 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Catastrophic Forgetting in IoT Intrusion Detection Systems
Feb 27, 2026Distribution shifts in attack patterns within RPL-based IoT networks pose a critical threat to the reliability and security of large-scale connected systems. Intrusion Detection Systems (IDS) trained on static datasets often fail to generalize to unseen threats and suffer from catastrophic forgetting when updated with new attacks. Ensuring continual adaptability of IDS is therefore essential for maintaining robust IoT network defence. In this focused study, we formulate intrusion detection as a domain continual learning problem and propose a method-agnostic IDS framework that can integrate diverse continual learning strategies. We systematically benchmark five representative approaches across multiple domain-ordering sequences using a comprehensive multi-attack dataset comprising 48 domains. Results show that continual learning mitigates catastrophic forgetting while maintaining a balance between plasticity, stability, and efficiency, a crucial aspect for resource-constrained IoT environments. Among the methods, Replay-based approaches achieve the best overall performance, while Synaptic Intelligence (SI) delivers near-zero forgetting with high training efficiency, demonstrating strong potential for stable and sustainable IDS deployment in dynamic IoT networks.
From Research to Reality: Feasibility of Gradient Inversion Attacks in Federated Learning
Aug 27, 2025Gradient inversion attacks have garnered attention for their ability to compromise privacy in federated learning. However, many studies consider attacks with the model in inference mode, where training-time behaviors like dropout are disabled and batch normalization relies on fixed statistics. In this work, we systematically analyze how architecture and training behavior affect vulnerability, including the first in-depth study of inference-mode clients, which we show dramatically simplifies inversion. To assess attack feasibility under more realistic conditions, we turn to clients operating in standard training mode. In this setting, we find that successful attacks are only possible when several architectural conditions are met simultaneously: models must be shallow and wide, use skip connections, and, critically, employ pre-activation normalization. We introduce two novel attacks against models in training-mode with varying attacker knowledge, achieving state-of-the-art performance under realistic training conditions. We extend these efforts by presenting the first attack on a production-grade object-detection model. Here, to enable any visibly identifiable leakage, we revert to the lenient inference mode setting and make multiple architectural modifications to increase model vulnerability, with the extent of required changes highlighting the strong inherent robustness of such architectures. We conclude this work by offering the first comprehensive mapping of settings, clarifying which combinations of architectural choices and operational modes meaningfully impact privacy. Our analysis provides actionable insight into when models are likely vulnerable, when they appear robust, and where subtle leakage may persist. Together, these findings reframe how gradient inversion risk should be assessed in future research and deployment scenarios.
Bayesian Robust Aggregation for Federated Learning
May 05, 2025Federated Learning enables collaborative training of machine learning models on decentralized data. This scheme, however, is vulnerable to adversarial attacks, when some of the clients submit corrupted model updates. In real-world scenarios, the total number of compromised clients is typically unknown, with the extent of attacks potentially varying over time. To address these challenges, we propose an adaptive approach for robust aggregation of model updates based on Bayesian inference. The mean update is defined by the maximum of the likelihood marginalized over probabilities of each client to be `honest'. As a result, the method shares the simplicity of the classical average estimators (e.g., sample mean or geometric median), being independent of the number of compromised clients. At the same time, it is as effective against attacks as methods specifically tailored to Federated Learning, such as Krum. We compare our approach with other aggregation schemes in federated setting on three benchmark image classification data sets. The proposed method consistently achieves state-of-the-art performance across various attack types with static and varying number of malicious clients.
