 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfect Privacy for Discriminator-Based Byzantine-Resilient Federated Learning
Jun 16, 2025



Federated learning (FL) shows great promise in large-scale machine learning but introduces new privacy and security challenges. We propose ByITFL and LoByITFL, two novel FL schemes that enhance resilience against Byzantine users while keeping the users' data private from eavesdroppers. To ensure privacy and Byzantine resilience, our schemes build on having a small representative dataset available to the federator and crafting a discriminator function allowing the mitigation of corrupt users' contributions. ByITFL employs Lagrange coded computing and re-randomization, making it the first Byzantine-resilient FL scheme with perfect Information-Theoretic (IT) privacy, though at the cost of a significant communication overhead. LoByITFL, on the other hand, achieves Byzantine resilience and IT privacy at a significantly reduced communication cost, but requires a Trusted Third Party, used only in a one-time initialization phase before training. We provide theoretical guarantees on privacy and Byzantine resilience, along with convergence guarantees and experimental results validating our findings.
Scalable and Reliable Over-the-Air Federated Edge Learning
Jul 16, 2024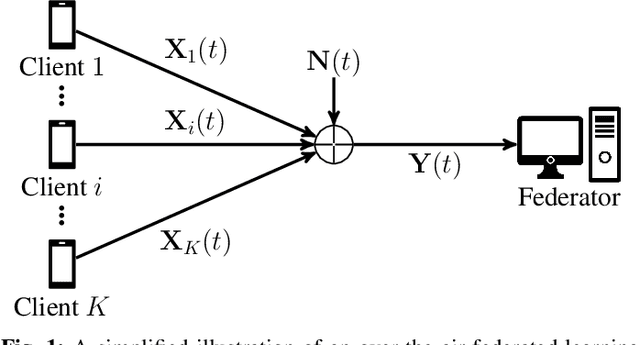
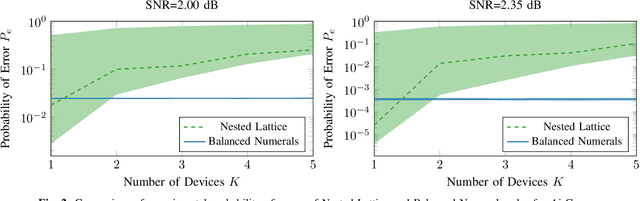
Federated edge learning (FEEL) has emerged as a core paradigm for large-scale optimization. However, FEEL still suffers from a communication bottleneck due to the transmission of high-dimensional model updates from the clients to the federator. Over-the-air computation (AirComp) leverages the additive property of multiple-access channels by aggregating the clients' updates over the channel to save communication resources. While analog uncoded transmission can benefit from the increased signal-to-noise ratio (SNR) due to the simultaneous transmission of many clients, potential errors may severely harm the learning process for small SNRs. To alleviate this problem, channel coding approaches were recently proposed for AirComp in FEEL. However, their error-correction capability degrades with an increasing number of clients. We propose a digital lattice-based code construction with constant error-correction capabilities in the number of clients, and compare to nested-lattice codes, well-known for their optimal rate and power efficiency in the point-to-point AWGN channel.
