 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Node Selection in Personalized Decentralized Learning
Jan 30, 2023



In this paper, we propose a novel approach for privacy-preserving node selection in personalized decentralized learning, which we refer to as Private Personalized Decentralized Learning (PPDL). Our method mitigates the risk of inference attacks through the use of secure aggregation while simultaneously enabling efficient identification of collaborators. This is achieved by leveraging adversarial multi-armed bandit optimization that exploits dependencies between the different arms. Through comprehensive experimentation on various benchmarks under label and covariate shift, we demonstrate that our privacy-preserving approach outperforms previous non-private methods in terms of model performance.
Decentralized Online Bandit Optimization on Directed Graphs with Regret Bounds
Jan 27, 2023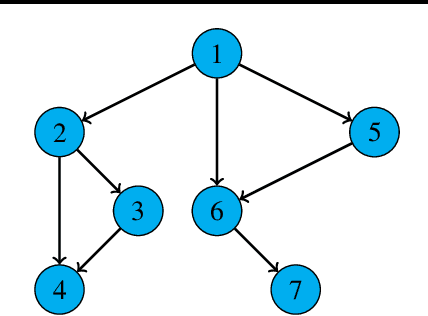
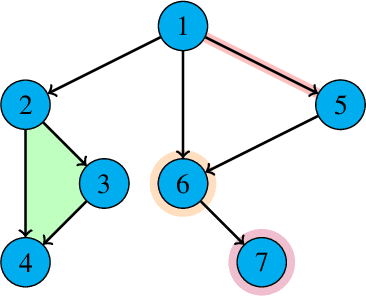
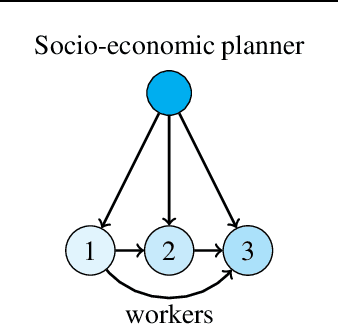
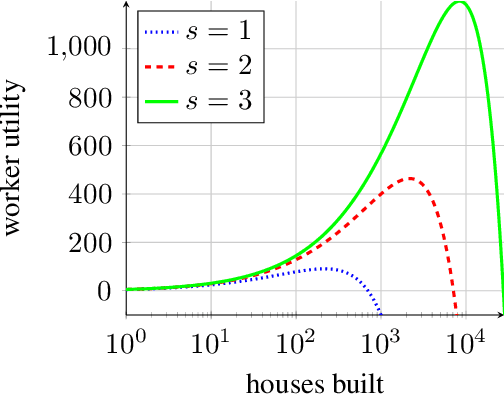
We consider a decentralized multiplayer game, played over $T$ rounds, with a leader-follower hierarchy described by a directed acyclic graph. For each round, the graph structure dictates the order of the players and how players observe the actions of one another. By the end of each round, all players receive a joint bandit-reward based on their joint action that is used to update the player strategies towards the goal of minimizing the joint pseudo-regret. We present a learning algorithm inspired by the single-player multi-armed bandit problem and show that it achieves sub-linear joint pseudo-regret in the number of rounds for both adversarial and stochastic bandit rewards. Furthermore, we quantify the cost incurred due to the decentralized nature of our problem compared to the centralized setting.
