 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Risks in Time Series Forecasting: User- and Record-Level Membership Inference
Sep 04, 2025Membership inference attacks (MIAs) aim to determine whether specific data were used to train a model. While extensively studied on classification models, their impact on time series forecasting remains largely unexplored. We address this gap by introducing two new attacks: (i) an adaptation of multivariate LiRA, a state-of-the-art MIA originally developed for classification models, to the time-series forecasting setting, and (ii) a novel end-to-end learning approach called Deep Time Series (DTS) attack. We benchmark these methods against adapted versions of other leading attacks from the classification setting. We evaluate all attacks in realistic settings on the TUH-EEG and ELD datasets, targeting two strong forecasting architectures, LSTM and the state-of-the-art N-HiTS, under both record- and user-level threat models. Our results show that forecasting models are vulnerable, with user-level attacks often achieving perfect detection. The proposed methods achieve the strongest performance in several settings, establishing new baselines for privacy risk assessment in time series forecasting. Furthermore, vulnerability increases with longer prediction horizons and smaller training populations, echoing trends observed in large language models.
From Research to Reality: Feasibility of Gradient Inversion Attacks in Federated Learning
Aug 27, 2025Gradient inversion attacks have garnered attention for their ability to compromise privacy in federated learning. However, many studies consider attacks with the model in inference mode, where training-time behaviors like dropout are disabled and batch normalization relies on fixed statistics. In this work, we systematically analyze how architecture and training behavior affect vulnerability, including the first in-depth study of inference-mode clients, which we show dramatically simplifies inversion. To assess attack feasibility under more realistic conditions, we turn to clients operating in standard training mode. In this setting, we find that successful attacks are only possible when several architectural conditions are met simultaneously: models must be shallow and wide, use skip connections, and, critically, employ pre-activation normalization. We introduce two novel attacks against models in training-mode with varying attacker knowledge, achieving state-of-the-art performance under realistic training conditions. We extend these efforts by presenting the first attack on a production-grade object-detection model. Here, to enable any visibly identifiable leakage, we revert to the lenient inference mode setting and make multiple architectural modifications to increase model vulnerability, with the extent of required changes highlighting the strong inherent robustness of such architectures. We conclude this work by offering the first comprehensive mapping of settings, clarifying which combinations of architectural choices and operational modes meaningfully impact privacy. Our analysis provides actionable insight into when models are likely vulnerable, when they appear robust, and where subtle leakage may persist. Together, these findings reframe how gradient inversion risk should be assessed in future research and deployment scenarios.
Practical Bayes-Optimal Membership Inference Attacks
May 30, 2025We develop practical and theoretically grounded membership inference attacks (MIAs) against both independent and identically distributed (i.i.d.) data and graph-structured data. Building on the Bayesian decision-theoretic framework of Sablayrolles et al., we derive the Bayes-optimal membership inference rule for node-level MIAs against graph neural networks, addressing key open questions about optimal query strategies in the graph setting. We introduce BASE and G-BASE, computationally efficient approximations of the Bayes-optimal attack. G-BASE achieves superior performance compared to previously proposed classifier-based node-level MIA attacks. BASE, which is also applicable to non-graph data, matches or exceeds the performance of prior state-of-the-art MIAs, such as LiRA and RMIA, at a significantly lower computational cost. Finally, we show that BASE and RMIA are equivalent under a specific hyperparameter setting, providing a principled, Bayes-optimal justification for the RMIA attack.
Publishing Neural Networks in Drug Discovery Might Compromise Training Data Privacy
Oct 22, 2024



This study investigates the risks of exposing confidential chemical structures when machine learning models trained on these structures are made publicly available. We use membership inference attacks, a common method to assess privacy that is largely unexplored in the context of drug discovery, to examine neural networks for molecular property prediction in a black-box setting. Our results reveal significant privacy risks across all evaluated datasets and neural network architectures. Combining multiple attacks increases these risks. Molecules from minority classes, often the most valuable in drug discovery, are particularly vulnerable. We also found that representing molecules as graphs and using message-passing neural networks may mitigate these risks. We provide a framework to assess privacy risks of classification models and molecular representations. Our findings highlight the need for careful consideration when sharing neural networks trained on proprietary chemical structures, informing organisations and researchers about the trade-offs between data confidentiality and model openness.
Towards Holistic Disease Risk Prediction using Small Language Models
Aug 13, 2024Data in the healthcare domain arise from a variety of sources and modalities, such as x-ray images, continuous measurements, and clinical notes. Medical practitioners integrate these diverse data types daily to make informed and accurate decisions. With recent advancements in language models capable of handling multimodal data, it is a logical progression to apply these models to the healthcare sector. In this work, we introduce a framework that connects small language models to multiple data sources, aiming to predict the risk of various diseases simultaneously. Our experiments encompass 12 different tasks within a multitask learning setup. Although our approach does not surpass state-of-the-art methods specialized for single tasks, it demonstrates competitive performance and underscores the potential of small language models for multimodal reasoning in healthcare.
Poisoning Attacks on Federated Learning for Autonomous Driving
May 02, 2024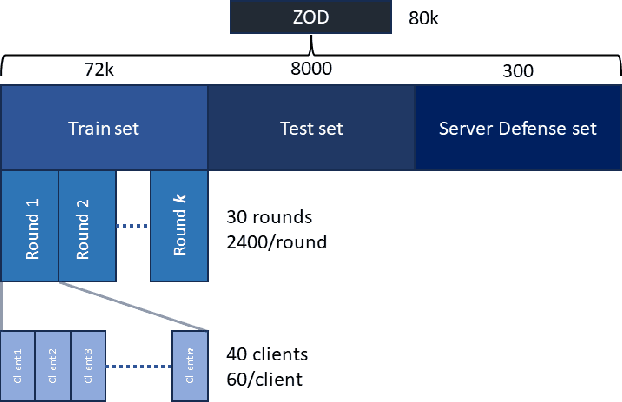
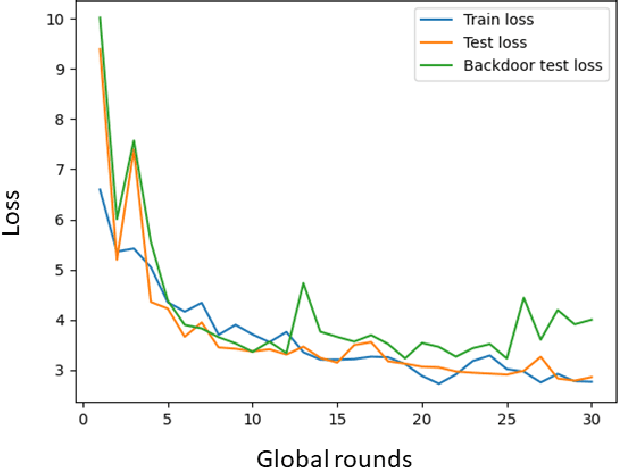


