 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregation Strategies for Efficient Annotation of Bioacoustic Sound Events Using Active Learning
Mar 04, 2025The vast amounts of audio data collected in Sound Event Detection (SED) applications require efficient annotation strategies to enable supervised learning. Manual labeling is expensive and time-consuming, making Active Learning (AL) a promising approach for reducing annotation effort. We introduce Top K Entropy, a novel uncertainty aggregation strategy for AL that prioritizes the most uncertain segments within an audio recording, instead of averaging uncertainty across all segments. This approach enables the selection of entire recordings for annotation, improving efficiency in sparse data scenarios. We compare Top K Entropy to random sampling and Mean Entropy, and show that fewer labels can lead to the same model performance, particularly in datasets with sparse sound events. Evaluations are conducted on audio mixtures of sound recordings from parks with meerkat, dog, and baby crying sound events, representing real-world bioacoustic monitoring scenarios. Using Top K Entropy for active learning, we can achieve comparable performance to training on the fully labeled dataset with only 8% of the labels. Top K Entropy outperforms Mean Entropy, suggesting that it is best to let the most uncertain segments represent the uncertainty of an audio file. The findings highlight the potential of AL for scalable annotation in audio and time-series applications, including bioacoustics.
The Accuracy Cost of Weakness: A Theoretical Analysis of Fixed-Segment Weak Labeling for Events in Time
Feb 13, 2025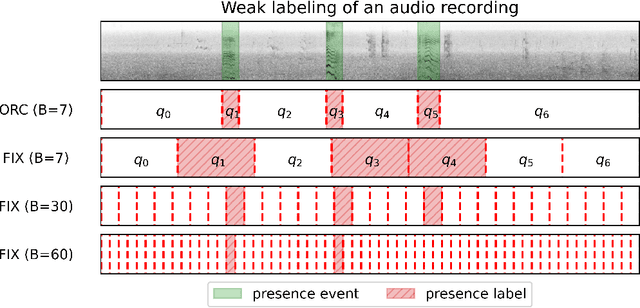

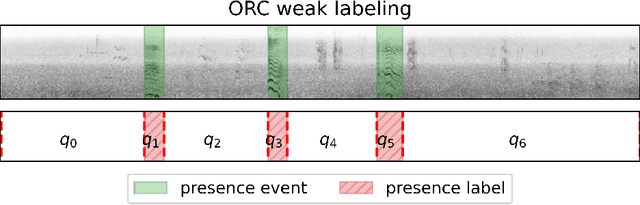
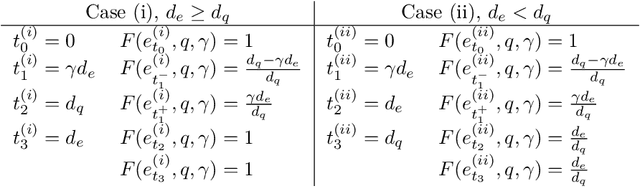
Accurate labels are critical for deriving robust machine learning models. Labels are used to train supervised learning models and to evaluate most machine learning paradigms. In this paper, we model the accuracy and cost of a common weak labeling process where annotators assign presence or absence labels to fixed-length data segments for a given event class. The annotator labels a segment as "present" if it sufficiently covers an event from that class, e.g., a birdsong sound event in audio data. We analyze how the segment length affects the label accuracy and the required number of annotations, and compare this fixed-length labeling approach with an oracle method that uses the true event activations to construct the segments. Furthermore, we quantify the gap between these methods and verify that in most realistic scenarios the oracle method is better than the fixed-length labeling method in both accuracy and cost. Our findings provide a theoretical justification for adaptive weak labeling strategies that mimic the oracle process, and a foundation for optimizing weak labeling processes in sequence labeling tasks.
