 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverseDream: Diverse Text-to-3D Synthesis with Augmented Text Embedding
Dec 02, 2023Text-to-3D synthesis has recently emerged as a new approach to sampling 3D models by adopting pretrained text-to-image models as guiding visual priors. An intriguing but underexplored problem with existing text-to-3D methods is that 3D models obtained from the sampling-by-optimization procedure tend to have mode collapses, and hence poor diversity in their results. In this paper, we provide an analysis and identify potential causes of such a limited diversity, and then devise a new method that considers the joint generation of different 3D models from the same text prompt, where we propose to use augmented text prompts via textual inversion of reference images to diversify the joint generation. We show that our method leads to improved diversity in text-to-3D synthesis qualitatively and quantitatively.
Partially calibrated semi-generalized pose from hybrid point correspondences
Sep 29, 2022
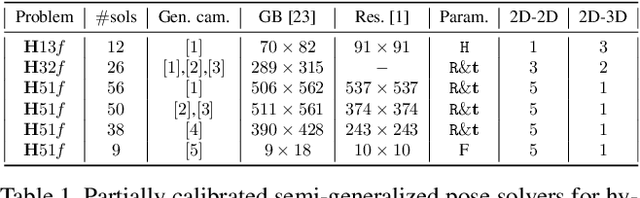
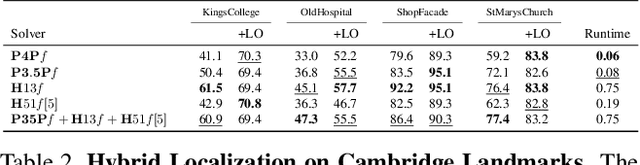
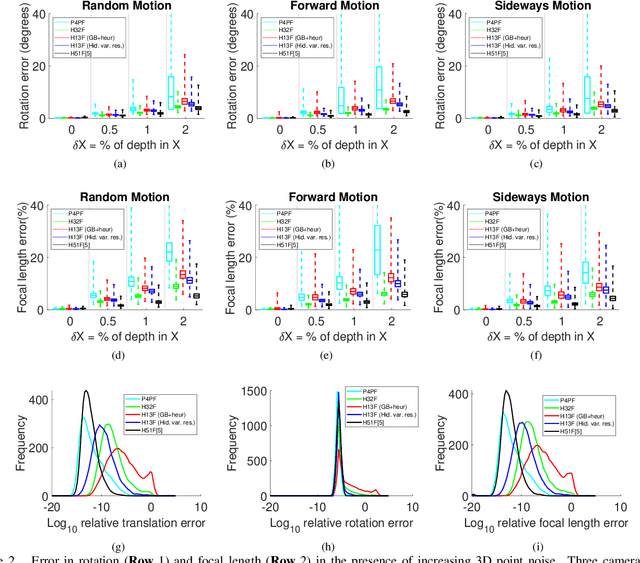
In this paper we study the problem of estimating the semi-generalized pose of a partially calibrated camera, i.e., the pose of a perspective camera with unknown focal length w.r.t. a generalized camera, from a hybrid set of 2D-2D and 2D-3D point correspondences. We study all possible camera configurations within the generalized camera system. To derive practical solvers to previously unsolved challenging configurations, we test different parameterizations as well as different solving strategies based on the state-of-the-art methods for generating efficient polynomial solvers. We evaluate the three most promising solvers, i.e., the H51f solver with five 2D-2D correspondences and one 2D-3D correspondence viewed by the same camera inside generalized camera, the H32f solver with three 2D-2D and two 2D-3D correspondences, and the H13f solver with one 2D-2D and three 2D-3D correspondences, on synthetic and real data. We show that in the presence of noise in the 3D points these solvers provide better estimates than the corresponding absolute pose solvers.