Robust Federated Learning Against Poisoning Attacks: A GAN-Based Defense Framework
Mar 26, 2025


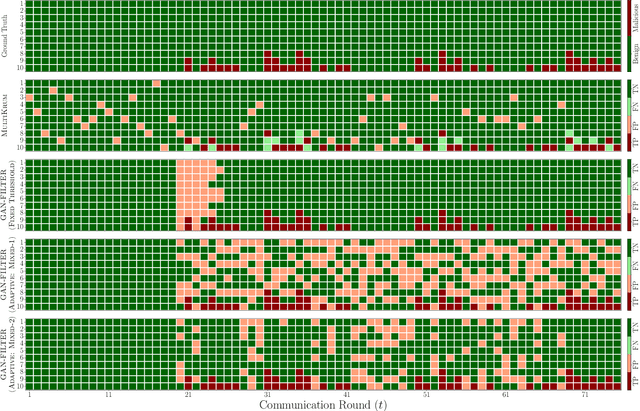
Federated Learning (FL) enables collaborative model training across decentralized devices without sharing raw data, but it remains vulnerable to poisoning attacks that compromise model integrity. Existing defenses often rely on external datasets or predefined heuristics (e.g. number of malicious clients), limiting their effectiveness and scalability. To address these limitations, we propose a privacy-preserving defense framework that leverages a Conditional Generative Adversarial Network (cGAN) to generate synthetic data at the server for authenticating client updates, eliminating the need for external datasets. Our framework is scalable, adaptive, and seamlessly integrates into FL workflows. Extensive experiments on benchmark datasets demonstrate its robust performance against a variety of poisoning attacks, achieving high True Positive Rate (TPR) and True Negative Rate (TNR) of malicious and benign clients, respectively, while maintaining model accuracy. The proposed framework offers a practical and effective solution for securing federated learning systems.
$\texttt{InfoHier}$: Hierarchical Information Extraction via Encoding and Embedding
Jan 15, 2025



Analyzing large-scale datasets, especially involving complex and high-dimensional data like images, is particularly challenging. While self-supervised learning (SSL) has proven effective for learning representations from unlabelled data, it typically focuses on flat, non-hierarchical structures, missing the multi-level relationships present in many real-world datasets. Hierarchical clustering (HC) can uncover these relationships by organizing data into a tree-like structure, but it often relies on rigid similarity metrics that struggle to capture the complexity of diverse data types. To address these we envision $\texttt{InfoHier}$, a framework that combines SSL with HC to jointly learn robust latent representations and hierarchical structures. This approach leverages SSL to provide adaptive representations, enhancing HC's ability to capture complex patterns. Simultaneously, it integrates HC loss to refine SSL training, resulting in representations that are more attuned to the underlying information hierarchy. $\texttt{InfoHier}$ has the potential to improve the expressiveness and performance of both clustering and representation learning, offering significant benefits for data analysis, management, and information retrieval.
Empowering Data Mesh with Federated Learning
Mar 27, 2024The evolution of data architecture has seen the rise of data lakes, aiming to solve the bottlenecks of data management and promote intelligent decision-making. However, this centralized architecture is limited by the proliferation of data sources and the growing demand for timely analysis and processing. A new data paradigm, Data Mesh, is proposed to overcome these challenges. Data Mesh treats domains as a first-class concern by distributing the data ownership from the central team to each data domain, while keeping the federated governance to monitor domains and their data products. Many multi-million dollar organizations like Paypal, Netflix, and Zalando have already transformed their data analysis pipelines based on this new architecture. In this decentralized architecture where data is locally preserved by each domain team, traditional centralized machine learning is incapable of conducting effective analysis across multiple domains, especially for security-sensitive organizations. To this end, we introduce a pioneering approach that incorporates Federated Learning into Data Mesh. To the best of our knowledge, this is the first open-source applied work that represents a critical advancement toward the integration of federated learning methods into the Data Mesh paradigm, underscoring the promising prospects for privacy-preserving and decentralized data analysis strategies within Data Mesh architecture.
Efficient Resource Scheduling for Distributed Infrastructures Using Negotiation Capabilities
Feb 13, 2024In the past few decades, the rapid development of information and internet technologies has spawned massive amounts of data and information. The information explosion drives many enterprises or individuals to seek to rent cloud computing infrastructure to put their applications in the cloud. However, the agreements reached between cloud computing providers and clients are often not efficient. Many factors affect the efficiency, such as the idleness of the providers' cloud computing infrastructure, and the additional cost to the clients. One possible solution is to introduce a comprehensive, bargaining game (a type of negotiation), and schedule resources according to the negotiation results. We propose an agent-based auto-negotiation system for resource scheduling based on fuzzy logic. The proposed method can complete a one-to-one auto-negotiation process and generate optimal offers for the provider and client. We compare the impact of different member functions, fuzzy rule sets, and negotiation scenario cases on the offers to optimize the system. It can be concluded that our proposed method can utilize resources more efficiently and is interpretable, highly flexible, and customizable. We successfully train machine learning models to replace the fuzzy negotiation system to improve processing speed. The article also highlights possible future improvements to the proposed system and machine learning models. All the codes and data are available in the open-source repository.
