 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeDreamer: Mode Guiding Score Distillation for Text-to-3D Generation using Reference Image Prompts
Nov 27, 2024



Existing Score Distillation Sampling (SDS)-based methods have driven significant progress in text-to-3D generation. However, 3D models produced by SDS-based methods tend to exhibit over-smoothing and low-quality outputs. These issues arise from the mode-seeking behavior of current methods, where the scores used to update the model oscillate between multiple modes, resulting in unstable optimization and diminished output quality. To address this problem, we introduce a novel image prompt score distillation loss named ISD, which employs a reference image to direct text-to-3D optimization toward a specific mode. Our ISD loss can be implemented by using IP-Adapter, a lightweight adapter for integrating image prompt capability to a text-to-image diffusion model, as a mode-selection module. A variant of this adapter, when not being prompted by a reference image, can serve as an efficient control variate to reduce variance in score estimates, thereby enhancing both output quality and optimization stability. Our experiments demonstrate that the ISD loss consistently achieves visually coherent, high-quality outputs and improves optimization speed compared to prior text-to-3D methods, as demonstrated through both qualitative and quantitative evaluations on the T3Bench benchmark suite.
Semi-supervised 3D Semantic Scene Completion with 2D Vision Foundation Model Guidance
Aug 21, 2024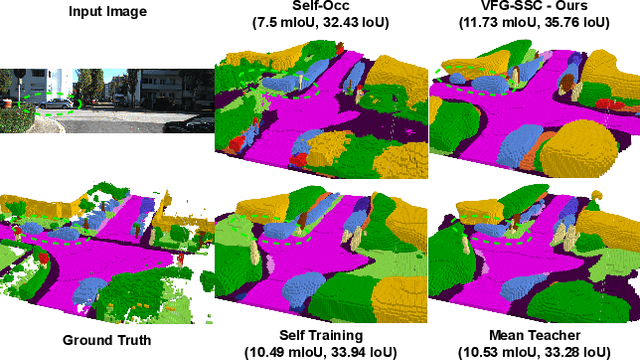
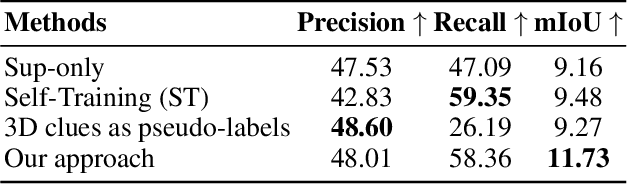
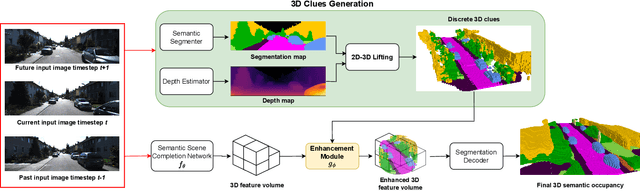
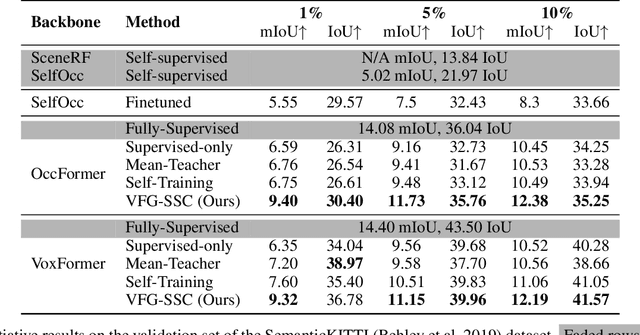
Accurate prediction of 3D semantic occupancy from 2D visual images is vital in enabling autonomous agents to comprehend their surroundings for planning and navigation. State-of-the-art methods typically employ fully supervised approaches, necessitating a huge labeled dataset acquired through expensive LiDAR sensors and meticulous voxel-wise labeling by human annotators. The resource-intensive nature of this annotating process significantly hampers the application and scalability of these methods. We introduce a novel semi-supervised framework to alleviate the dependency on densely annotated data. Our approach leverages 2D foundation models to generate essential 3D scene geometric and semantic cues, facilitating a more efficient training process. Our framework exhibits notable properties: (1) Generalizability, applicable to various 3D semantic scene completion approaches, including 2D-3D lifting and 3D-2D transformer methods. (2) Effectiveness, as demonstrated through experiments on SemanticKITTI and NYUv2, wherein our method achieves up to 85% of the fully-supervised performance using only 10% labeled data. This approach not only reduces the cost and labor associated with data annotation but also demonstrates the potential for broader adoption in camera-based systems for 3D semantic occupancy prediction.