Federated Learning (FL) is a decentralized learning paradigm, enabling parties to collaboratively train models while keeping their data confidential. Within autonomous driving, it brings the potential of reducing data storage costs, reducing bandwidth requirements, and to accelerate the learning. FL is, however, susceptible to poisoning attacks. In this paper, we introduce two novel poisoning attacks on FL tailored to regression tasks within autonomous driving: FLStealth and Off-Track Attack (OTA). FLStealth, an untargeted attack, aims at providing model updates that deteriorate the global model performance while appearing benign. OTA, on the other hand, is a targeted attack with the objective to change the global model's behavior when exposed to a certain trigger. We demonstrate the effectiveness of our attacks by conducting comprehensive experiments pertaining to the task of vehicle trajectory prediction. In particular, we show that, among five different untargeted attacks, FLStealth is the most successful at bypassing the considered defenses employed by the server. For OTA, we demonstrate the inability of common defense strategies to mitigate the attack, highlighting the critical need for new defensive mechanisms against targeted attacks within FL for autonomous driving.
Secure Aggregation is Not Private Against Membership Inference Attacks
Mar 26, 2024Secure aggregation (SecAgg) is a commonly-used privacy-enhancing mechanism in federated learning, affording the server access only to the aggregate of model updates while safeguarding the confidentiality of individual updates. Despite widespread claims regarding SecAgg's privacy-preserving capabilities, a formal analysis of its privacy is lacking, making such presumptions unjustified. In this paper, we delve into the privacy implications of SecAgg by treating it as a local differential privacy (LDP) mechanism for each local update. We design a simple attack wherein an adversarial server seeks to discern which update vector a client submitted, out of two possible ones, in a single training round of federated learning under SecAgg. By conducting privacy auditing, we assess the success probability of this attack and quantify the LDP guarantees provided by SecAgg. Our numerical results unveil that, contrary to prevailing claims, SecAgg offers weak privacy against membership inference attacks even in a single training round. Indeed, it is difficult to hide a local update by adding other independent local updates when the updates are of high dimension. Our findings underscore the imperative for additional privacy-enhancing mechanisms, such as noise injection, in federated learning.
FedStruct: Federated Decoupled Learning over Interconnected Graphs
Feb 29, 2024We address the challenge of federated learning on graph-structured data distributed across multiple clients. Specifically, we focus on the prevalent scenario of interconnected subgraphs, where inter-connections between different clients play a critical role. We present a novel framework for this scenario, named FedStruct, that harnesses deep structural dependencies. To uphold privacy, unlike existing methods, FedStruct eliminates the necessity of sharing or generating sensitive node features or embeddings among clients. Instead, it leverages explicit global graph structure information to capture inter-node dependencies. We validate the effectiveness of FedStruct through experimental results conducted on six datasets for semi-supervised node classification, showcasing performance close to the centralized approach across various scenarios, including different data partitioning methods, varying levels of label availability, and number of clients.
Balancing Privacy and Security in Federated Learning with FedGT: A Group Testing Framework
May 09, 2023



We propose FedGT, a novel framework for identifying malicious clients in federated learning with secure aggregation. Inspired by group testing, the framework leverages overlapping groups of clients to detect the presence of malicious clients in the groups and to identify them via a decoding operation. The identified clients are then removed from the training of the model, which is performed over the remaining clients. FedGT strikes a balance between privacy and security, allowing for improved identification capabilities while still preserving data privacy. Specifically, the server learns the aggregated model of the clients in each group. The effectiveness of FedGT is demonstrated through extensive experiments on the MNIST and CIFAR-10 datasets, showing its ability to identify malicious clients with low misdetection and false alarm probabilities, resulting in high model utility.
Decentralised Semi-supervised Onboard Learning for Scene Classification in Low-Earth Orbit
May 06, 2023Onboard machine learning on the latest satellite hardware offers the potential for significant savings in communication and operational costs. We showcase the training of a machine learning model on a satellite constellation for scene classification using semi-supervised learning while accounting for operational constraints such as temperature and limited power budgets based on satellite processor benchmarks of the neural network. We evaluate mission scenarios employing both decentralised and federated learning approaches. All scenarios achieve convergence to high accuracy (around 91% on EuroSAT RGB dataset) within a one-day mission timeframe.