 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Observational Studies with Experimental Data under Right-Censoring
Feb 23, 2024



Drawing causal inferences from observational studies (OS) requires unverifiable validity assumptions; however, one can falsify those assumptions by benchmarking the OS with experimental data from a randomized controlled trial (RCT). A major limitation of existing procedures is not accounting for censoring, despite the abundance of RCTs and OSes that report right-censored time-to-event outcomes. We consider two cases where censoring time (1) is independent of time-to-event and (2) depends on time-to-event the same way in OS and RCT. For the former, we adopt a censoring-doubly-robust signal for the conditional average treatment effect (CATE) to facilitate an equivalence test of CATEs in OS and RCT, which serves as a proxy for testing if the validity assumptions hold. For the latter, we show that the same test can still be used even though unbiased CATE estimation may not be possible. We verify the effectiveness of our censoring-aware tests via semi-synthetic experiments and analyze RCT and OS data from the Women's Health Initiative study.
Conformalized Unconditional Quantile Regression
Apr 04, 2023
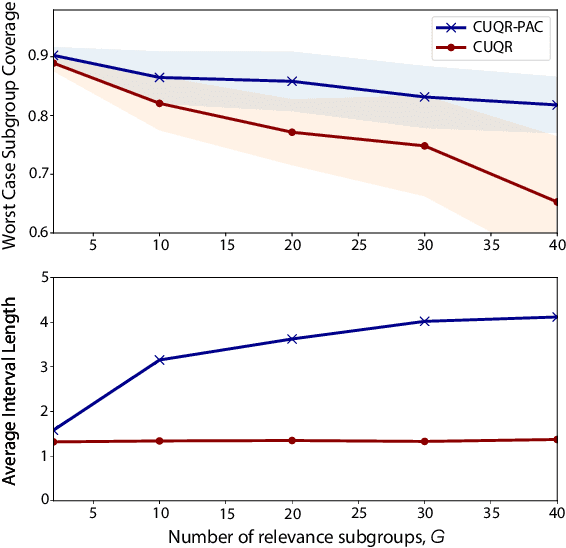


We develop a predictive inference procedure that combines conformal prediction (CP) with unconditional quantile regression (QR) -- a commonly used tool in econometrics that involves regressing the recentered influence function (RIF) of the quantile functional over input covariates. Unlike the more widely-known conditional QR, unconditional QR explicitly captures the impact of changes in covariate distribution on the quantiles of the marginal distribution of outcomes. Leveraging this property, our procedure issues adaptive predictive intervals with localized frequentist coverage guarantees. It operates by fitting a machine learning model for the RIFs using training data, and then applying the CP procedure for any test covariate with respect to a ``hypothetical'' covariate distribution localized around the new instance. Experiments show that our procedure is adaptive to heteroscedasticity, provides transparent coverage guarantees that are relevant to the test instance at hand, and performs competitively with existing methods in terms of efficiency.
Falsification of Internal and External Validity in Observational Studies via Conditional Moment Restrictions
Jan 30, 2023



Randomized Controlled Trials (RCT)s are relied upon to assess new treatments, but suffer from limited power to guide personalized treatment decisions. On the other hand, observational (i.e., non-experimental) studies have large and diverse populations, but are prone to various biases (e.g. residual confounding). To safely leverage the strengths of observational studies, we focus on the problem of falsification, whereby RCTs are used to validate causal effect estimates learned from observational data. In particular, we show that, given data from both an RCT and an observational study, assumptions on internal and external validity have an observable, testable implication in the form of a set of Conditional Moment Restrictions (CMRs). Further, we show that expressing these CMRs with respect to the causal effect, or "causal contrast", as opposed to individual counterfactual means, provides a more reliable falsification test. In addition to giving guarantees on the asymptotic properties of our test, we demonstrate superior power and type I error of our approach on semi-synthetic and real world datasets. Our approach is interpretable, allowing a practitioner to visualize which subgroups in the population lead to falsification of an observational study.
Falsification before Extrapolation in Causal Effect Estimation
Sep 29, 2022
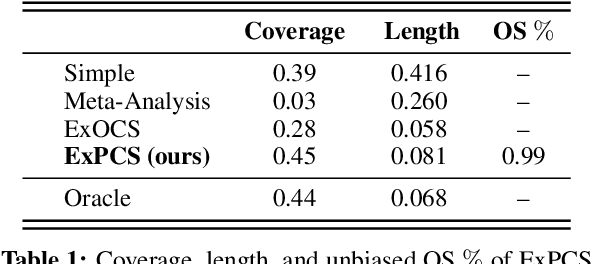
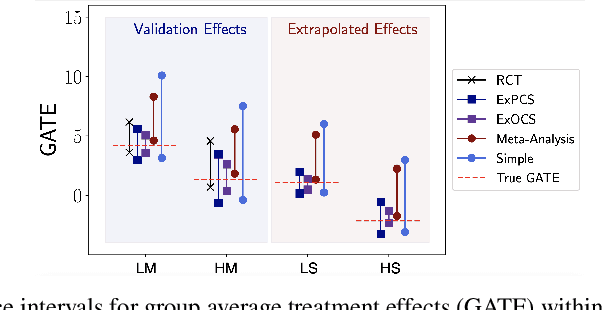

