 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfect Privacy for Discriminator-Based Byzantine-Resilient Federated Learning
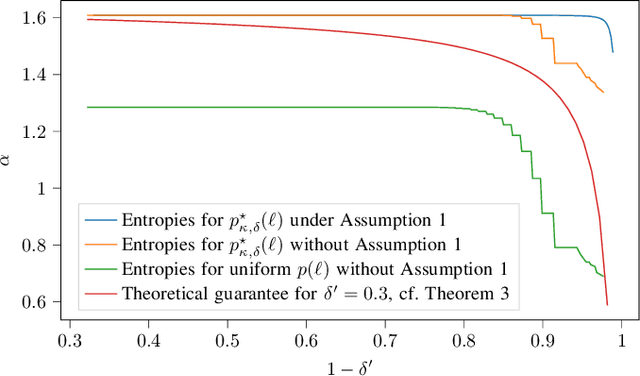
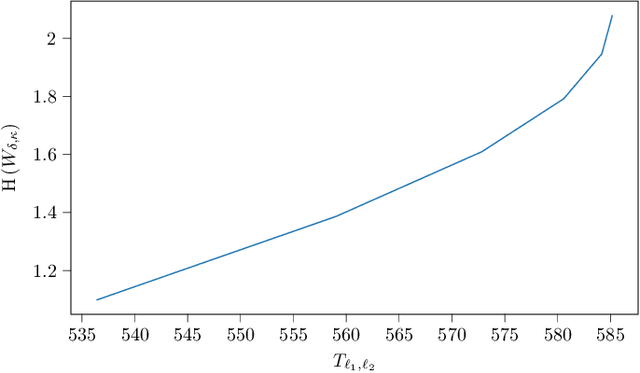
Jun 16, 2025Federated learning (FL) shows great promise in large-scale machine learning but introduces new privacy and security challenges. We propose ByITFL and LoByITFL, two novel FL schemes that enhance resilience against Byzantine users while keeping the users' data private from eavesdroppers. To ensure privacy and Byzantine resilience, our schemes build on having a small representative dataset available to the federator and crafting a discriminator function allowing the mitigation of corrupt users' contributions. ByITFL employs Lagrange coded computing and re-randomization, making it the first Byzantine-resilient FL scheme with perfect Information-Theoretic (IT) privacy, though at the cost of a significant communication overhead. LoByITFL, on the other hand, achieves Byzantine resilience and IT privacy at a significantly reduced communication cost, but requires a Trusted Third Party, used only in a one-time initialization phase before training. We provide theoretical guarantees on privacy and Byzantine resilience, along with convergence guarantees and experimental results validating our findings.
Private Aggregation for Byzantine-Resilient Heterogeneous Federated Learning
Jun 11, 2025Ensuring resilience to Byzantine clients while maintaining the privacy of the clients' data is a fundamental challenge in federated learning (FL). When the clients' data is homogeneous, suitable countermeasures were studied from an information-theoretic perspective utilizing secure aggregation techniques while ensuring robust aggregation of the clients' gradients. However, the countermeasures used fail when the clients' data is heterogeneous. Suitable pre-processing techniques, such as nearest neighbor mixing, were recently shown to enhance the performance of those countermeasures in the heterogeneous setting. Nevertheless, those pre-processing techniques cannot be applied with the introduced privacy-preserving mechanisms. We propose a multi-stage method encompassing a careful co-design of verifiable secret sharing, secure aggregation, and a tailored symmetric private information retrieval scheme to achieve information-theoretic privacy guarantees and Byzantine resilience under data heterogeneity. We evaluate the effectiveness of our scheme on a variety of attacks and show how it outperforms the previously known techniques. Since the communication overhead of secure aggregation is non-negligible, we investigate the interplay with zero-order estimation methods that reduce the communication cost in state-of-the-art FL tasks and thereby make private aggregation scalable.
Source Anonymity for Private Random Walk Decentralized Learning
May 11, 2025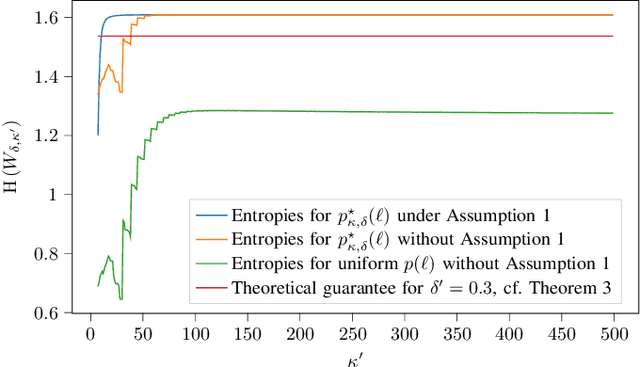
This paper considers random walk-based decentralized learning, where at each iteration of the learning process, one user updates the model and sends it to a randomly chosen neighbor until a convergence criterion is met. Preserving data privacy is a central concern and open problem in decentralized learning. We propose a privacy-preserving algorithm based on public-key cryptography and anonymization. In this algorithm, the user updates the model and encrypts the result using a distant user's public key. The encrypted result is then transmitted through the network with the goal of reaching that specific user. The key idea is to hide the source's identity so that, when the destination user decrypts the result, it does not know who the source was. The challenge is to design a network-dependent probability distribution (at the source) over the potential destinations such that, from the receiver's perspective, all users have a similar likelihood of being the source. We introduce the problem and construct a scheme that provides anonymity with theoretical guarantees. We focus on random regular graphs to establish rigorous guarantees.