From Weak to Strong Sound Event Labels using Adaptive Change-Point Detection and Active Learning
Mar 13, 2024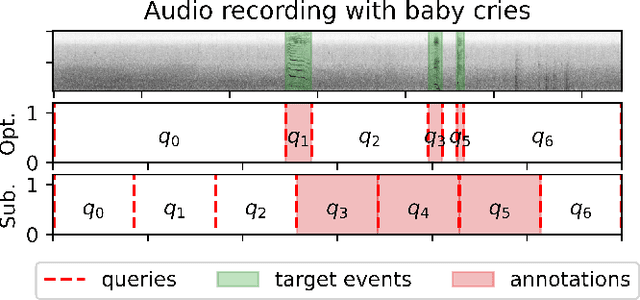

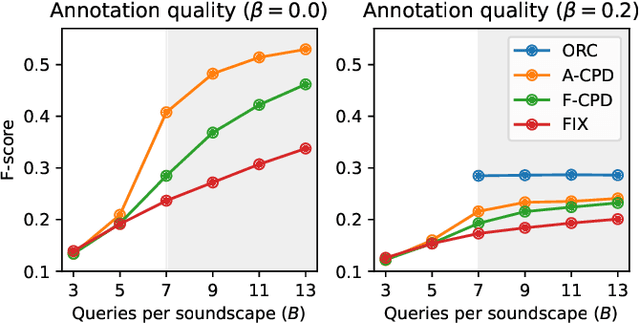
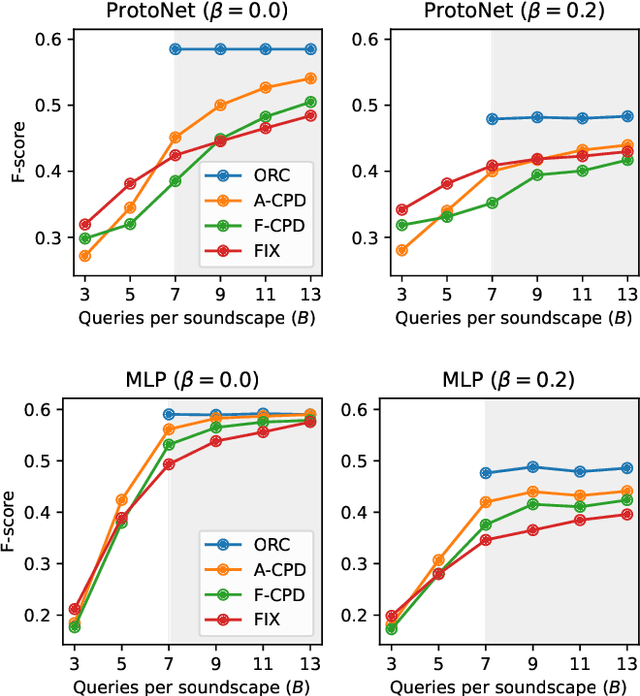
In this work we propose an audio recording segmentation method based on an adaptive change point detection (A-CPD) for machine guided weak label annotation of audio recording segments. The goal is to maximize the amount of information gained about the temporal activation's of the target sounds. For each unlabeled audio recording, we use a prediction model to derive a probability curve used to guide annotation. The prediction model is initially pre-trained on available annotated sound event data with classes that are disjoint from the classes in the unlabeled dataset. The prediction model then gradually adapts to the annotations provided by the annotator in an active learning loop. The queries used to guide the weak label annotator towards strong labels are derived using change point detection on these probabilities. We show that it is possible to derive strong labels of high quality even with a limited annotation budget, and show favorable results for A-CPD when compared to two baseline query strategies.
Impacts of Color and Texture Distortions on Earth Observation Data in Deep Learning
Mar 07, 2024



Land cover classification and change detection are two important applications of remote sensing and Earth observation (EO) that have benefited greatly from the advances of deep learning. Convolutional and transformer-based U-net models are the state-of-the-art architectures for these tasks, and their performances have been boosted by an increased availability of large-scale annotated EO datasets. However, the influence of different visual characteristics of the input EO data on a model's predictions is not well understood. In this work we systematically examine model sensitivities with respect to several color- and texture-based distortions on the input EO data during inference, given models that have been trained without such distortions. We conduct experiments with multiple state-of-the-art segmentation networks for land cover classification and show that they are in general more sensitive to texture than to color distortions. Beyond revealing intriguing characteristics of widely used land cover classification models, our results can also be used to guide the development of more robust models within the EO domain.
