 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Bidirectional American Sign Language to English Translation
Jan 10, 2017

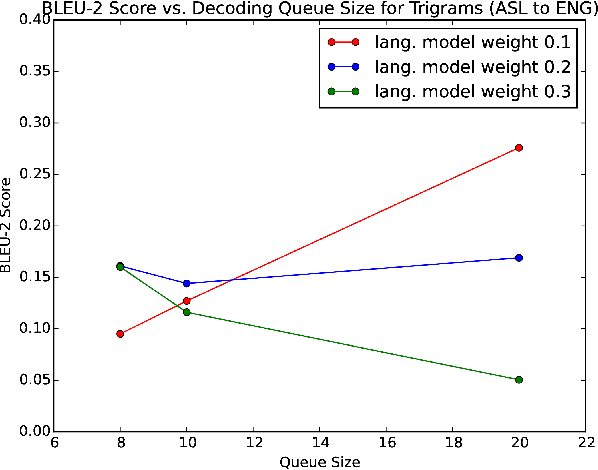
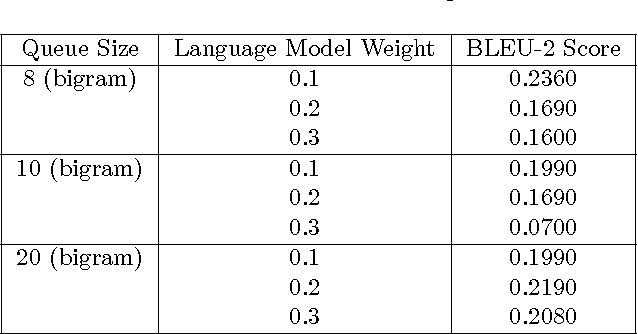
We outline a bidirectional translation system that converts sentences from American Sign Language (ASL) to English, and vice versa. To perform machine translation between ASL and English, we utilize a generative approach. Specifically, we employ an adjustment to the IBM word-alignment model 1 (IBM WAM1), where we define language models for English and ASL, as well as a translation model, and attempt to generate a translation that maximizes the posterior distribution defined by these models. Then, using these models, we are able to quantify the concepts of fluency and faithfulness of a translation between languages.
Group Visual Sentiment Analysis
Jan 07, 2017


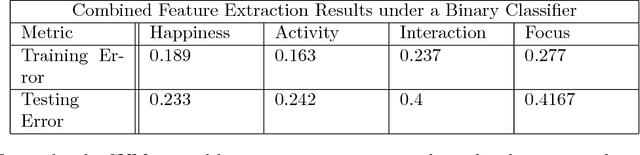
In this paper, we introduce a framework for classifying images according to high-level sentiment. We subdivide the task into three primary problems: emotion classification on faces, human pose estimation, and 3D estimation and clustering of groups of people. We introduce novel algorithms for matching body parts to a common individual and clustering people in images based on physical location and orientation. Our results outperform several baseline approaches.
DeepFace: Face Generation using Deep Learning
Jan 07, 2017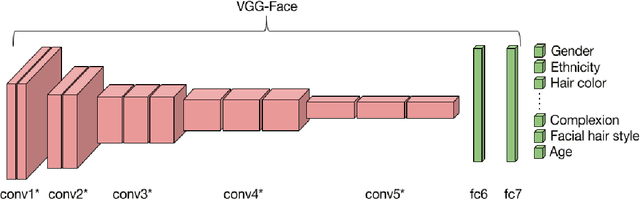



We use CNNs to build a system that both classifies images of faces based on a variety of different facial attributes and generates new faces given a set of desired facial characteristics. After introducing the problem and providing context in the first section, we discuss recent work related to image generation in Section 2. In Section 3, we describe the methods used to fine-tune our CNN and generate new images using a novel approach inspired by a Gaussian mixture model. In Section 4, we discuss our working dataset and describe our preprocessing steps and handling of facial attributes. Finally, in Sections 5, 6 and 7, we explain our experiments and results and conclude in the following section. Our classification system has 82\% test accuracy. Furthermore, our generation pipeline successfully creates well-formed faces.
Sign Language Recognition Using Temporal Classification
Jan 07, 2017


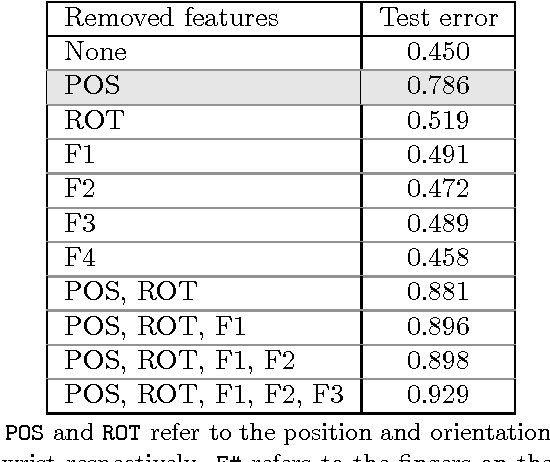
Devices like the Myo armband available in the market today enable us to collect data about the position of a user's hands and fingers over time. We can use these technologies for sign language translation since each sign is roughly a combination of gestures across time. In this work, we utilize a dataset collected by a group at the University of South Wales, which contains parameters, such as hand position, hand rotation, and finger bend, for 95 unique signs. For each input stream representing a sign, we predict which sign class this stream falls into. We begin by implementing baseline SVM and logistic regression models, which perform reasonably well on high quality data. Lower quality data requires a more sophisticated approach, so we explore different methods in temporal classification, including long short term memory architectures and sequential pattern mining methods.