 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Anonymity for Private Random Walk Decentralized Learning
May 11, 2025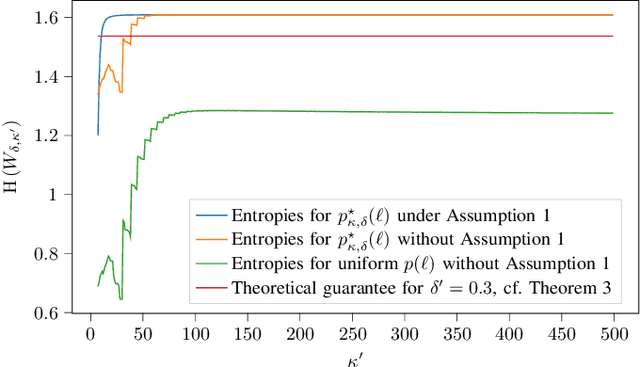
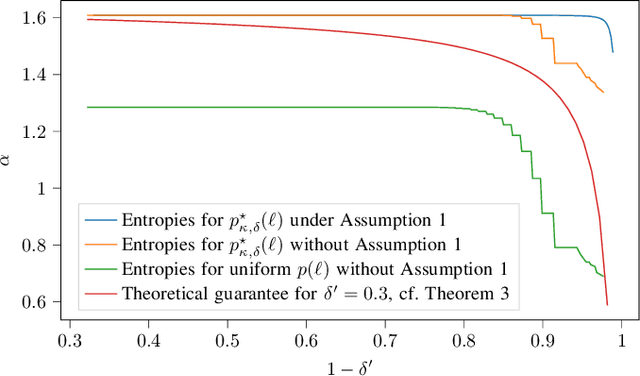
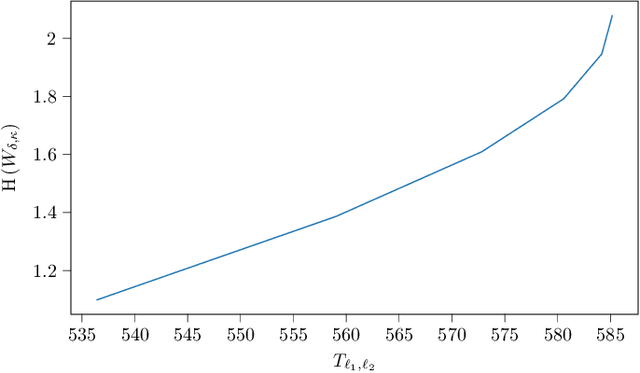
This paper considers random walk-based decentralized learning, where at each iteration of the learning process, one user updates the model and sends it to a randomly chosen neighbor until a convergence criterion is met. Preserving data privacy is a central concern and open problem in decentralized learning. We propose a privacy-preserving algorithm based on public-key cryptography and anonymization. In this algorithm, the user updates the model and encrypts the result using a distant user's public key. The encrypted result is then transmitted through the network with the goal of reaching that specific user. The key idea is to hide the source's identity so that, when the destination user decrypts the result, it does not know who the source was. The challenge is to design a network-dependent probability distribution (at the source) over the potential destinations such that, from the receiver's perspective, all users have a similar likelihood of being the source. We introduce the problem and construct a scheme that provides anonymity with theoretical guarantees. We focus on random regular graphs to establish rigorous guarantees.
