 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupling Speech Encoders with Downstream Text Models
Jul 24, 2024



We present a modular approach to building cascade speech translation (AST) models that guarantees that the resulting model performs no worse than the 1-best cascade baseline while preserving state-of-the-art speech recognition (ASR) and text translation (MT) performance for a given task. Our novel contribution is the use of an ``exporter'' layer that is trained under L2-loss to ensure a strong match between ASR embeddings and the MT token embeddings for the 1-best sequence. The ``exporter'' output embeddings are fed directly to the MT model in lieu of 1-best token embeddings, thus guaranteeing that the resulting model performs no worse than the 1-best cascade baseline, while allowing back-propagation gradient to flow from the MT model into the ASR components. The matched-embeddings cascade architecture provide a significant improvement over its 1-best counterpart in scenarios where incremental training of the MT model is not an option and yet we seek to improve quality by leveraging (speech, transcription, translated transcription) data provided with the AST task. The gain disappears when the MT model is incrementally trained on the parallel text data available with the AST task. The approach holds promise for other scenarios that seek to couple ASR encoders and immutable text models, such at large language models (LLM).
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
SLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023



We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023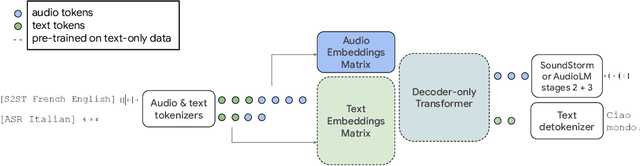



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
Lego-Features: Exporting modular encoder features for streaming and deliberation ASR
Mar 31, 2023In end-to-end (E2E) speech recognition models, a representational tight-coupling inevitably emerges between the encoder and the decoder. We build upon recent work that has begun to explore building encoders with modular encoded representations, such that encoders and decoders from different models can be stitched together in a zero-shot manner without further fine-tuning. While previous research only addresses full-context speech models, we explore the problem in a streaming setting as well. Our framework builds on top of existing encoded representations, converting them to modular features, dubbed as Lego-Features, without modifying the pre-trained model. The features remain interchangeable when the model is retrained with distinct initializations. Though sparse, we show that the Lego-Features are powerful when tested with RNN-T or LAS decoders, maintaining high-quality downstream performance. They are also rich enough to represent the first-pass prediction during two-pass deliberation. In this scenario, they outperform the N-best hypotheses, since they do not need to be supplemented with acoustic features to deliver the best results. Moreover, generating the Lego-Features does not require beam search or auto-regressive computation. Overall, they present a modular, powerful and cheap alternative to the standard encoder output, as well as the N-best hypotheses.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
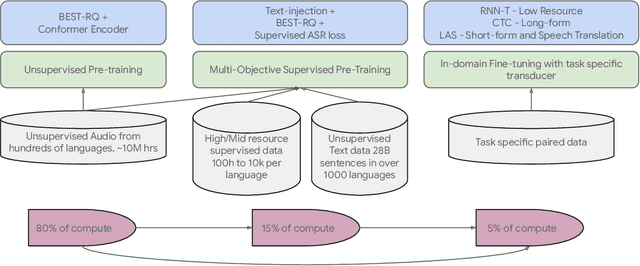
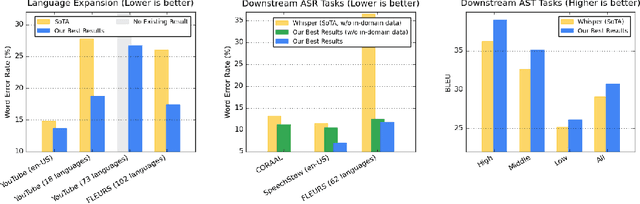

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.