Efficient Machine Unlearning by Model Splitting and Core Sample Selection
May 11, 2025Machine unlearning is essential for meeting legal obligations such as the right to be forgotten, which requires the removal of specific data from machine learning models upon request. While several approaches to unlearning have been proposed, existing solutions often struggle with efficiency and, more critically, with the verification of unlearning - particularly in the case of weak unlearning guarantees, where verification remains an open challenge. We introduce a generalized variant of the standard unlearning metric that enables more efficient and precise unlearning strategies. We also present an unlearning-aware training procedure that, in many cases, allows for exact unlearning. We term our approach MaxRR. When exact unlearning is not feasible, MaxRR still supports efficient unlearning with properties closely matching those achieved through full retraining.
Federated One-Shot Learning with Data Privacy and Objective-Hiding
Apr 29, 2025Privacy in federated learning is crucial, encompassing two key aspects: safeguarding the privacy of clients' data and maintaining the privacy of the federator's objective from the clients. While the first aspect has been extensively studied, the second has received much less attention. We present a novel approach that addresses both concerns simultaneously, drawing inspiration from techniques in knowledge distillation and private information retrieval to provide strong information-theoretic privacy guarantees. Traditional private function computation methods could be used here; however, they are typically limited to linear or polynomial functions. To overcome these constraints, our approach unfolds in three stages. In stage 0, clients perform the necessary computations locally. In stage 1, these results are shared among the clients, and in stage 2, the federator retrieves its desired objective without compromising the privacy of the clients' data. The crux of the method is a carefully designed protocol that combines secret-sharing-based multi-party computation and a graph-based private information retrieval scheme. We show that our method outperforms existing tools from the literature when properly adapted to this setting.
Scalable and Reliable Over-the-Air Federated Edge Learning
Jul 16, 2024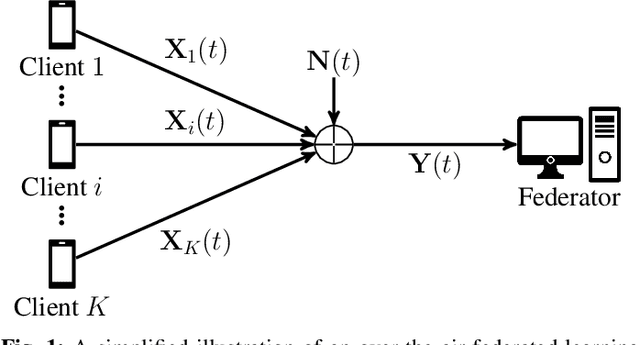
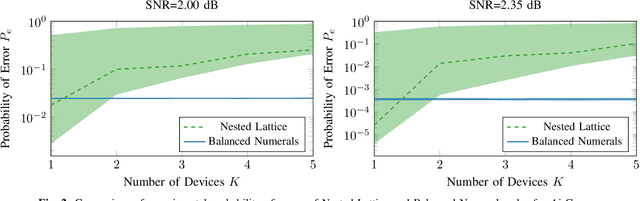
Federated edge learning (FEEL) has emerged as a core paradigm for large-scale optimization. However, FEEL still suffers from a communication bottleneck due to the transmission of high-dimensional model updates from the clients to the federator. Over-the-air computation (AirComp) leverages the additive property of multiple-access channels by aggregating the clients' updates over the channel to save communication resources. While analog uncoded transmission can benefit from the increased signal-to-noise ratio (SNR) due to the simultaneous transmission of many clients, potential errors may severely harm the learning process for small SNRs. To alleviate this problem, channel coding approaches were recently proposed for AirComp in FEEL. However, their error-correction capability degrades with an increasing number of clients. We propose a digital lattice-based code construction with constant error-correction capabilities in the number of clients, and compare to nested-lattice codes, well-known for their optimal rate and power efficiency in the point-to-point AWGN channel.