Self-Duplicating Random Walks for Resilient Decentralized Learning on Graphs
Jul 16, 2024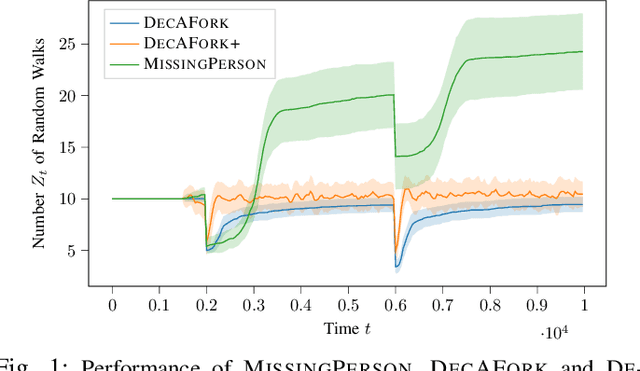
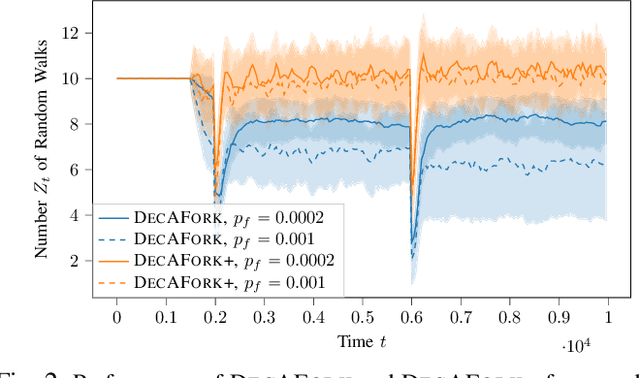
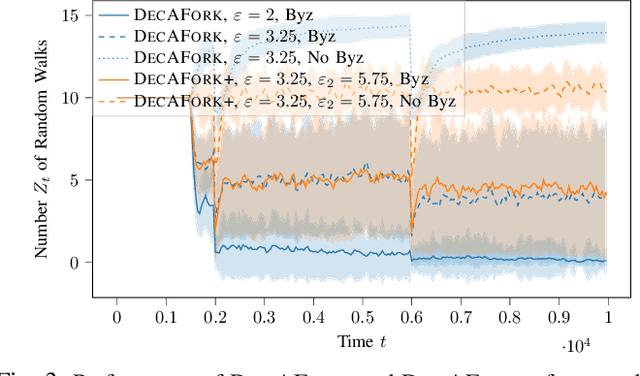
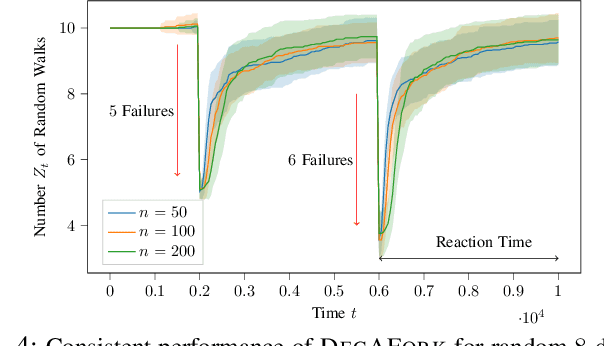
Consider the setting of multiple random walks (RWs) on a graph executing a certain computational task. For instance, in decentralized learning via RWs, a model is updated at each iteration based on the local data of the visited node and then passed to a randomly chosen neighbor. RWs can fail due to node or link failures. The goal is to maintain a desired number of RWs to ensure failure resilience. Achieving this is challenging due to the lack of a central entity to track which RWs have failed to replace them with new ones by forking (duplicating) surviving ones. Without duplications, the number of RWs will eventually go to zero, causing a catastrophic failure of the system. We propose a decentralized algorithm called DECAFORK that can maintain the number of RWs in the graph around a desired value even in the presence of arbitrary RW failures. Nodes continuously estimate the number of surviving RWs by estimating their return time distribution and fork the RWs when failures are likely to happen. We present extensive numerical simulations that show the performance of DECAFORK regarding fast detection and reaction to failures. We further present theoretical guarantees on the performance of this algorithm.
