Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Byzantine-Resilient Federated Zero-Order Optimization
Paper and Code
Jun 20, 2024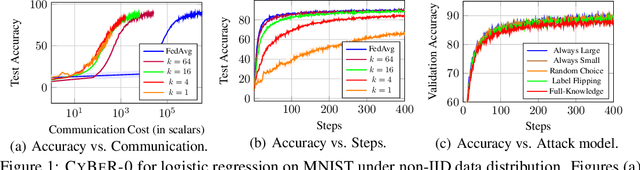
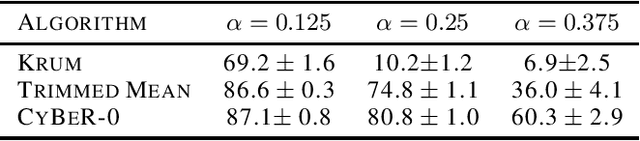
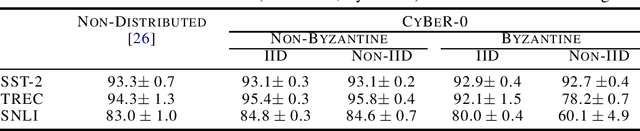
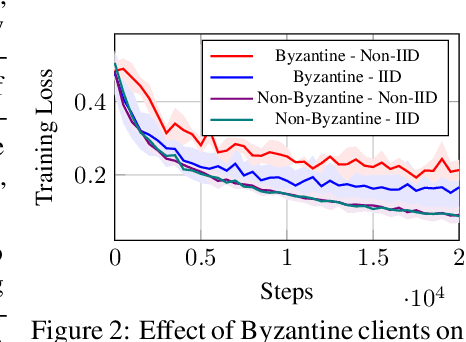
We introduce CYBER-0, the first zero-order optimization algorithm for memory-and-communication efficient Federated Learning, resilient to Byzantine faults. We show through extensive numerical experiments on the MNIST dataset and finetuning RoBERTa-Large that CYBER-0 outperforms state-of-the-art algorithms in terms of communication and memory efficiency while reaching similar accuracy. We provide theoretical guarantees on its convergence for convex loss functions.
View paper on