Self-Duplicating Random Walks for Resilient Decentralized Learning on Graphs
Jul 16, 2024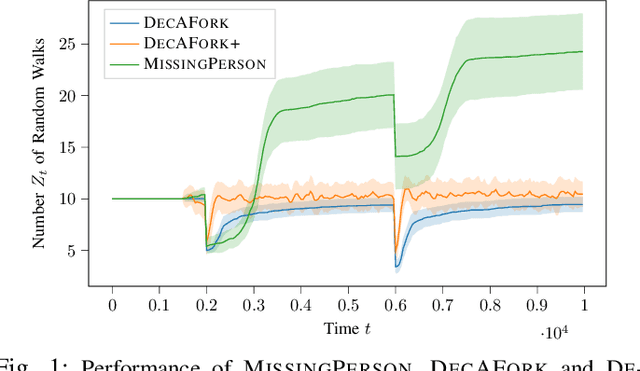
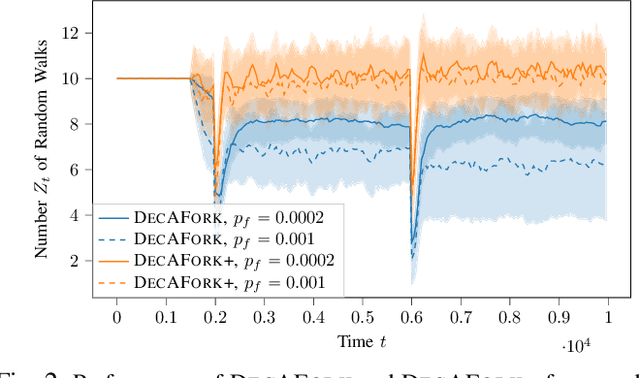
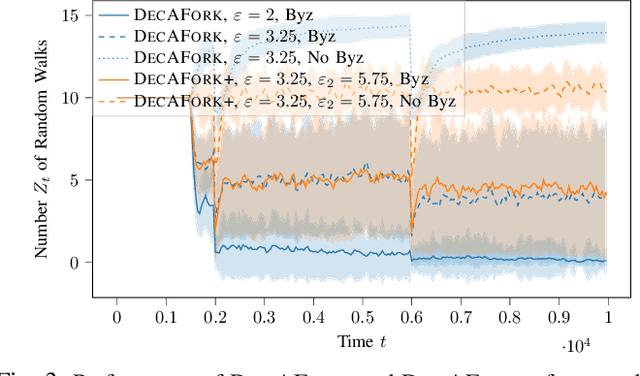
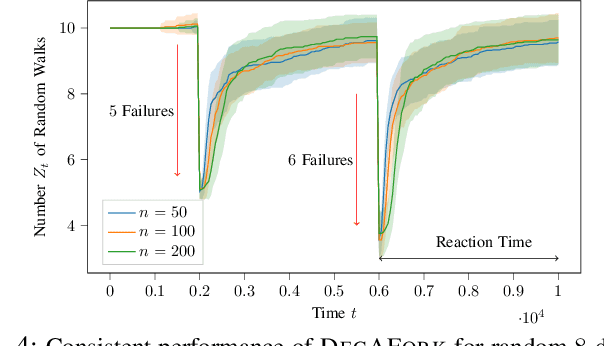
Consider the setting of multiple random walks (RWs) on a graph executing a certain computational task. For instance, in decentralized learning via RWs, a model is updated at each iteration based on the local data of the visited node and then passed to a randomly chosen neighbor. RWs can fail due to node or link failures. The goal is to maintain a desired number of RWs to ensure failure resilience. Achieving this is challenging due to the lack of a central entity to track which RWs have failed to replace them with new ones by forking (duplicating) surviving ones. Without duplications, the number of RWs will eventually go to zero, causing a catastrophic failure of the system. We propose a decentralized algorithm called DECAFORK that can maintain the number of RWs in the graph around a desired value even in the presence of arbitrary RW failures. Nodes continuously estimate the number of surviving RWs by estimating their return time distribution and fork the RWs when failures are likely to happen. We present extensive numerical simulations that show the performance of DECAFORK regarding fast detection and reaction to failures. We further present theoretical guarantees on the performance of this algorithm.