Adaptive Expert Models for Personalization in Federated Learning
Jun 15, 2022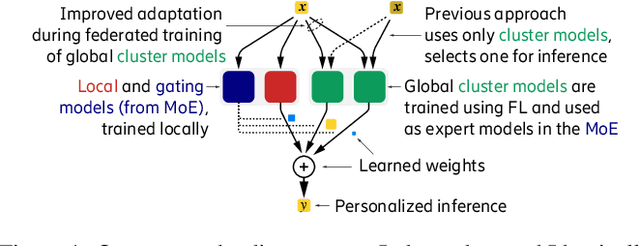

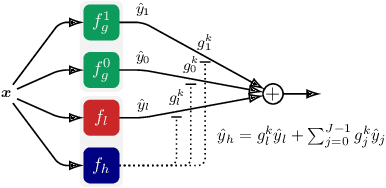
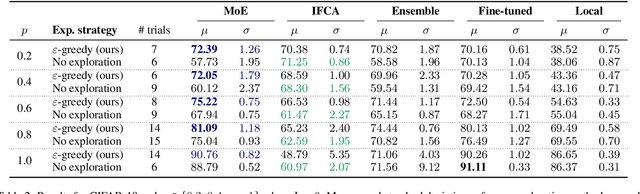
Federated Learning (FL) is a promising framework for distributed learning when data is private and sensitive. However, the state-of-the-art solutions in this framework are not optimal when data is heterogeneous and non-Independent and Identically Distributed (non-IID). We propose a practical and robust approach to personalization in FL that adjusts to heterogeneous and non-IID data by balancing exploration and exploitation of several global models. To achieve our aim of personalization, we use a Mixture of Experts (MoE) that learns to group clients that are similar to each other, while using the global models more efficiently. We show that our approach achieves an accuracy up to 29.78 % and up to 4.38 % better compared to a local model in a pathological non-IID setting, even though we tune our approach in the IID setting.
Federated learning using a mixture of experts
Oct 05, 2020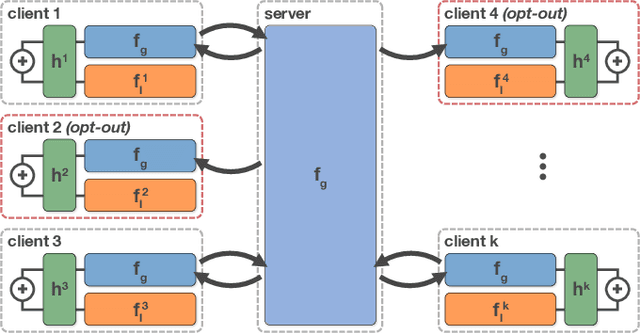

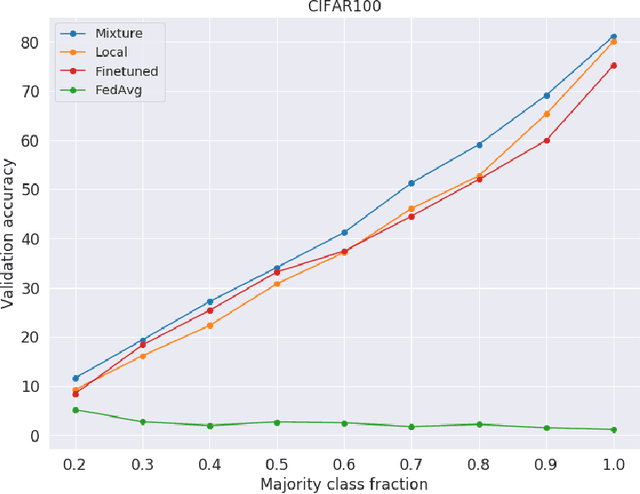

Federated learning has received attention for its efficiency and privacy benefits, in settings where data is distributed among devices. Although federated learning shows significant promise as a key approach when data cannot be shared or centralized, current incarnations show limited privacy properties and have shortcomings when applied to common real-world scenarios. One such scenario is heterogeneous data among devices, where data may come from different generating distributions. In this paper, we propose a federated learning framework using a mixture of experts to balance the specialist nature of a locally trained model with the generalist knowledge of a global model in a federated learning setting. Our results show that the mixture of experts model is better suited as a personalized model for devices when data is heterogeneous, outperforming both global and local models. Furthermore, our framework gives strict privacy guarantees, which allows clients to select parts of their data that may be excluded from the federation. The evaluation shows that the proposed solution is robust to the setting where some users require a strict privacy setting and do not disclose their models to a central server at all, opting out from the federation partially or entirely. The proposed framework is general enough to include any kind of machine learning models, and can even use combinations of different kinds.
