 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate and Robust Contribution Evaluation in Federated Learning
Feb 25, 2026Cross-silo federated learning allows multiple organizations to collaboratively train machine learning models without sharing raw data, but client updates can still leak sensitive information through inference attacks. Secure aggregation protects privacy by hiding individual updates, yet it complicates contribution evaluation, which is critical for fair rewards and detecting low-quality or malicious participants. Existing marginal-contribution methods, such as the Shapley value, are incompatible with secure aggregation, and practical alternatives, such as Leave-One-Out, are crude and rely on self-evaluation. We introduce two marginal-difference contribution scores compatible with secure aggregation. Fair-Private satisfies standard fairness axioms, while Everybody-Else eliminates self-evaluation and provides resistance to manipulation, addressing a largely overlooked vulnerability. We provide theoretical guarantees for fairness, privacy, robustness, and computational efficiency, and evaluate our methods on multiple medical image datasets and CIFAR10 in cross-silo settings. Our scores consistently outperform existing baselines, better approximate Shapley-induced client rankings, and improve downstream model performance as well as misbehavior detection. These results demonstrate that fairness, privacy, robustness, and practical utility can be achieved jointly in federated contribution evaluation, offering a principled solution for real-world cross-silo deployments.
Perfectly-Private Analog Secure Aggregation in Federated Learning
Sep 10, 2025



In federated learning, multiple parties train models locally and share their parameters with a central server, which aggregates them to update a global model. To address the risk of exposing sensitive data through local models, secure aggregation via secure multiparty computation has been proposed to enhance privacy. At the same time, perfect privacy can only be achieved by a uniform distribution of the masked local models to be aggregated. This raises a problem when working with real valued data, as there is no measure on the reals that is invariant under the masking operation, and hence information leakage is bound to occur. Shifting the data to a finite field circumvents this problem, but as a downside runs into an inherent accuracy complexity tradeoff issue due to fixed point modular arithmetic as opposed to floating point numbers that can simultaneously handle numbers of varying magnitudes. In this paper, a novel secure parameter aggregation method is proposed that employs the torus rather than a finite field. This approach guarantees perfect privacy for each party's data by utilizing the uniform distribution on the torus, while avoiding accuracy losses. Experimental results show that the new protocol performs similarly to the model without secure aggregation while maintaining perfect privacy. Compared to the finite field secure aggregation, the torus-based protocol can in some cases significantly outperform it in terms of model accuracy and cosine similarity, hence making it a safer choice.
Practical Bayes-Optimal Membership Inference Attacks
May 30, 2025We develop practical and theoretically grounded membership inference attacks (MIAs) against both independent and identically distributed (i.i.d.) data and graph-structured data. Building on the Bayesian decision-theoretic framework of Sablayrolles et al., we derive the Bayes-optimal membership inference rule for node-level MIAs against graph neural networks, addressing key open questions about optimal query strategies in the graph setting. We introduce BASE and G-BASE, computationally efficient approximations of the Bayes-optimal attack. G-BASE achieves superior performance compared to previously proposed classifier-based node-level MIA attacks. BASE, which is also applicable to non-graph data, matches or exceeds the performance of prior state-of-the-art MIAs, such as LiRA and RMIA, at a significantly lower computational cost. Finally, we show that BASE and RMIA are equivalent under a specific hyperparameter setting, providing a principled, Bayes-optimal justification for the RMIA attack.