HRF-Net: Holistic Radiance Fields from Sparse Inputs
Aug 09, 2022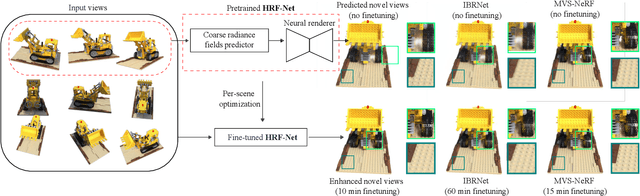
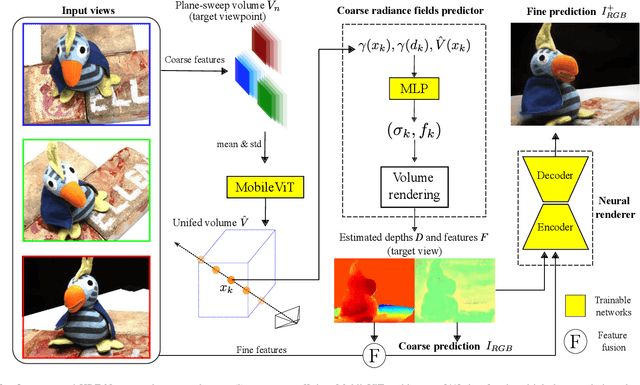
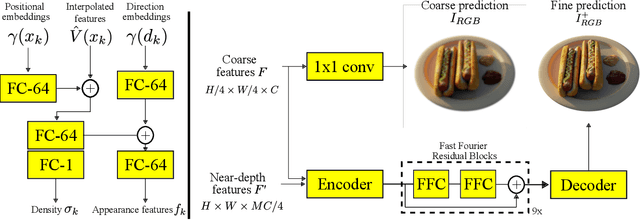
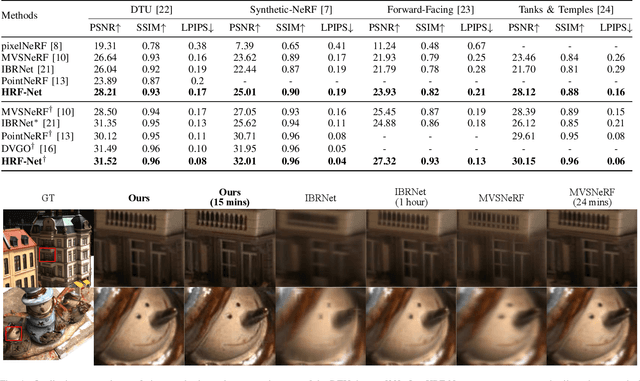
We present HRF-Net, a novel view synthesis method based on holistic radiance fields that renders novel views using a set of sparse inputs. Recent generalizing view synthesis methods also leverage the radiance fields but the rendering speed is not real-time. There are existing methods that can train and render novel views efficiently but they can not generalize to unseen scenes. Our approach addresses the problem of real-time rendering for generalizing view synthesis and consists of two main stages: a holistic radiance fields predictor and a convolutional-based neural renderer. This architecture infers not only consistent scene geometry based on the implicit neural fields but also renders new views efficiently using a single GPU. We first train HRF-Net on multiple 3D scenes of the DTU dataset and the network can produce plausible novel views on unseen real and synthetics data using only photometric losses. Moreover, our method can leverage a denser set of reference images of a single scene to produce accurate novel views without relying on additional explicit representations and still maintains the high-speed rendering of the pre-trained model. Experimental results show that HRF-Net outperforms state-of-the-art generalizable neural rendering methods on various synthetic and real datasets.
AxIoU: An Axiomatically Justified Measure for Video Moment Retrieval
Mar 30, 2022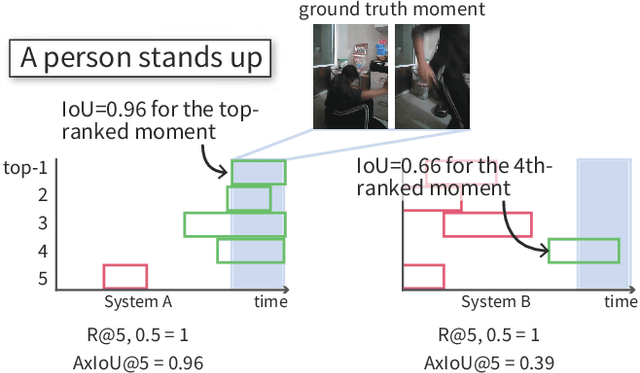
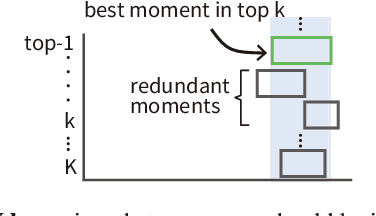
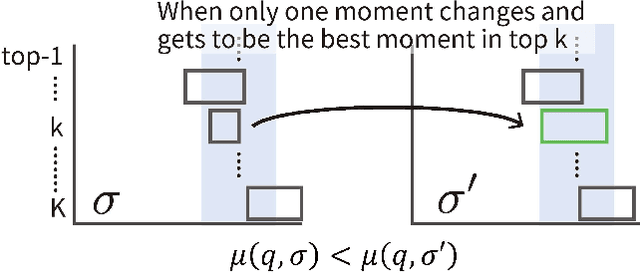
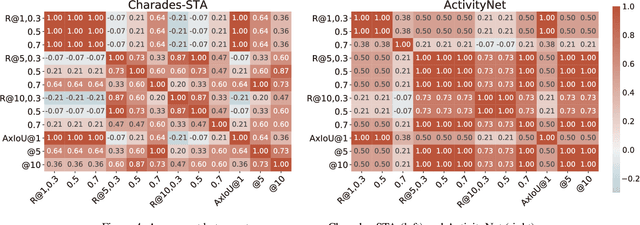
Evaluation measures have a crucial impact on the direction of research. Therefore, it is of utmost importance to develop appropriate and reliable evaluation measures for new applications where conventional measures are not well suited. Video Moment Retrieval (VMR) is one such application, and the current practice is to