 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftTailor: Efficient 3D Garment Generation with Geometry Image Representation
Mar 19, 2026Realistic and efficient 3D garment generation remains a longstanding challenge in computer vision and digital fashion. Existing methods typically rely on large vision- language models to produce serialized representations of 2D sewing patterns, which are then transformed into simulation-ready 3D meshes using garment modeling framework such as GarmentCode. Although these approaches yield high-quality results, they often suffer from slow inference times, ranging from 30 seconds to a minute. In this work, we introduce SwiftTailor, a novel two-stage framework that unifies sewing-pattern reasoning and geometry-based mesh synthesis through a compact geometry image representation. SwiftTailor comprises two lightweight modules: PatternMaker, an efficient vision-language model that predicts sewing patterns from diverse input modalities, and GarmentSewer, an efficient dense prediction transformer that converts these patterns into a novel Garment Geometry Image, encoding the 3D surface of all garment panels in a unified UV space. The final 3D mesh is reconstructed through an efficient inverse mapping process that incorporates remeshing and dynamic stitching algorithms to directly assemble the garment, thereby amortizing the cost of physical simulation. Extensive experiments on the Multimodal GarmentCodeData demonstrate that SwiftTailor achieves state-of-the-art accuracy and visual fidelity while significantly reducing inference time. This work offers a scalable, interpretable, and high-performance solution for next-generation 3D garment generation.
FROMAT: Multiview Material Appearance Transfer via Few-Shot Self-Attention Adaptation
Dec 10, 2025Multiview diffusion models have rapidly emerged as a powerful tool for content creation with spatial consistency across viewpoints, offering rich visual realism without requiring explicit geometry and appearance representation. However, compared to meshes or radiance fields, existing multiview diffusion models offer limited appearance manipulation, particularly in terms of material, texture, or style. In this paper, we present a lightweight adaptation technique for appearance transfer in multiview diffusion models. Our method learns to combine object identity from an input image with appearance cues rendered in a separate reference image, producing multi-view-consistent output that reflects the desired materials, textures, or styles. This allows explicit specification of appearance parameters at generation time while preserving the underlying object geometry and view coherence. We leverage three diffusion denoising processes responsible for generating the original object, the reference, and the target images, and perform reverse sampling to aggregate a small subset of layer-wise self-attention features from the object and the reference to influence the target generation. Our method requires only a few training examples to introduce appearance awareness to pretrained multiview models. The experiments show that our method provides a simple yet effective way toward multiview generation with diverse appearance, advocating the adoption of implicit generative 3D representations in practice.
AUTV: Creating Underwater Video Datasets with Pixel-wise Annotations
Mar 17, 2025Underwater video analysis, hampered by the dynamic marine environment and camera motion, remains a challenging task in computer vision. Existing training-free video generation techniques, learning motion dynamics on the frame-by-frame basis, often produce poor results with noticeable motion interruptions and misaligments. To address these issues, we propose AUTV, a framework for synthesizing marine video data with pixel-wise annotations. We demonstrate the effectiveness of this framework by constructing two video datasets, namely UTV, a real-world dataset comprising 2,000 video-text pairs, and SUTV, a synthetic video dataset including 10,000 videos with segmentation masks for marine objects. UTV provides diverse underwater videos with comprehensive annotations including appearance, texture, camera intrinsics, lighting, and animal behavior. SUTV can be used to improve underwater downstream tasks, which are demonstrated in video inpainting and video object segmentation.
Color Alignment in Diffusion
Mar 09, 2025Diffusion models have shown great promise in synthesizing visually appealing images. However, it remains challenging to condition the synthesis at a fine-grained level, for instance, synthesizing image pixels following some generic color pattern. Existing image synthesis methods often produce contents that fall outside the desired pixel conditions. To address this, we introduce a novel color alignment algorithm that confines the generative process in diffusion models within a given color pattern. Specifically, we project diffusion terms, either imagery samples or latent representations, into a conditional color space to align with the input color distribution. This strategy simplifies the prediction in diffusion models within a color manifold while still allowing plausible structures in generated contents, thus enabling the generation of diverse contents that comply with the target color pattern. Experimental results demonstrate our state-of-the-art performance in conditioning and controlling of color pixels, while maintaining on-par generation quality and diversity in comparison with regular diffusion models.
LiftRefine: Progressively Refined View Synthesis from 3D Lifting with Volume-Triplane Representations
Dec 19, 2024