Randomized Controlled Trials (RCTs) represent a gold standard when developing policy guidelines. However, RCTs are often narrow, and lack data on broader populations of interest. Causal effects in these populations are often estimated using observational datasets, which may suffer from unobserved confounding and selection bias. Given a set of observational estimates (e.g. from multiple studies), we propose a meta-algorithm that attempts to reject observational estimates that are biased. We do so using validation effects, causal effects that can be inferred from both RCT and observational data. After rejecting estimators that do not pass this test, we generate conservative confidence intervals on the extrapolated causal effects for subgroups not observed in the RCT. Under the assumption that at least one observational estimator is asymptotically normal and consistent for both the validation and extrapolated effects, we provide guarantees on the coverage probability of the intervals output by our algorithm. To facilitate hypothesis testing in settings where causal effect transportation across datasets is necessary, we give conditions under which a doubly-robust estimator of group average treatment effects is asymptotically normal, even when flexible machine learning methods are used for estimation of nuisance parameters. We illustrate the properties of our approach on semi-synthetic and real world datasets, and show that it compares favorably to standard meta-analysis techniques.
Using Time-Series Privileged Information for Provably Efficient Learning of Prediction Models
Oct 28, 2021



We study prediction of future outcomes with supervised models that use privileged information during learning. The privileged information comprises samples of time series observed between the baseline time of prediction and the future outcome; this information is only available at training time which differs from the traditional supervised learning. Our question is when using this privileged data leads to more sample-efficient learning of models that use only baseline data for predictions at test time. We give an algorithm for this setting and prove that when the time series are drawn from a non-stationary Gaussian-linear dynamical system of fixed horizon, learning with privileged information is more efficient than learning without it. On synthetic data, we test the limits of our algorithm and theory, both when our assumptions hold and when they are violated. On three diverse real-world datasets, we show that our approach is generally preferable to classical learning, particularly when data is scarce. Finally, we relate our estimator to a distillation approach both theoretically and empirically.
Neural Pharmacodynamic State Space Modeling
Feb 22, 2021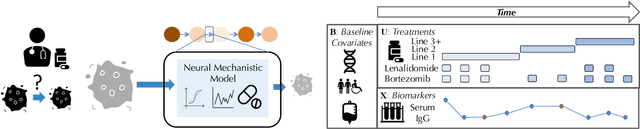
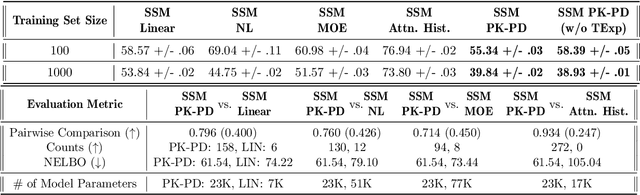
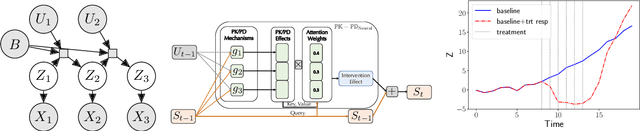
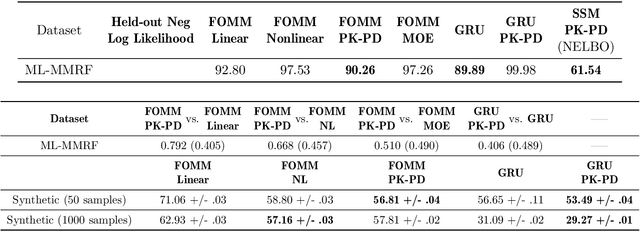
Modeling the time-series of high-dimensional, longitudinal data is important for predicting patient disease progression. However, existing neural network based approaches that learn representations of patient state, while very flexible, are susceptible to overfitting. We propose a deep generative model that makes use of a novel attention-based neural architecture inspired by the physics of how treatments affect disease state. The result is a scalable and accurate model of high-dimensional patient biomarkers as they vary over time. Our proposed model yields significant improvements in generalization and, on real-world clinical data, provides interpretable insights into the dynamics of cancer progression.
Learning to Compose Domain-Specific Transformations for Data Augmentation
Sep 30, 2017
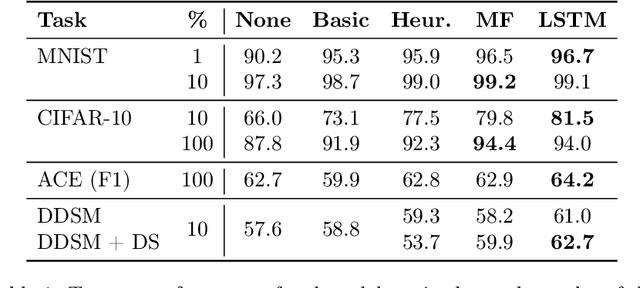
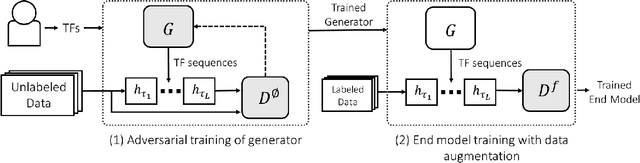