Scalable and Reliable Over-the-Air Federated Edge Learning
Jul 16, 2024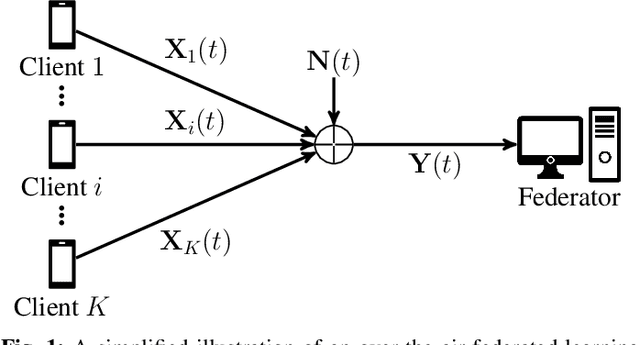
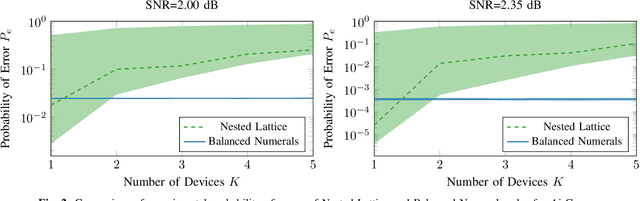
Federated edge learning (FEEL) has emerged as a core paradigm for large-scale optimization. However, FEEL still suffers from a communication bottleneck due to the transmission of high-dimensional model updates from the clients to the federator. Over-the-air computation (AirComp) leverages the additive property of multiple-access channels by aggregating the clients' updates over the channel to save communication resources. While analog uncoded transmission can benefit from the increased signal-to-noise ratio (SNR) due to the simultaneous transmission of many clients, potential errors may severely harm the learning process for small SNRs. To alleviate this problem, channel coding approaches were recently proposed for AirComp in FEEL. However, their error-correction capability degrades with an increasing number of clients. We propose a digital lattice-based code construction with constant error-correction capabilities in the number of clients, and compare to nested-lattice codes, well-known for their optimal rate and power efficiency in the point-to-point AWGN channel.
Maximal-Capacity Discrete Memoryless Channel Identification
Jan 18, 2024

The problem of identifying the channel with the highest capacity among several discrete memoryless channels (DMCs) is considered. The problem is cast as a pure-exploration multi-armed bandit problem, which follows the practical use of training sequences to sense the communication channel statistics. A capacity estimator is proposed and tight confidence bounds on the estimator error are derived. Based on this capacity estimator, a gap-elimination algorithm termed BestChanID is proposed, which is oblivious to the capacity-achieving input distribution and is guaranteed to output the DMC with the largest capacity, with a desired confidence. Furthermore, two additional algorithms NaiveChanSel and MedianChanEl, that output with certain confidence a DMC with capacity close to the maximal, are introduced. Each of those algorithms is beneficial in a different regime and can be used as a subroutine in BestChanID. The sample complexity of all algorithms is analyzed as a function of the desired confidence parameter, the number of channels, and the channels' input and output alphabet sizes. The cost of best channel identification is shown to scale quadratically with the alphabet size, and a fundamental lower bound for the required number of channel senses to identify the best channel with a certain confidence is derived.
Private Aggregation in Wireless Federated Learning with Heterogeneous Clusters
Jun 25, 2023
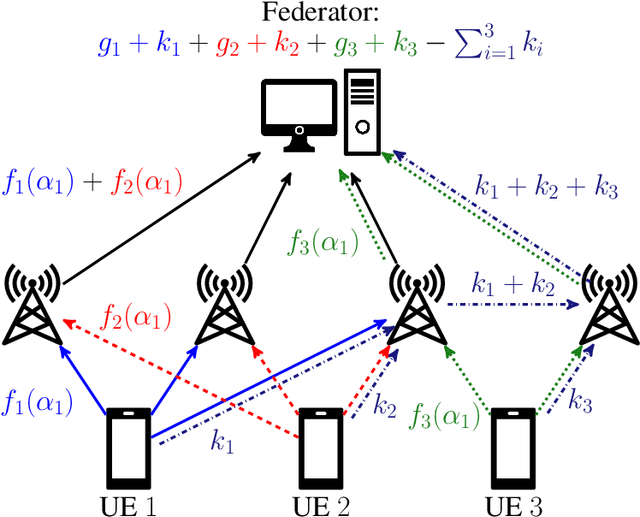
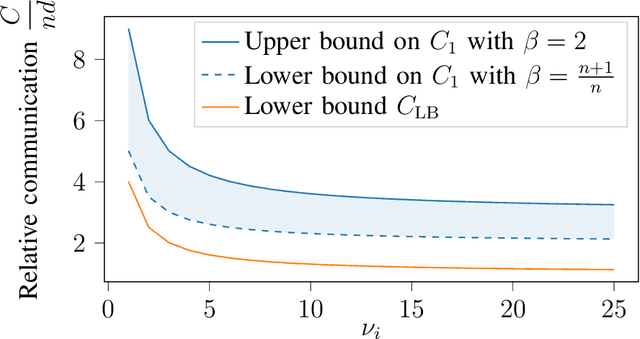
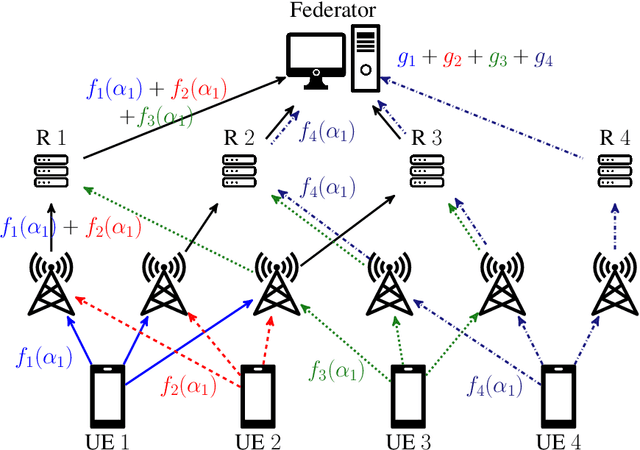