Communication-Efficient Byzantine-Resilient Federated Zero-Order Optimization
Jun 20, 2024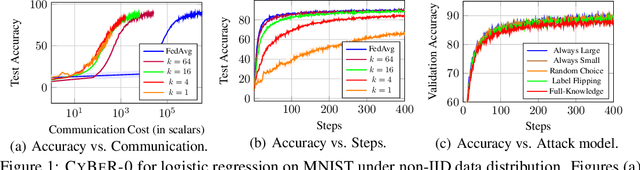
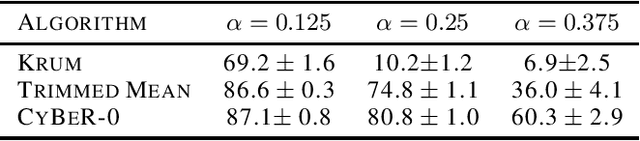
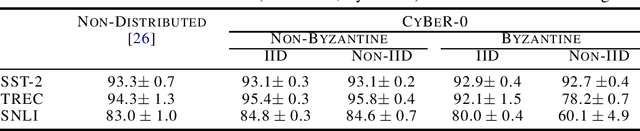
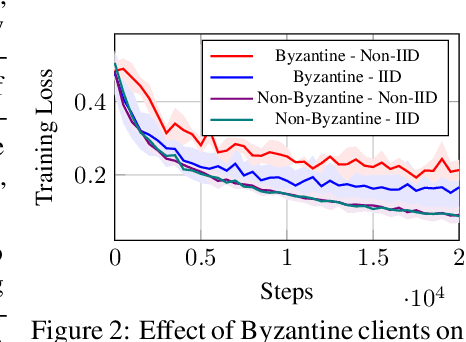
We introduce CYBER-0, the first zero-order optimization algorithm for memory-and-communication efficient Federated Learning, resilient to Byzantine faults. We show through extensive numerical experiments on the MNIST dataset and finetuning RoBERTa-Large that CYBER-0 outperforms state-of-the-art algorithms in terms of communication and memory efficiency while reaching similar accuracy. We provide theoretical guarantees on its convergence for convex loss functions.
LoByITFL: Low Communication Secure and Private Federated Learning
May 29, 2024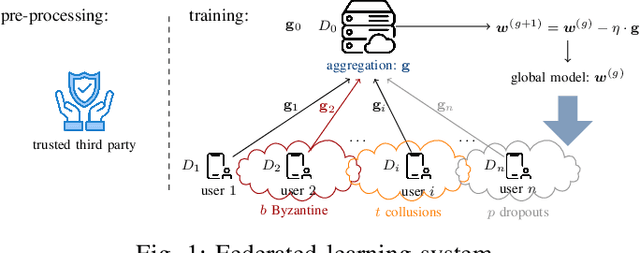
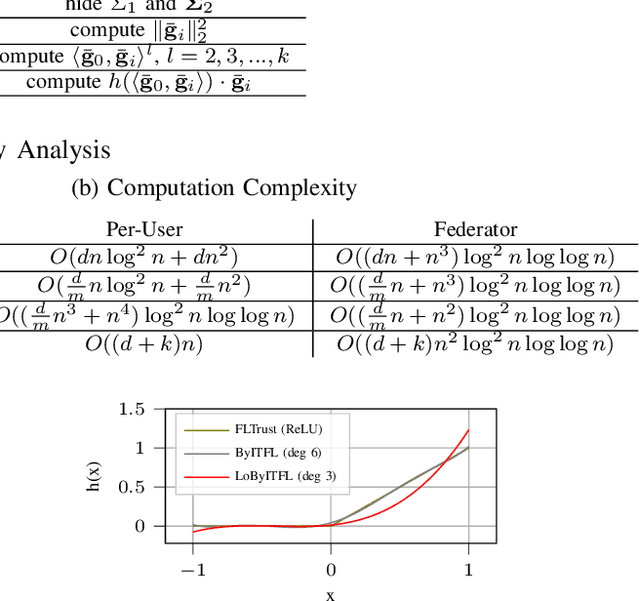

Federated Learning (FL) faces several challenges, such as the privacy of the clients data and security against Byzantine clients. Existing works treating privacy and security jointly make sacrifices on the privacy guarantee. In this work, we introduce LoByITFL, the first communication-efficient Information-Theoretic (IT) private and secure FL scheme that makes no sacrifices on the privacy guarantees while ensuring security against Byzantine adversaries. The key ingredients are a small and representative dataset available to the federator, a careful transformation of the FLTrust algorithm and the use of a trusted third party only in a one-time preprocessing phase before the start of the learning algorithm. We provide theoretical guarantees on privacy and Byzantine-resilience, and provide convergence guarantee and experimental results validating our theoretical findings.
Byzantine-Resilient Secure Aggregation for Federated Learning Without Privacy Compromises
May 14, 2024



Federated learning (FL) shows great promise in large scale machine learning, but brings new risks in terms of privacy and security. We propose ByITFL, a novel scheme for FL that provides resilience against Byzantine users while keeping the users' data private from the federator and private from other users. The scheme builds on the preexisting non-private FLTrust scheme, which tolerates malicious users through trust scores (TS) that attenuate or amplify the users' gradients. The trust scores are based on the ReLU function, which we approximate by a polynomial. The distributed and privacy-preserving computation in ByITFL is designed using a combination of Lagrange coded computing, verifiable secret sharing and re-randomization steps. ByITFL is the first Byzantine resilient scheme for FL with full information-theoretic privacy.