Toward efficient resource utilization at edge nodes in federated learning
Sep 19, 2023Federated learning (FL) enables edge nodes to collaboratively contribute to constructing a global model without sharing their data. This is accomplished by devices computing local, private model updates that are then aggregated by a server. However, computational resource constraints and network communication can become a severe bottleneck for larger model sizes typical for deep learning applications. Edge nodes tend to have limited hardware resources (RAM, CPU), and the network bandwidth and reliability at the edge is a concern for scaling federated fleet applications. In this paper, we propose and evaluate a FL strategy inspired by transfer learning in order to reduce resource utilization on devices, as well as the load on the server and network in each global training round. For each local model update, we randomly select layers to train, freezing the remaining part of the model. In doing so, we can reduce both server load and communication costs per round by excluding all untrained layer weights from being transferred to the server. The goal of this study is to empirically explore the potential trade-off between resource utilization on devices and global model convergence under the proposed strategy. We implement the approach using the federated learning framework FEDn. A number of experiments were carried out over different datasets (CIFAR-10, CASA, and IMDB), performing different tasks using different deep-learning model architectures. Our results show that training the model partially can accelerate the training process, efficiently utilizes resources on-device, and reduce the data transmission by around 75% and 53% when we train 25%, and 50% of the model layers, respectively, without harming the resulting global model accuracy.
FedBot: Enhancing Privacy in Chatbots with Federated Learning
Apr 04, 2023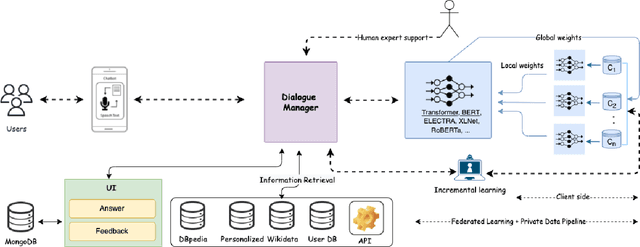

Chatbots are mainly data-driven and usually based on utterances that might be sensitive. However, training deep learning models on shared data can violate user privacy. Such issues have commonly existed in chatbots since their inception. In the literature, there have been many approaches to deal with privacy, such as differential privacy and secure multi-party computation, but most of them need to have access to users' data. In this context, Federated Learning (FL) aims to protect data privacy through distributed learning methods that keep the data in its location. This paper presents Fedbot, a proof-of-concept (POC) privacy-preserving chatbot that leverages large-scale customer support data. The POC combines Deep Bidirectional Transformer models and federated learning algorithms to protect customer data privacy during collaborative model training. The results of the proof-of-concept showcase the potential for privacy-preserving chatbots to transform the customer support industry by delivering personalized and efficient customer service that meets data privacy regulations and legal requirements. Furthermore, the system is specifically designed to improve its performance and accuracy over time by leveraging its ability to learn from previous interactions.
Accelerating Fair Federated Learning: Adaptive Federated Adam
Jan 23, 2023



Federated learning is a distributed and privacy-preserving approach to train a statistical model collaboratively from decentralized data of different parties. However, when datasets of participants are not independent and identically distributed (non-IID), models trained by naive federated algorithms may be biased towards certain participants, and model performance across participants is non-uniform. This is known as the fairness problem in federated learning. In this paper, we formulate fairness-controlled federated learning as a dynamical multi-objective optimization problem to ensure fair performance across all participants. To solve the problem efficiently, we study the convergence and bias of Adam as the server optimizer in federated learning, and propose Adaptive Federated Adam (AdaFedAdam) to accelerate fair federated learning with alleviated bias. We validated the effectiveness, Pareto optimality and robustness of AdaFedAdam in numerical experiments and show that AdaFedAdam outperforms existing algorithms, providing better convergence and fairness properties of the federated scheme.