LoByITFL: Low Communication Secure and Private Federated Learning
May 29, 2024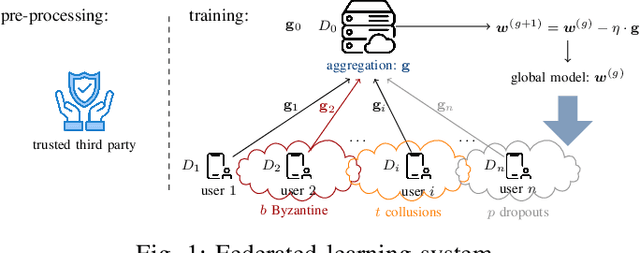
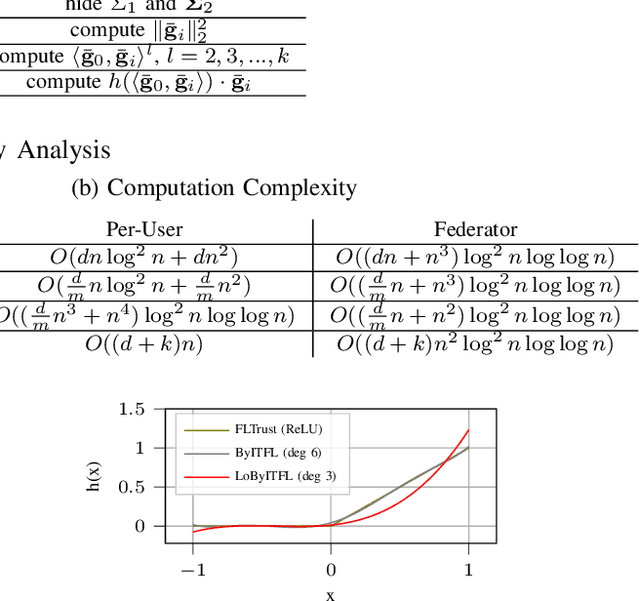

Federated Learning (FL) faces several challenges, such as the privacy of the clients data and security against Byzantine clients. Existing works treating privacy and security jointly make sacrifices on the privacy guarantee. In this work, we introduce LoByITFL, the first communication-efficient Information-Theoretic (IT) private and secure FL scheme that makes no sacrifices on the privacy guarantees while ensuring security against Byzantine adversaries. The key ingredients are a small and representative dataset available to the federator, a careful transformation of the FLTrust algorithm and the use of a trusted third party only in a one-time preprocessing phase before the start of the learning algorithm. We provide theoretical guarantees on privacy and Byzantine-resilience, and provide convergence guarantee and experimental results validating our theoretical findings.
Byzantine-Resilient Secure Aggregation for Federated Learning Without Privacy Compromises
May 14, 2024



Federated learning (FL) shows great promise in large scale machine learning, but brings new risks in terms of privacy and security. We propose ByITFL, a novel scheme for FL that provides resilience against Byzantine users while keeping the users' data private from the federator and private from other users. The scheme builds on the preexisting non-private FLTrust scheme, which tolerates malicious users through trust scores (TS) that attenuate or amplify the users' gradients. The trust scores are based on the ReLU function, which we approximate by a polynomial. The distributed and privacy-preserving computation in ByITFL is designed using a combination of Lagrange coded computing, verifiable secret sharing and re-randomization steps. ByITFL is the first Byzantine resilient scheme for FL with full information-theoretic privacy.
Private Aggregation in Wireless Federated Learning with Heterogeneous Clusters
Jun 25, 2023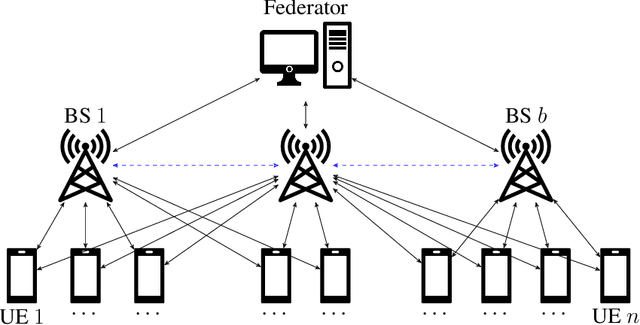
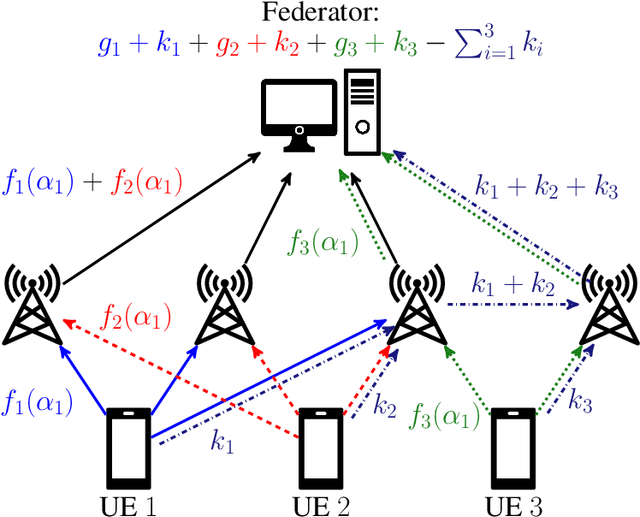