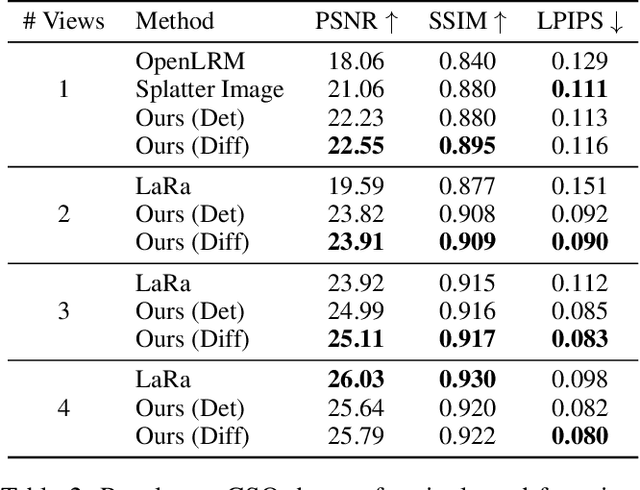

We propose a new view synthesis method via synthesizing a 3D neural field from both single or few-view input images. To address the ill-posed nature of the image-to-3D generation problem, we devise a two-stage method that involves a reconstruction model and a diffusion model for view synthesis. Our reconstruction model first lifts one or more input images to the 3D space from a volume as the coarse-scale 3D representation followed by a tri-plane as the fine-scale 3D representation. To mitigate the ambiguity in occluded regions, our diffusion model then hallucinates missing details in the rendered images from tri-planes. We then introduce a new progressive refinement technique that iteratively applies the reconstruction and diffusion model to gradually synthesize novel views, boosting the overall quality of the 3D representations and their rendering. Empirical evaluation demonstrates the superiority of our method over state-of-the-art methods on the synthetic SRN-Car dataset, the in-the-wild CO3D dataset, and large-scale Objaverse dataset while achieving both sampling efficacy and multi-view consistency.
ModeDreamer: Mode Guiding Score Distillation for Text-to-3D Generation using Reference Image Prompts
Nov 27, 2024



Existing Score Distillation Sampling (SDS)-based methods have driven significant progress in text-to-3D generation. However, 3D models produced by SDS-based methods tend to exhibit over-smoothing and low-quality outputs. These issues arise from the mode-seeking behavior of current methods, where the scores used to update the model oscillate between multiple modes, resulting in unstable optimization and diminished output quality. To address this problem, we introduce a novel image prompt score distillation loss named ISD, which employs a reference image to direct text-to-3D optimization toward a specific mode. Our ISD loss can be implemented by using IP-Adapter, a lightweight adapter for integrating image prompt capability to a text-to-image diffusion model, as a mode-selection module. A variant of this adapter, when not being prompted by a reference image, can serve as an efficient control variate to reduce variance in score estimates, thereby enhancing both output quality and optimization stability. Our experiments demonstrate that the ISD loss consistently achieves visually coherent, high-quality outputs and improves optimization speed compared to prior text-to-3D methods, as demonstrated through both qualitative and quantitative evaluations on the T3Bench benchmark suite.
SharpDepth: Sharpening Metric Depth Predictions Using Diffusion Distillation
Nov 27, 2024

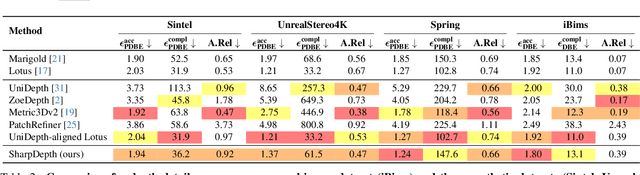

We propose SharpDepth, a novel approach to monocular metric depth estimation that combines the metric accuracy of discriminative depth estimation methods (e.g., Metric3D, UniDepth) with the fine-grained boundary sharpness typically achieved by generative methods (e.g., Marigold, Lotus). Traditional discriminative models trained on real-world data with sparse ground-truth depth can accurately predict metric depth but often produce over-smoothed or low-detail depth maps. Generative models, in contrast, are trained on synthetic data with dense ground truth, generating depth maps with sharp boundaries yet only providing relative depth with low accuracy. Our approach bridges these limitations by integrating metric accuracy with detailed boundary preservation, resulting in depth predictions that are both metrically precise and visually sharp. Our extensive zero-shot evaluations on standard depth estimation benchmarks confirm SharpDepth effectiveness, showing its ability to achieve both high depth accuracy and detailed representation, making it well-suited for applications requiring high-quality depth perception across diverse, real-world environments.
Improving Referring Image Segmentation using Vision-Aware Text Features
Apr 12, 2024


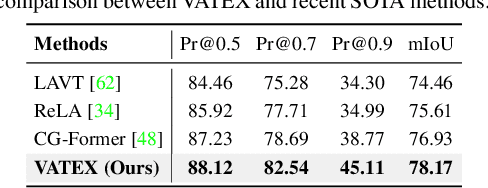
Referring image segmentation is a challenging task that involves generating pixel-wise segmentation masks based on natural language descriptions. Existing methods have relied mostly on visual features to generate the segmentation masks while treating text features as supporting components. This over-reliance on visual features can lead to suboptimal results, especially in complex scenarios where text prompts are ambiguous or context-dependent. To overcome these challenges, we present a novel framework VATEX to improve referring image segmentation by enhancing object and context understanding with Vision-Aware Text Feature. Our method involves using CLIP to derive a CLIP Prior that integrates an object-centric visual heatmap with text description, which can be used as the initial query in DETR-based architecture for the segmentation task. Furthermore, by observing that there are multiple ways to describe an instance in an image, we enforce feature similarity between text variations referring to the same visual input by two components: a novel Contextual Multimodal Decoder that turns text embeddings into vision-aware text features, and a Meaning Consistency Constraint to ensure further the coherent and consistent interpretation of language expressions with the context understanding obtained from the image. Our method achieves a significant performance improvement on three benchmark datasets RefCOCO, RefCOCO+ and G-Ref. Code is available at: https://nero1342.github.io/VATEX\_RIS.
Self-supervised Video Object Segmentation with Distillation Learning of Deformable Attention
Jan 25, 2024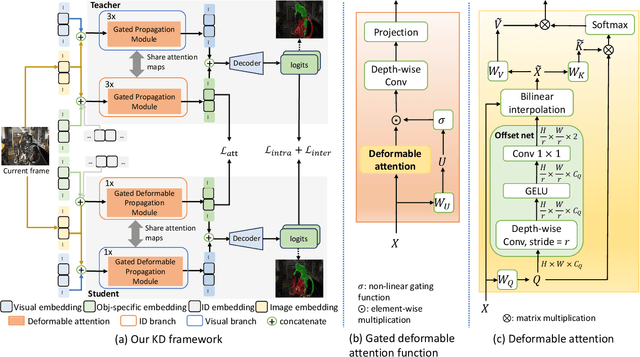



Video object segmentation is a fundamental research problem in computer vision. Recent techniques have often applied attention mechanism to object representation learning from video sequences. However, due to temporal changes in the video data, attention maps may not well align with the objects of interest across video frames, causing accumulated errors in long-term video processing. In addition, existing techniques have utilised complex architectures, requiring highly computational complexity and hence limiting the ability to integrate video object segmentation into low-powered devices. To address these issues, we propose a new method for self-supervised video object segmentation based on distillation learning of deformable attention. Specifically, we devise a lightweight architecture for video object segmentation that is effectively adapted to temporal changes. This is enabled by deformable attention mechanism, where the keys and values capturing the memory of a video sequence in the attention module have flexible locations updated across frames. The learnt object representations are thus adaptive to both the spatial and temporal dimensions. We train the proposed architecture in a self-supervised fashion through a new knowledge distillation paradigm where deformable attention maps are integrated into the distillation loss. We qualitatively and quantitatively evaluate our method and compare it with existing methods on benchmark datasets including DAVIS 2016/2017 and YouTube-VOS 2018/2019. Experimental results verify the superiority of our method via its achieved state-of-the-art performance and optimal memory usage.
Leveraging Open-Vocabulary Diffusion to Camouflaged Instance Segmentation
Dec 29, 2023Text-to-image diffusion techniques have shown exceptional capability of producing high-quality images from text descriptions. This indicates that there exists a strong correlation between the visual and textual domains. In addition, text-image discriminative models such as CLIP excel in image labelling from text prompts, thanks to the rich and diverse information available from open concepts. In this paper, we leverage these technical advances to solve a challenging problem in computer vision: camouflaged instance segmentation. Specifically, we propose a method built upon a state-of-the-art diffusion model, empowered by open-vocabulary to learn multi-scale textual-visual features for camouflaged object representations. Such cross-domain representations are desirable in segmenting camouflaged objects where visual cues are subtle to distinguish the objects from the background, especially in segmenting novel objects which are not seen in training. We also develop technically supportive components to effectively fuse cross-domain features and engage relevant features towards respective foreground objects. We validate our method and compare it with existing ones on several benchmark datasets of camouflaged instance segmentation and generic open-vocabulary instance segmentation. Experimental results confirm the advances of our method over existing ones. We will publish our code and pre-trained models to support future research.