Federated learning using a mixture of experts
Oct 05, 2020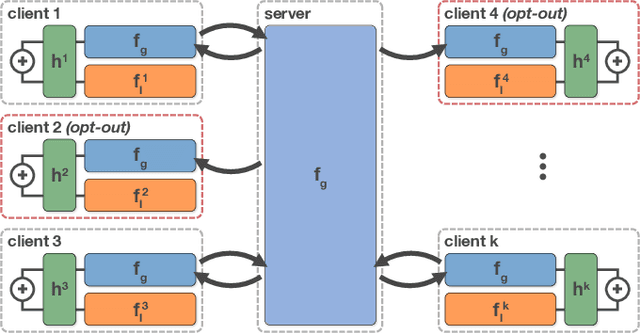

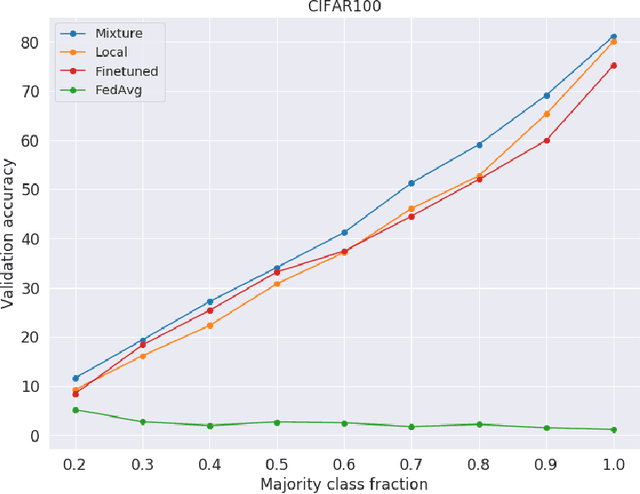

Federated learning has received attention for its efficiency and privacy benefits, in settings where data is distributed among devices. Although federated learning shows significant promise as a key approach when data cannot be shared or centralized, current incarnations show limited privacy properties and have shortcomings when applied to common real-world scenarios. One such scenario is heterogeneous data among devices, where data may come from different generating distributions. In this paper, we propose a federated learning framework using a mixture of experts to balance the specialist nature of a locally trained model with the generalist knowledge of a global model in a federated learning setting. Our results show that the mixture of experts model is better suited as a personalized model for devices when data is heterogeneous, outperforming both global and local models. Furthermore, our framework gives strict privacy guarantees, which allows clients to select parts of their data that may be excluded from the federation. The evaluation shows that the proposed solution is robust to the setting where some users require a strict privacy setting and do not disclose their models to a central server at all, opting out from the federation partially or entirely. The proposed framework is general enough to include any kind of machine learning models, and can even use combinations of different kinds.
Adversarial representation learning for synthetic replacement of private attributes
Jun 23, 2020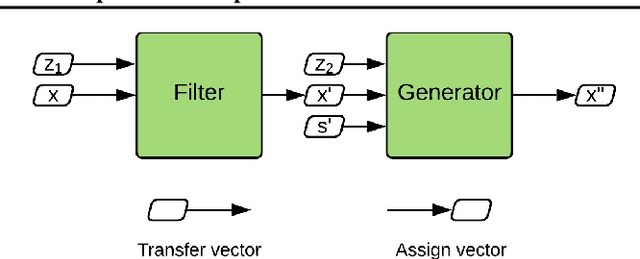
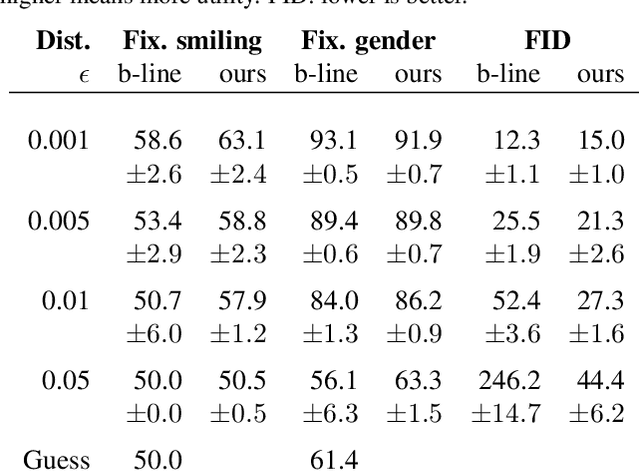
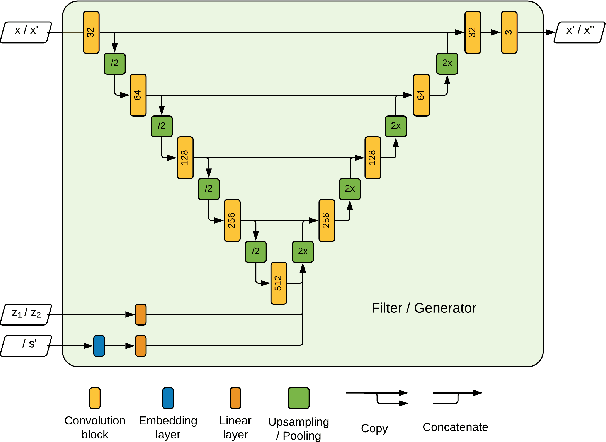
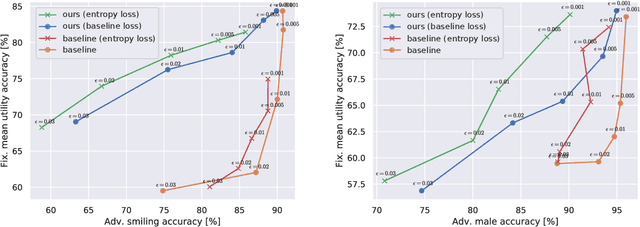