Adversarial representation learning for synthetic replacement of private attributes
Jun 23, 2020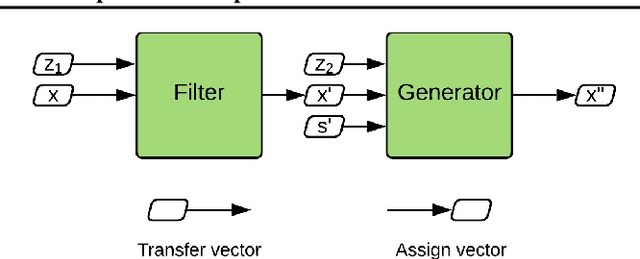
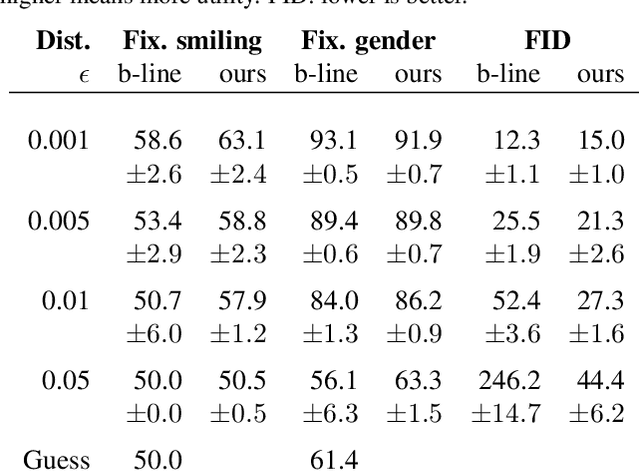
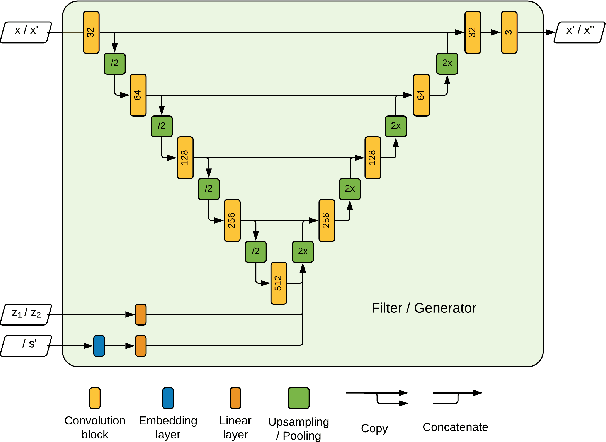
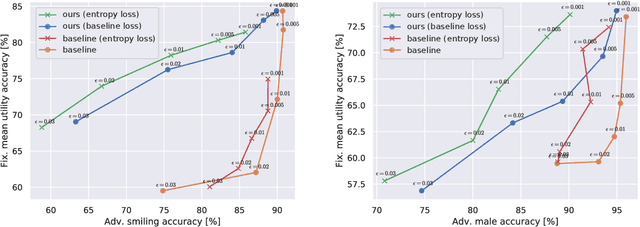
The collection of large datasets allows for advanced analytics that can lead to improved quality of life and progress in applications such as machine cognition and medical analysis. However, recently there has been an increased pressure to guarantee the privacy of users when collecting data. In this work, we study how adversarial representation learning can be used to ensure the privacy of users, and to obfuscate sensitive attributes in existing datasets. While previous methods using adversarial representation learning for privacy only aims at obfuscating the sensitive information, we find that adding new information in its place can improve the strength of the provided privacy. We propose a method building on generative adversarial networks that has two steps in the data privatization. In the first step, sensitive data is removed from the representation. In the second step, a sample which is independent of the input data is inserted in its place. The result is an approach that can provide stronger privatization on image data, and yet be preserving both the domain and the utility of the inputs.