 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Multiple Wasserstein Gradient Flows for Multi-objective Distributional Optimization
Jan 27, 2026We study multi-objective optimization over probability distributions in Wasserstein space. Recently, Nguyen et al. (2025) introduced Multiple Wasserstein Gradient Descent (MWGraD) algorithm, which exploits the geometric structure of Wasserstein space to jointly optimize multiple objectives. Building on this approach, we propose an accelerated variant, A-MWGraD, inspired by Nesterov's acceleration. We analyze the continuous-time dynamics and establish convergence to weakly Pareto optimal points in probability space. Our theoretical results show that A-MWGraD achieves a convergence rate of O(1/t^2) for geodesically convex objectives and O(e^{-\sqrtβt}) for $β$-strongly geodesically convex objectives, improving upon the O(1/t) rate of MWGraD in the geodesically convex setting. We further introduce a practical kernel-based discretization for A-MWGraD and demonstrate through numerical experiments that it consistently outperforms MWGraD in convergence speed and sampling efficiency on multi-target sampling tasks.
Mono3DV: Monocular 3D Object Detection with 3D-Aware Bipartite Matching and Variational Query DeNoising
Jan 03, 2026While DETR-like architectures have demonstrated significant potential for monocular 3D object detection, they are often hindered by a critical limitation: the exclusion of 3D attributes from the bipartite matching process. This exclusion arises from the inherent ill-posed nature of 3D estimation from monocular image, which introduces instability during training. Consequently, high-quality 3D predictions can be erroneously suppressed by 2D-only matching criteria, leading to suboptimal results. To address this, we propose Mono3DV, a novel Transformer-based framework. Our approach introduces three key innovations. First, we develop a 3D-Aware Bipartite Matching strategy that directly incorporates 3D geometric information into the matching cost, resolving the misalignment caused by purely 2D criteria. Second, it is important to stabilize the Bipartite Matching to resolve the instability occurring when integrating 3D attributes. Therefore, we propose 3D-DeNoising scheme in the training phase. Finally, recognizing the gradient vanishing issue associated with conventional denoising techniques, we propose a novel Variational Query DeNoising mechanism to overcome this limitation, which significantly enhances model performance. Without leveraging any external data, our method achieves state-of-the-art results on the KITTI 3D object detection benchmark.
SoftCTRL: Soft conservative KL-control of Transformer Reinforcement Learning for Autonomous Driving
Oct 30, 2024



In recent years, motion planning for urban self-driving cars (SDV) has become a popular problem due to its complex interaction of road components. To tackle this, many methods have relied on large-scale, human-sampled data processed through Imitation learning (IL). Although effective, IL alone cannot adequately handle safety and reliability concerns. Combining IL with Reinforcement learning (RL) by adding KL divergence between RL and IL policy to the RL loss can alleviate IL's weakness but suffer from over-conservation caused by covariate shift of IL. To address this limitation, we introduce a method that combines IL with RL using an implicit entropy-KL control that offers a simple way to reduce the over-conservation characteristic. In particular, we validate different challenging simulated urban scenarios from the unseen dataset, indicating that although IL can perform well in imitation tasks, our proposed method significantly improves robustness (over 17\% reduction in failures) and generates human-like driving behavior.
Wanna Hear Your Voice: Adaptive, Effective, and Language-Agnostic Approach in Voice Extraction
Oct 01, 2024The research on audio clue-based target speaker extraction (TSE) has mostly focused on modeling the mixture and reference speech, achieving high performance in English due to the availability of large datasets. However, less attention has been given to the consistent properties of human speech across languages. To bridge this gap, we introduce WHYV (Wanna Hear Your Voice), which addresses the challenge of transferring TSE models from one language to another without fine-tuning. In this work, we proposed a gating mechanism that be able to modify specific frequencies based on the speaker's acoustic features. The model achieves an SI-SDR of 17.3544 on clean English speech and 13.2032 on clean speech mixed with Wham! noise, outperforming all other models in its ability to adapt to different languages.