The collection of large datasets allows for advanced analytics that can lead to improved quality of life and progress in applications such as machine cognition and medical analysis. However, recently there has been an increased pressure to guarantee the privacy of users when collecting data. In this work, we study how adversarial representation learning can be used to ensure the privacy of users, and to obfuscate sensitive attributes in existing datasets. While previous methods using adversarial representation learning for privacy only aims at obfuscating the sensitive information, we find that adding new information in its place can improve the strength of the provided privacy. We propose a method building on generative adversarial networks that has two steps in the data privatization. In the first step, sensitive data is removed from the representation. In the second step, a sample which is independent of the input data is inserted in its place. The result is an approach that can provide stronger privatization on image data, and yet be preserving both the domain and the utility of the inputs.
Adversarial representation learning for private speech generation
Jun 17, 2020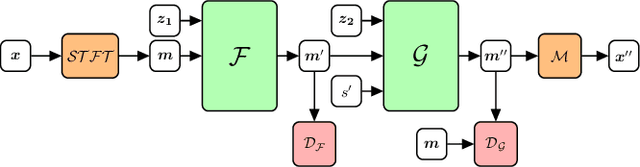
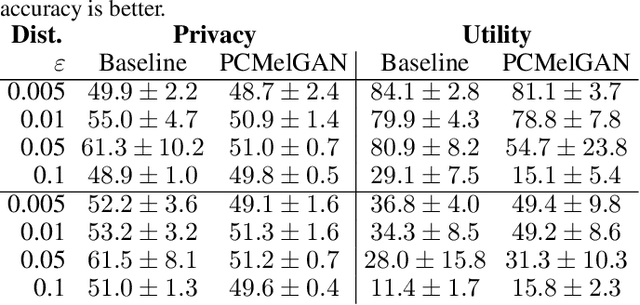
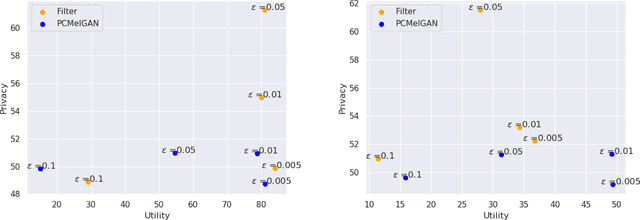

As more and more data is collected in various settings across organizations, companies, and countries, there has been an increase in the demand of user privacy. Developing privacy preserving methods for data analytics is thus an important area of research. In this work we present a model based on generative adversarial networks (GANs) that learns to obfuscate specific sensitive attributes in speech data. We train a model that learns to hide sensitive information in the data, while preserving the meaning in the utterance. The model is trained in two steps: first to filter sensitive information in the spectrogram domain, and then to generate new and private information independent of the filtered one. The model is based on a U-Net CNN that takes mel-spectrograms as input. A MelGAN is used to invert the spectrograms back to raw audio waveforms. We show that it is possible to hide sensitive information such as gender by generating new data, trained adversarially to maintain utility and realism.