 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpacts of Color and Texture Distortions on Earth Observation Data in Deep Learning
Mar 07, 2024



Land cover classification and change detection are two important applications of remote sensing and Earth observation (EO) that have benefited greatly from the advances of deep learning. Convolutional and transformer-based U-net models are the state-of-the-art architectures for these tasks, and their performances have been boosted by an increased availability of large-scale annotated EO datasets. However, the influence of different visual characteristics of the input EO data on a model's predictions is not well understood. In this work we systematically examine model sensitivities with respect to several color- and texture-based distortions on the input EO data during inference, given models that have been trained without such distortions. We conduct experiments with multiple state-of-the-art segmentation networks for land cover classification and show that they are in general more sensitive to texture than to color distortions. Beyond revealing intriguing characteristics of widely used land cover classification models, our results can also be used to guide the development of more robust models within the EO domain.
Concept-aware clustering for decentralized deep learning under temporal shift
Jun 22, 2023
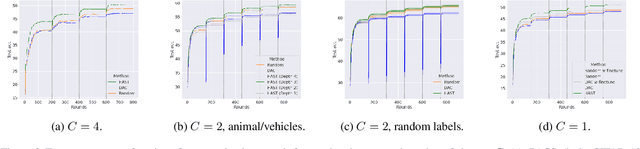
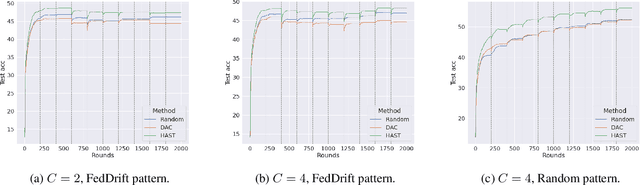
Decentralized deep learning requires dealing with non-iid data across clients, which may also change over time due to temporal shifts. While non-iid data has been extensively studied in distributed settings, temporal shifts have received no attention. To the best of our knowledge, we are first with tackling the novel and challenging problem of decentralized learning with non-iid and dynamic data. We propose a novel algorithm that can automatically discover and adapt to the evolving concepts in the network, without any prior knowledge or estimation of the number of concepts. We evaluate our algorithm on standard benchmark datasets and demonstrate that it outperforms previous methods for decentralized learning.
Decentralized adaptive clustering of deep nets is beneficial for client collaboration
Jun 17, 2022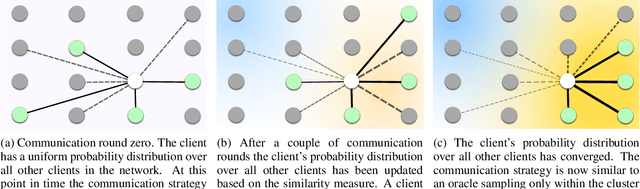
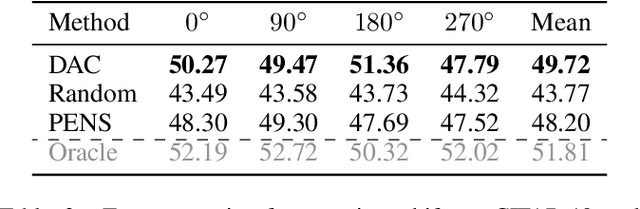
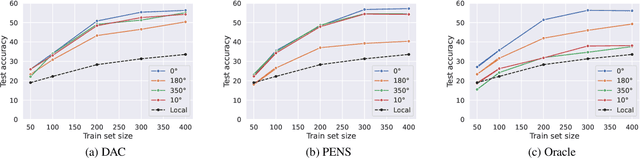

We study the problem of training personalized deep learning models in a decentralized peer-to-peer setting, focusing on the setting where data distributions differ between the clients and where different clients have different local learning tasks. We study both covariate and label shift, and our contribution is an algorithm which for each client finds beneficial collaborations based on a similarity estimate for the local task. Our method does not rely on hyperparameters which are hard to estimate, such as the number of client clusters, but rather continuously adapts to the network topology using soft cluster assignment based on a novel adaptive gossip algorithm. We test the proposed method in various settings where data is not independent and identically distributed among the clients. The experimental evaluation shows that the proposed method performs better than previous state-of-the-art algorithms for this problem setting, and handles situations well where previous methods fail.
Using Time-Series Privileged Information for Provably Efficient Learning of Prediction Models
Oct 28, 2021



We study prediction of future outcomes with supervised models that use privileged information during learning. The privileged information comprises samples of time series observed between the baseline time of prediction and the future outcome; this information is only available at training time which differs from the traditional supervised learning. Our question is when using this privileged data leads to more sample-efficient learning of models that use only baseline data for predictions at test time. We give an algorithm for this setting and prove that when the time series are drawn from a non-stationary Gaussian-linear dynamical system of fixed horizon, learning with privileged information is more efficient than learning without it. On synthetic data, we test the limits of our algorithm and theory, both when our assumptions hold and when they are violated. On three diverse real-world datasets, we show that our approach is generally preferable to classical learning, particularly when data is scarce. Finally, we relate our estimator to a distillation approach both theoretically and empirically.