Data augmentation is a ubiquitous technique for increasing the size of labeled training sets by leveraging task-specific data transformations that preserve class labels. While it is often easy for domain experts to specify individual transformations, constructing and tuning the more sophisticated compositions typically needed to achieve state-of-the-art results is a time-consuming manual task in practice. We propose a method for automating this process by learning a generative sequence model over user-specified transformation functions using a generative adversarial approach. Our method can make use of arbitrary, non-deterministic transformation functions, is robust to misspecified user input, and is trained on unlabeled data. The learned transformation model can then be used to perform data augmentation for any end discriminative model. In our experiments, we show the efficacy of our approach on both image and text datasets, achieving improvements of 4.0 accuracy points on CIFAR-10, 1.4 F1 points on the ACE relation extraction task, and 3.4 accuracy points when using domain-specific transformation operations on a medical imaging dataset as compared to standard heuristic augmentation approaches.
Bidirectional American Sign Language to English Translation
Jan 10, 2017

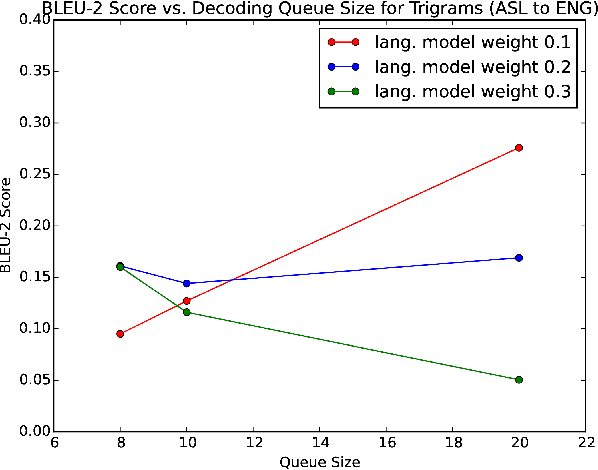
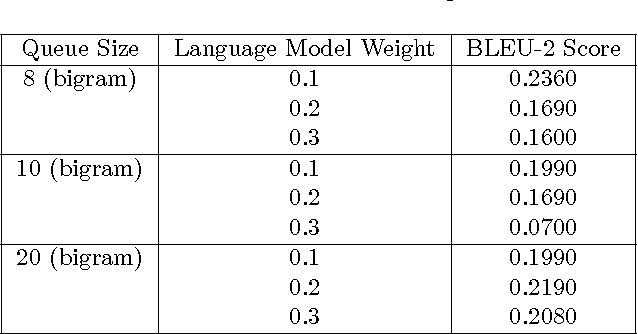
We outline a bidirectional translation system that converts sentences from American Sign Language (ASL) to English, and vice versa. To perform machine translation between ASL and English, we utilize a generative approach. Specifically, we employ an adjustment to the IBM word-alignment model 1 (IBM WAM1), where we define language models for English and ASL, as well as a translation model, and attempt to generate a translation that maximizes the posterior distribution defined by these models. Then, using these models, we are able to quantify the concepts of fluency and faithfulness of a translation between languages.
Group Visual Sentiment Analysis
Jan 07, 2017


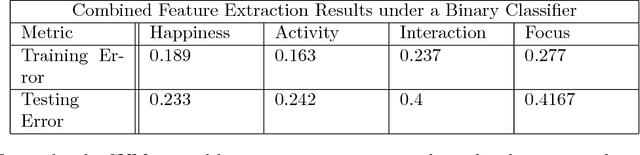
In this paper, we introduce a framework for classifying images according to high-level sentiment. We subdivide the task into three primary problems: emotion classification on faces, human pose estimation, and 3D estimation and clustering of groups of people. We introduce novel algorithms for matching body parts to a common individual and clustering people in images based on physical location and orientation. Our results outperform several baseline approaches.
DeepFace: Face Generation using Deep Learning
Jan 07, 2017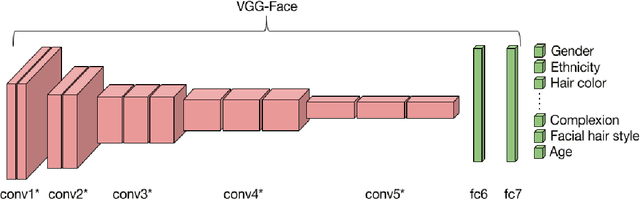



We use CNNs to build a system that both classifies images of faces based on a variety of different facial attributes and generates new faces given a set of desired facial characteristics. After introducing the problem and providing context in the first section, we discuss recent work related to image generation in Section 2. In Section 3, we describe the methods used to fine-tune our CNN and generate new images using a novel approach inspired by a Gaussian mixture model. In Section 4, we discuss our working dataset and describe our preprocessing steps and handling of facial attributes. Finally, in Sections 5, 6 and 7, we explain our experiments and results and conclude in the following section. Our classification system has 82\% test accuracy. Furthermore, our generation pipeline successfully creates well-formed faces.