Uplink Cell-Free Massive MIMO OFDM with Phase Noise-Aware Channel Estimation: Separate and Shared LOs
Oct 24, 2024



Cell-free massive multiple-input multiple-output (mMIMO) networks enhance coverage and spectral efficiency (SE) by distributing antennas across access points (APs) with phase coherence between APs. However, the use of cost-efficient local oscillators (LOs) introduces phase noise (PN) that compromises phase coherence, even with centralized processing. Sharing an LO across APs can reduce costs in specific configurations but cause correlated PN between APs, leading to correlated interference that affects centralized combining. This can be improved by exploiting the PN correlation in channel estimation. This paper presents an uplink orthogonal frequency division multiplexing (OFDM) signal model for PN-impaired cell-free mMIMO, addressing gaps in single-carrier signal models. We evaluate mismatches from applying single-carrier methods to OFDM systems, showing how they underestimate the impact of PN and produce over-optimistic achievable SE predictions. Based on our OFDM signal model, we propose two PN-aware channel and common phase error estimators: a distributed estimator for uncorrelated PN with separate LOs and a centralized estimator with shared LOs. We introduce a deep learning-based channel estimator to enhance the performance and reduce the number of iterations of the centralized estimator. The simulation results show that the distributed estimator outperforms mismatched estimators with separate LOs, whereas the centralized estimator enhances distributed estimators with shared LOs.
Decoding Quantum LDPC Codes Using Graph Neural Networks
Aug 09, 2024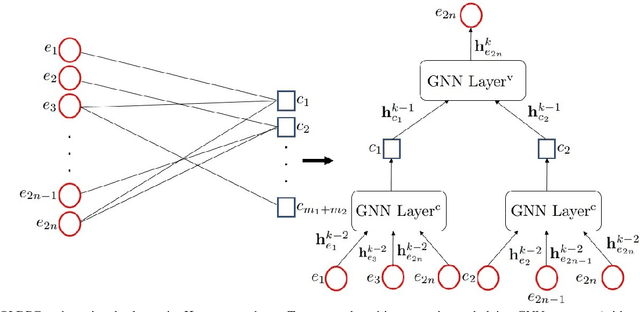
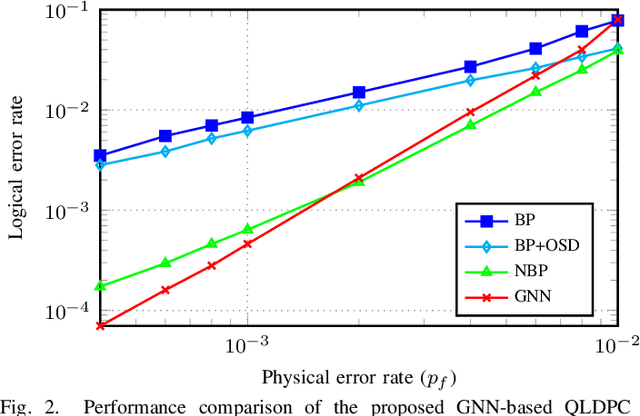
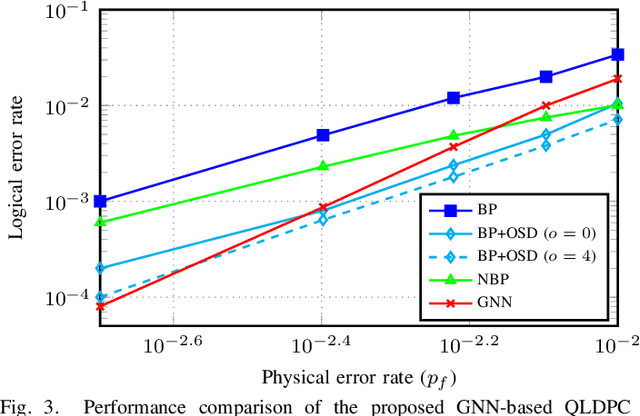

In this paper, we propose a novel decoding method for Quantum Low-Density Parity-Check (QLDPC) codes based on Graph Neural Networks (GNNs). Similar to the Belief Propagation (BP)-based QLDPC decoders, the proposed GNN-based QLDPC decoder exploits the sparse graph structure of QLDPC codes and can be implemented as a message-passing decoding algorithm. We compare the proposed GNN-based decoding algorithm against selected classes of both conventional and neural-enhanced QLDPC decoding algorithms across several QLDPC code designs. The simulation results demonstrate excellent performance of GNN-based decoders along with their low complexity compared to competing methods.