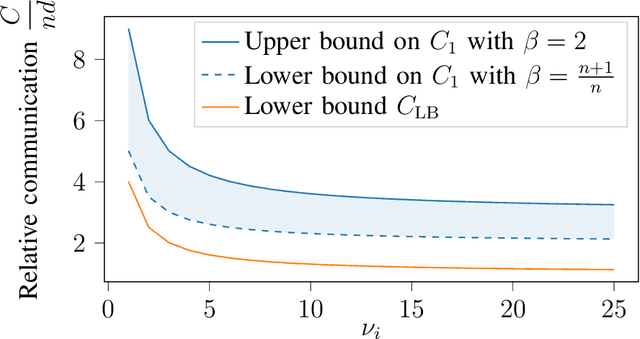
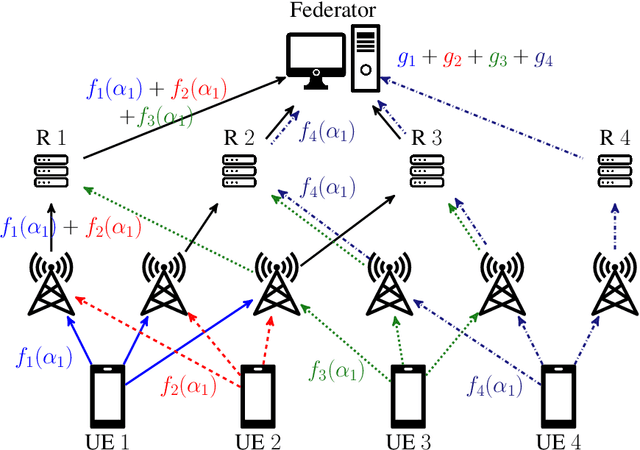
Federated learning collaboratively trains a neural network on privately owned data held by several participating clients. The gradient descent algorithm, a well-known and popular iterative optimization procedure, is run to train the neural network. Every client uses its local data to compute partial gradients and sends it to the federator which aggregates the results. Privacy of the clients' data is a major concern. In fact, observing the partial gradients can be enough to reveal the clients' data. Private aggregation schemes have been investigated to tackle the privacy problem in federated learning where all the users are connected to each other and to the federator. In this paper, we consider a wireless system architecture where clients are only connected to the federator via base stations. We derive fundamental limits on the communication cost when information-theoretic privacy is required, and introduce and analyze a private aggregation scheme tailored for this setting.
Nested Gradient Codes for Straggler Mitigation in Distributed Machine Learning
Dec 16, 2022We consider distributed learning in the presence of slow and unresponsive worker nodes, referred to as stragglers. In order to mitigate the effect of stragglers, gradient coding redundantly assigns partial computations to the worker such that the overall result can be recovered from only the non-straggling workers. Gradient codes are designed to tolerate a fixed number of stragglers. Since the number of stragglers in practice is random and unknown a priori, tolerating a fixed number of stragglers can yield a sub-optimal computation load and can result in higher latency. We propose a gradient coding scheme that can tolerate a flexible number of stragglers by carefully concatenating gradient codes for different straggler tolerance. By proper task scheduling and small additional signaling, our scheme adapts the computation load of the workers to the actual number of stragglers. We analyze the latency of our proposed scheme and show that it has a significantly lower latency than gradient codes.