use R@$K,\theta$ for evaluating VMR systems. However, this measure has two disadvantages. First, it is rank-insensitive: It ignores the rank positions of successfully localised moments in the top-$K$ ranked list by treating the list as a set. Second, it binarizes the Intersection over Union (IoU) of each retrieved video moment using the threshold $\theta$ and thereby ignoring fine-grained localisation quality of ranked moments. We propose an alternative measure for evaluating VMR, called Average Max IoU (AxIoU), which is free from the above two problems. We show that AxIoU satisfies two important axioms for VMR evaluation, namely, \textbf{Invariance against Redundant Moments} and \textbf{Monotonicity with respect to the Best Moment}, and also that R@$K,\theta$ satisfies the first axiom only. We also empirically examine how AxIoU agrees with R@$K,\theta$, as well as its stability with respect to change in the test data and human-annotated temporal boundaries.
Fast Neural Architecture Search for Lightweight Dense Prediction Networks
Mar 09, 2022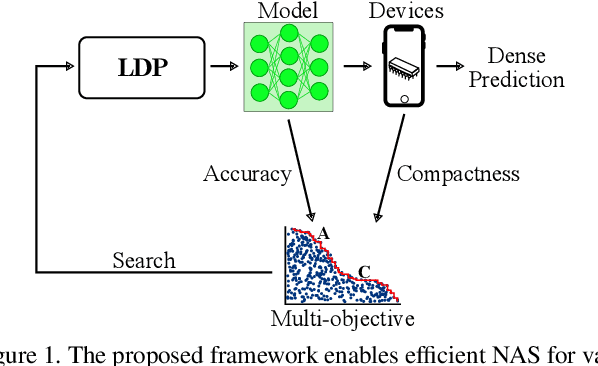
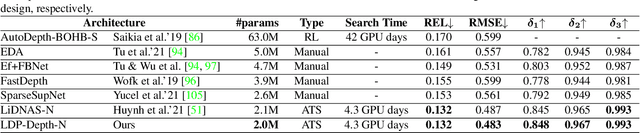
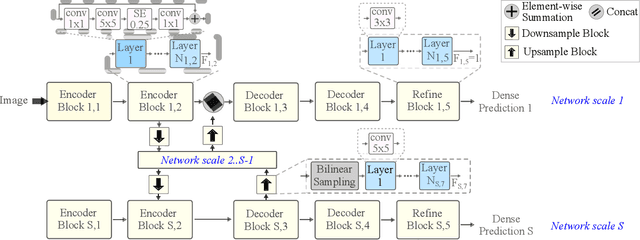
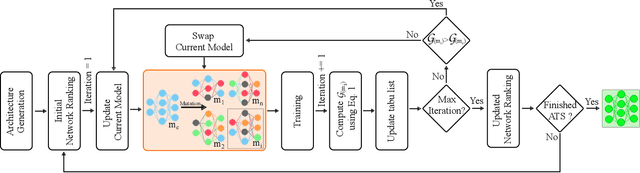
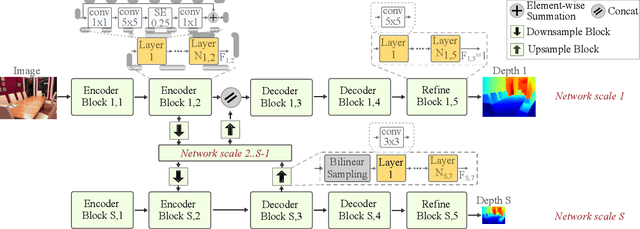
We present LDP, a lightweight dense prediction neural architecture search (NAS) framework. Starting from a pre-defined generic backbone, LDP applies the novel Assisted Tabu Search for efficient architecture exploration. LDP is fast and suitable for various dense estimation problems, unlike previous NAS methods that are either computational demanding or deployed only for a single subtask. The performance of LPD is evaluated on monocular depth estimation, semantic segmentation, and image super-resolution tasks on diverse datasets, including NYU-Depth-v2, KITTI, Cityscapes, COCO-stuff, DIV2K, Set5, Set14, BSD100, Urban100. Experiments show that the proposed framework yields consistent improvements on all tested dense prediction tasks, while being $5\%-315\%$ more compact in terms of the number of model parameters than prior arts.