Timely Status Updates in Slotted ALOHA Network With Energy Harvesting
Apr 29, 2024



We investigate the age of information (AoI) in a scenario where energy-harvesting devices send status updates to a gateway following the slotted ALOHA protocol and receive no feedback. We let the devices adjust the transmission probabilities based on their current battery level. Using a Markovian analysis, we derive analytically the average AoI. We further provide an approximate analysis for accurate and easy-to-compute approximations of both the average AoI and the age-violation probability (AVP), i.e., the probability that the AoI exceeds a given threshold. We also analyze the average throughput. Via numerical results, we investigate two baseline strategies: transmit a new update whenever possible to exploit every opportunity to reduce the AoI, and transmit only when sufficient energy is available to increase the chance of successful decoding. The two strategies are beneficial for low and high update-generation rates, respectively. We show that an optimized policy that balances the two strategies outperforms them significantly in terms of both AoI metrics and throughput. Finally, we show the benefit of decoding multiple packets in a slot using successive interference cancellation and adapting the transmission probability based on both the current battery level and the time elapsed since the last transmission.
Secure Aggregation is Not Private Against Membership Inference Attacks
Mar 26, 2024Secure aggregation (SecAgg) is a commonly-used privacy-enhancing mechanism in federated learning, affording the server access only to the aggregate of model updates while safeguarding the confidentiality of individual updates. Despite widespread claims regarding SecAgg's privacy-preserving capabilities, a formal analysis of its privacy is lacking, making such presumptions unjustified. In this paper, we delve into the privacy implications of SecAgg by treating it as a local differential privacy (LDP) mechanism for each local update. We design a simple attack wherein an adversarial server seeks to discern which update vector a client submitted, out of two possible ones, in a single training round of federated learning under SecAgg. By conducting privacy auditing, we assess the success probability of this attack and quantify the LDP guarantees provided by SecAgg. Our numerical results unveil that, contrary to prevailing claims, SecAgg offers weak privacy against membership inference attacks even in a single training round. Indeed, it is difficult to hide a local update by adding other independent local updates when the updates are of high dimension. Our findings underscore the imperative for additional privacy-enhancing mechanisms, such as noise injection, in federated learning.
FedStruct: Federated Decoupled Learning over Interconnected Graphs
Feb 29, 2024We address the challenge of federated learning on graph-structured data distributed across multiple clients. Specifically, we focus on the prevalent scenario of interconnected subgraphs, where inter-connections between different clients play a critical role. We present a novel framework for this scenario, named FedStruct, that harnesses deep structural dependencies. To uphold privacy, unlike existing methods, FedStruct eliminates the necessity of sharing or generating sensitive node features or embeddings among clients. Instead, it leverages explicit global graph structure information to capture inter-node dependencies. We validate the effectiveness of FedStruct through experimental results conducted on six datasets for semi-supervised node classification, showcasing performance close to the centralized approach across various scenarios, including different data partitioning methods, varying levels of label availability, and number of clients.
