that provides predictions leveraging pathologists' terminology. This approach circumvents post-hoc explainability methods while maintaining or exceeding the performance of methods trained directly for Gleason pattern segmentation (Dice score: 0.713 $\pm$ 0.003 trained on explanations vs. 0.691 $\pm$ 0.010 trained on Gleason patterns). By employing soft labels during training, we capture the intrinsic uncertainty in the data, yielding strong results in Gleason pattern segmentation even in the context of high interobserver variability. With the release of this dataset, we aim to encourage further research into segmentation in medical tasks with high levels of subjectivity and to advance the understanding of pathologists' reasoning processes.
Explicit Inductive Inference using Large Language Models
Aug 26, 2024



Large Language Models (LLMs) are reported to hold undesirable attestation bias on inference tasks: when asked to predict if a premise P entails a hypothesis H, instead of considering H's conditional truthfulness entailed by P, LLMs tend to use the out-of-context truth label of H as a fragile proxy. In this paper, we propose a pipeline that exploits this bias to do explicit inductive inference. Our pipeline uses an LLM to transform a premise into a set of attested alternatives, and then aggregate answers of the derived new entailment inquiries to support the original inference prediction. On a directional predicate entailment benchmark, we demonstrate that by applying this simple pipeline, we can improve the overall performance of LLMs on inference and substantially alleviate the impact of their attestation bias.
Variational autoencoder-based neural network model compression
Aug 25, 2024



Variational Autoencoders (VAEs), as a form of deep generative model, have been widely used in recent years, and shown great great peformance in a number of different domains, including image generation and anomaly detection, etc.. This paper aims to explore neural network model compression method based on VAE. The experiment uses different neural network models for MNIST recognition as compression targets, including Feedforward Neural Network (FNN), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM). These models are the most basic models in deep learning, and other more complex and advanced models are based on them or inherit their features and evolve. In the experiment, the first step is to train the models mentioned above, each trained model will have different accuracy and number of total parameters. And then the variants of parameters for each model are processed as training data in VAEs separately, and the trained VAEs are tested by the true model parameters. The experimental results show that using the latent space as a representation of the model compression can improve the compression rate compared to some traditional methods such as pruning and quantization, meanwhile the accuracy is not greatly affected using the model parameters reconstructed based on the latent space. In the future, a variety of different large-scale deep learning models will be used more widely, so exploring different ways to save time and space on saving or transferring models will become necessary, and the use of VAE in this paper can provide a basis for these further explorations.