Federated learning collaboratively trains a neural network on privately owned data held by several participating clients. The gradient descent algorithm, a well-known and popular iterative optimization procedure, is run to train the neural network. Every client uses its local data to compute partial gradients and sends it to the federator which aggregates the results. Privacy of the clients' data is a major concern. In fact, observing the partial gradients can be enough to reveal the clients' data. Private aggregation schemes have been investigated to tackle the privacy problem in federated learning where all the users are connected to each other and to the federator. In this paper, we consider a wireless system architecture where clients are only connected to the federator via base stations. We derive fundamental limits on the communication cost when information-theoretic privacy is required, and introduce and analyze a private aggregation scheme tailored for this setting.
Balancing Privacy and Security in Federated Learning with FedGT: A Group Testing Framework
May 09, 2023



We propose FedGT, a novel framework for identifying malicious clients in federated learning with secure aggregation. Inspired by group testing, the framework leverages overlapping groups of clients to detect the presence of malicious clients in the groups and to identify them via a decoding operation. The identified clients are then removed from the training of the model, which is performed over the remaining clients. FedGT strikes a balance between privacy and security, allowing for improved identification capabilities while still preserving data privacy. Specifically, the server learns the aggregated model of the clients in each group. The effectiveness of FedGT is demonstrated through extensive experiments on the MNIST and CIFAR-10 datasets, showing its ability to identify malicious clients with low misdetection and false alarm probabilities, resulting in high model utility.
Secure Over-the-Air Computation using Zero-Forced Artificial Noise
Dec 22, 2022Over-the-air computation has the potential to increase the communication-efficiency of data-dependent distributed wireless systems, but is vulnerable to eavesdropping. We consider over-the-air computation over block-fading additive white Gaussian noise channels in the presence of a passive eavesdropper. The goal is to design a secure over-the-air computation scheme. We propose a scheme that achieves MSE-security against the eavesdropper by employing zero-forced artificial noise, while keeping the distortion at the legitimate receiver small. In contrast to former approaches, the security does not depend on external helper nodes to jam the eavesdropper's received signal. We thoroughly design the system parameters of the scheme, propose an artificial noise design that harnesses unused transmit power for security, and give an explicit construction rule. Our design approach is applicable in both cases, if the eavesdropper's channel coefficients are known and if they are unknown in the signal design. Simulations demonstrate the performance, and show that our noise design outperforms other methods.