Human View Synthesis using a Single Sparse RGB-D Input
Dec 30, 2021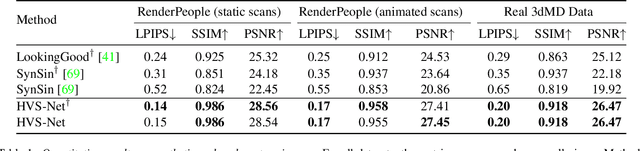

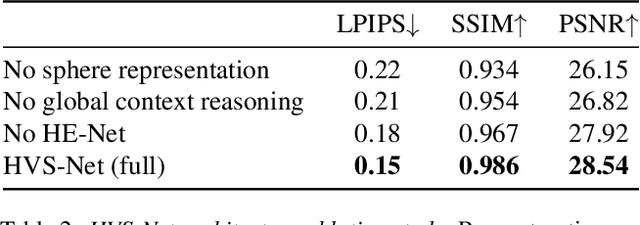
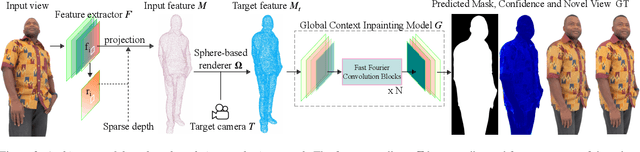
Novel view synthesis for humans in motion is a challenging computer vision problem that enables applications such as free-viewpoint video. Existing methods typically use complex setups with multiple input views, 3D supervision, or pre-trained models that do not generalize well to new identities. Aiming to address these limitations, we present a novel view synthesis framework to generate realistic renders from unseen views of any human captured from a single-view sensor with sparse RGB-D, similar to a low-cost depth camera, and without actor-specific models. We propose an architecture to learn dense features in novel views obtained by sphere-based neural rendering, and create complete renders using a global context inpainting model. Additionally, an enhancer network leverages the overall fidelity, even in occluded areas from the original view, producing crisp renders with fine details. We show our method generates high-quality novel views of synthetic and real human actors given a single sparse RGB-D input. It generalizes to unseen identities, new poses and faithfully reconstructs facial expressions. Our approach outperforms prior human view synthesis methods and is robust to different levels of input sparsity.
Lightweight Monocular Depth with a Novel Neural Architecture Search Method
Aug 25, 2021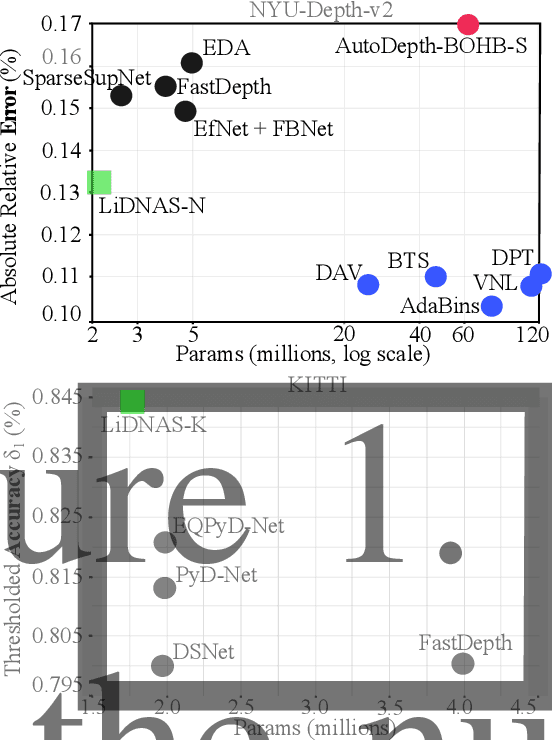

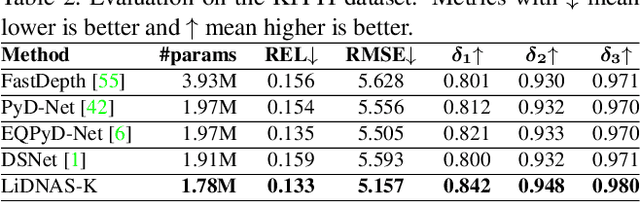
This paper presents a novel neural architecture search method, called LiDNAS, for generating lightweight monocular depth estimation models. Unlike previous neural architecture search (NAS) approaches, where finding optimized networks are computationally highly demanding, the introduced novel Assisted Tabu Search leads to efficient architecture exploration. Moreover, we construct the search space on a pre-defined backbone network to balance layer diversity and search space size. The LiDNAS method outperforms the state-of-the-art NAS approach, proposed for disparity and depth estimation, in terms of search efficiency and output model performance. The LiDNAS optimized models achieve results superior to compact depth estimation state-of-the-art on NYU-Depth-v2, KITTI, and ScanNet, while being 7%-500% more compact in size, i.e the number of model parameters.