Semi-supervised 3D Semantic Scene Completion with 2D Vision Foundation Model Guidance
Aug 21, 2024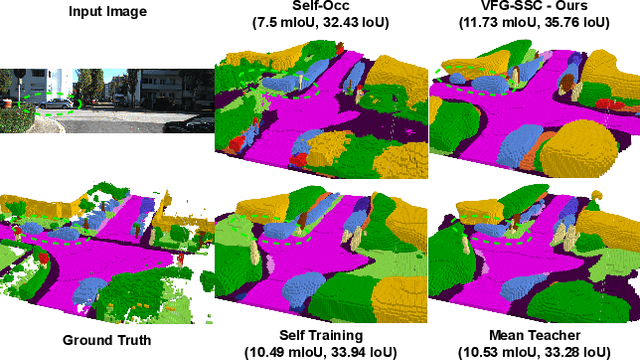
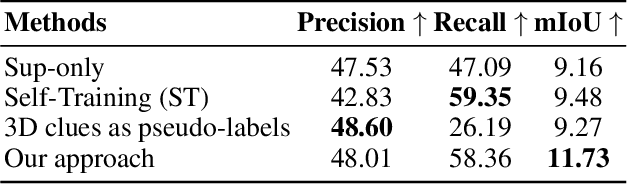
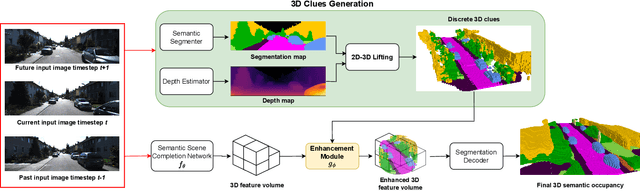
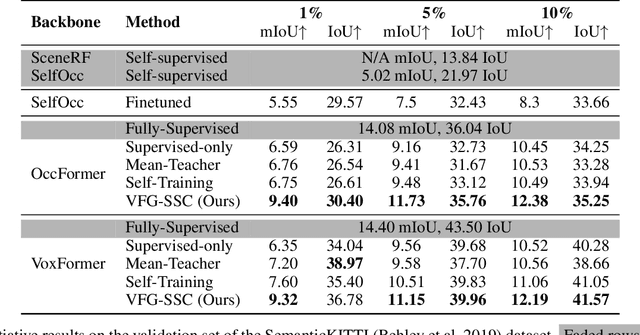
Accurate prediction of 3D semantic occupancy from 2D visual images is vital in enabling autonomous agents to comprehend their surroundings for planning and navigation. State-of-the-art methods typically employ fully supervised approaches, necessitating a huge labeled dataset acquired through expensive LiDAR sensors and meticulous voxel-wise labeling by human annotators. The resource-intensive nature of this annotating process significantly hampers the application and scalability of these methods. We introduce a novel semi-supervised framework to alleviate the dependency on densely annotated data. Our approach leverages 2D foundation models to generate essential 3D scene geometric and semantic cues, facilitating a more efficient training process. Our framework exhibits notable properties: (1) Generalizability, applicable to various 3D semantic scene completion approaches, including 2D-3D lifting and 3D-2D transformer methods. (2) Effectiveness, as demonstrated through experiments on SemanticKITTI and NYUv2, wherein our method achieves up to 85% of the fully-supervised performance using only 10% labeled data. This approach not only reduces the cost and labor associated with data annotation but also demonstrates the potential for broader adoption in camera-based systems for 3D semantic occupancy prediction.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023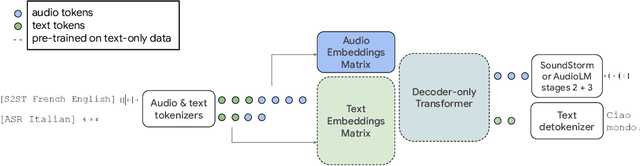



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples