 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Open-Vocabulary Diffusion to Camouflaged Instance Segmentation
Dec 29, 2023Text-to-image diffusion techniques have shown exceptional capability of producing high-quality images from text descriptions. This indicates that there exists a strong correlation between the visual and textual domains. In addition, text-image discriminative models such as CLIP excel in image labelling from text prompts, thanks to the rich and diverse information available from open concepts. In this paper, we leverage these technical advances to solve a challenging problem in computer vision: camouflaged instance segmentation. Specifically, we propose a method built upon a state-of-the-art diffusion model, empowered by open-vocabulary to learn multi-scale textual-visual features for camouflaged object representations. Such cross-domain representations are desirable in segmenting camouflaged objects where visual cues are subtle to distinguish the objects from the background, especially in segmenting novel objects which are not seen in training. We also develop technically supportive components to effectively fuse cross-domain features and engage relevant features towards respective foreground objects. We validate our method and compare it with existing ones on several benchmark datasets of camouflaged instance segmentation and generic open-vocabulary instance segmentation. Experimental results confirm the advances of our method over existing ones. We will publish our code and pre-trained models to support future research.
CDN-MEDAL: Two-stage Density and Difference Approximation Framework for Motion Analysis
Jun 07, 2021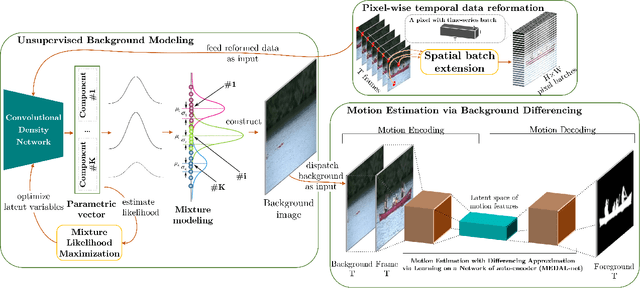
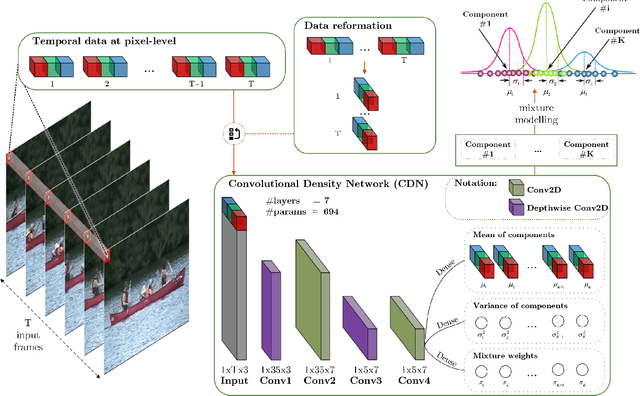


Background modeling is a promising research area in video analysis with a variety of video surveillance applications. Recent years have witnessed the proliferation of deep neural networks via effective learning-based approaches in motion analysis. However, these techniques only provide a limited description of the observed scenes' insufficient properties where a single-valued mapping is learned to approximate the temporal conditional averages of the target background. On the other hand, statistical learning in imagery domains has become one of the most prevalent approaches with high adaptation to dynamic context transformation, notably Gaussian Mixture Models, combined with a foreground extraction step. In this work, we propose a novel, two-stage method of change detection with two convolutional neural networks. The first architecture is grounded on the unsupervised Gaussian mixtures statistical learning to describe the scenes' salient features. The second one implements a light-weight pipeline of foreground detection. Our two-stage framework contains approximately 3.5K parameters in total but still maintains rapid convergence to intricate motion patterns. Our experiments on publicly available datasets show that our proposed networks are not only capable of generalizing regions of moving objects in unseen cases with promising results but also are competitive in performance efficiency and effectiveness regarding foreground segmentation.