Nested Gradient Codes for Straggler Mitigation in Distributed Machine Learning
Dec 16, 2022We consider distributed learning in the presence of slow and unresponsive worker nodes, referred to as stragglers. In order to mitigate the effect of stragglers, gradient coding redundantly assigns partial computations to the worker such that the overall result can be recovered from only the non-straggling workers. Gradient codes are designed to tolerate a fixed number of stragglers. Since the number of stragglers in practice is random and unknown a priori, tolerating a fixed number of stragglers can yield a sub-optimal computation load and can result in higher latency. We propose a gradient coding scheme that can tolerate a flexible number of stragglers by carefully concatenating gradient codes for different straggler tolerance. By proper task scheduling and small additional signaling, our scheme adapts the computation load of the workers to the actual number of stragglers. We analyze the latency of our proposed scheme and show that it has a significantly lower latency than gradient codes.
Efficient Distributed Machine Learning via Combinatorial Multi-Armed Bandits
Feb 16, 2022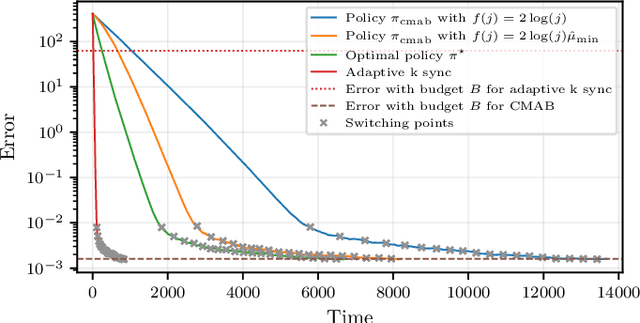
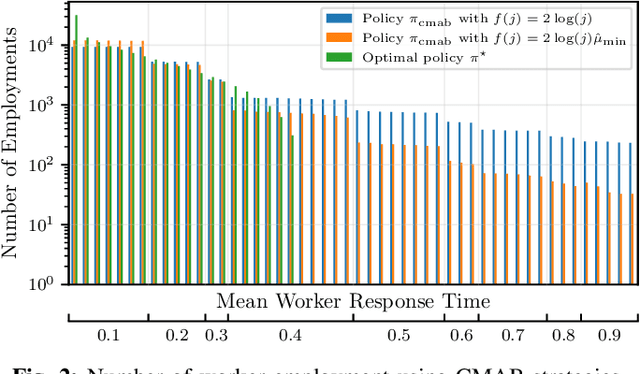
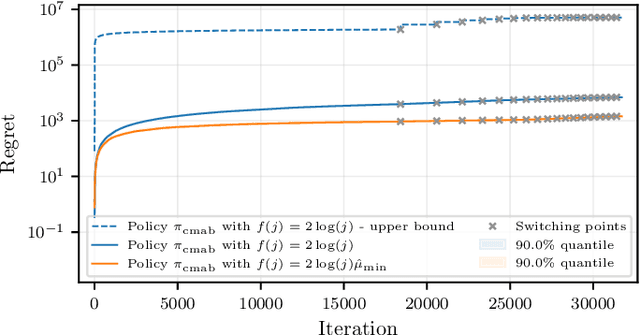
We consider the distributed stochastic gradient descent problem, where a main node distributes gradient calculations among $n$ workers from which at most $b \leq n$ can be utilized in parallel. By assigning tasks to all the workers and waiting only for the $k$ fastest ones, the main node can trade-off the error of the algorithm with its runtime by gradually increasing $k$ as the algorithm evolves. However, this strategy, referred to as adaptive k sync, can incur additional costs since it ignores the computational efforts of slow workers. We propose a cost-efficient scheme that assigns tasks only to $k$ workers and gradually increases $k$. As the response times of the available workers are unknown to the main node a priori, we utilize a combinatorial multi-armed bandit model to learn which workers are the fastest while assigning gradient calculations, and to minimize the effect of slow workers. Assuming that the mean response times of the workers are independent and exponentially distributed with different means, we give empirical and theoretical guarantees on the regret of our strategy, i.e., the extra time spent to learn the mean response times of the workers. Compared to adaptive k sync, our scheme achieves significantly lower errors with the same computational efforts while being inferior in terms of speed.