Time vs. Frequency Domain DPD for Massive MIMO: Methods and Performance Analysis
Feb 26, 2024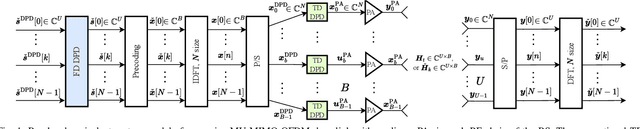
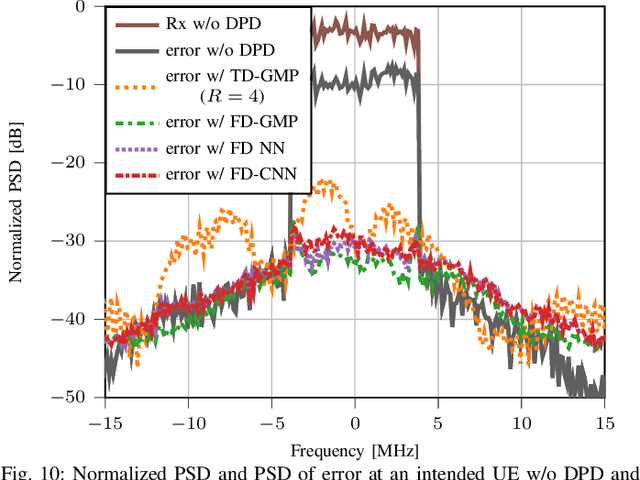
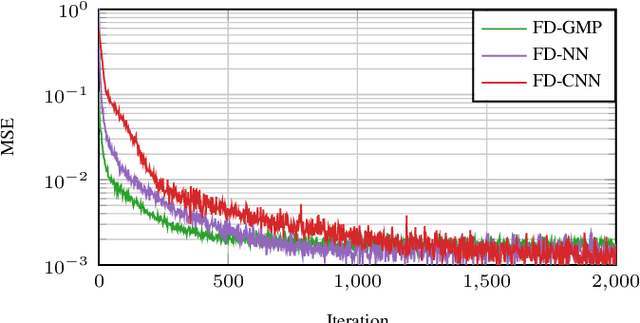
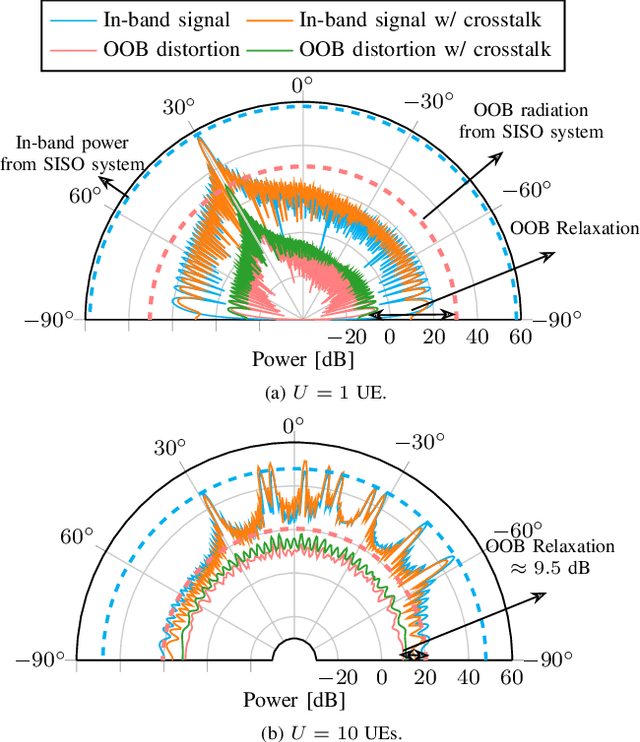
The use of up to hundreds of antennas in massive multi-user (MU) multiple-input multiple-output (MIMO) orthogonal frequency division multiplexing (OFDM) poses a complexity challenge for digital predistortion (DPD) aiming to linearize the nonlinear power amplifiers (PAs). While the complexity for conventional time domain (TD) DPD scales with the number of PAs, frequency domain (FD) DPD has a complexity scaling with the number of user equipments (UEs). In this work, we provide a comprehensive analysis of different state-of-the-art TD and FD-DPD schemes in terms of complexity and linearization performance in both rich scattering and line-of-sight (LOS) channels. We also propose a novel low-complexity FD convolutional neural network (CNN) DPD. The analysis shows that FD-DPD, particularly the proposed FD CNN, is preferable in LOS scenarios with few users, due to the favorable trade-off between complexity and linearization performance. On the other hand, in scenarios with more users or isotropic scattering channels, significant intermodulation distortions among UEs degrade FD-DPD performance, making TD-DPD more suitable.
Blind Frequency-Domain Equalization Using Vector-Quantized Variational Autoencoders
Dec 26, 2023


We propose a novel frequency-domain blind equalization scheme for coherent optical communications. The method is shown to achieve similar performance to its recently proposed time-domain counterpart with lower computational complexity, while outperforming the commonly used CMA-based equalizers.