Monocular Depth Estimation Primed by Salient Point Detection and Normalized Hessian Loss
Aug 25, 2021
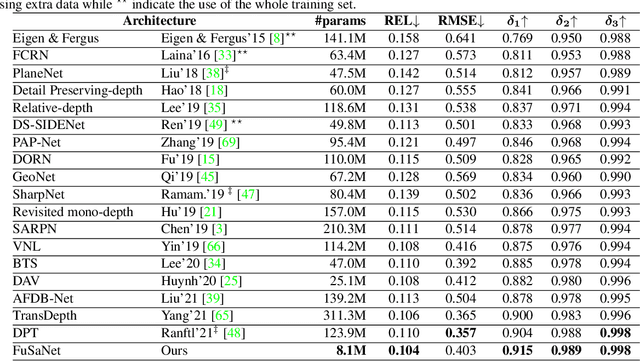
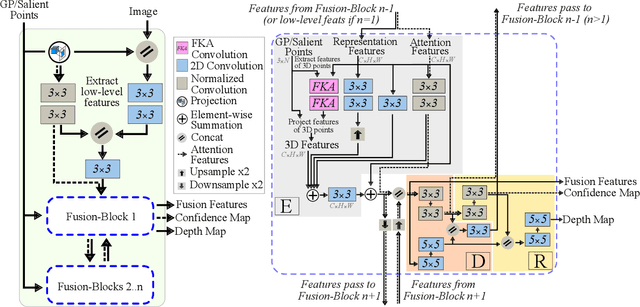
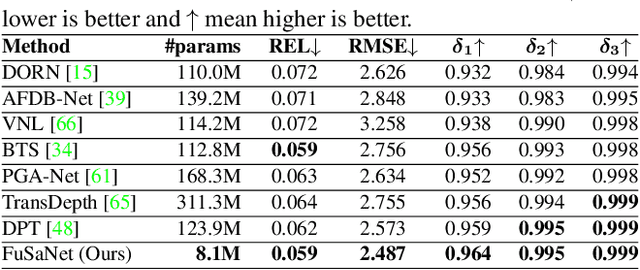
Deep neural networks have recently thrived on single image depth estimation. That being said, current developments on this topic highlight an apparent compromise between accuracy and network size. This work proposes an accurate and lightweight framework for monocular depth estimation based on a self-attention mechanism stemming from salient point detection. Specifically, we utilize a sparse set of keypoints to train a FuSaNet model that consists of two major components: Fusion-Net and Saliency-Net. In addition, we introduce a normalized Hessian loss term invariant to scaling and shear along the depth direction, which is shown to substantially improve the accuracy. The proposed method achieves state-of-the-art results on NYU-Depth-v2 and KITTI while using 3.1-38.4 times smaller model in terms of the number of parameters than baseline approaches. Experiments on the SUN-RGBD further demonstrate the generalizability of the proposed method.
Calibrated and Partially Calibrated Semi-Generalized Homographies
Mar 17, 2021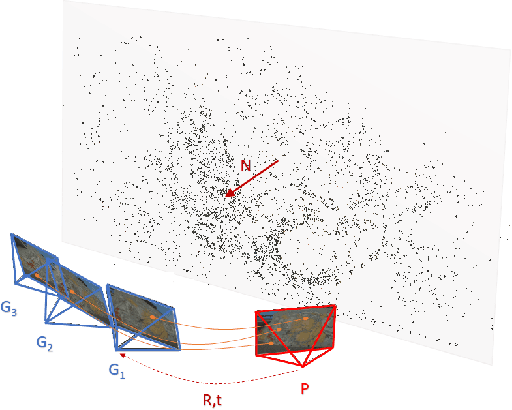
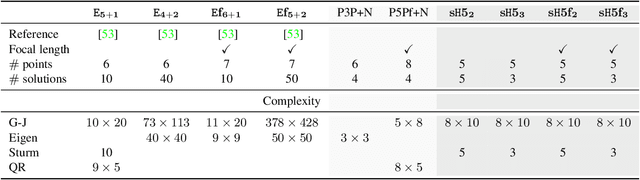
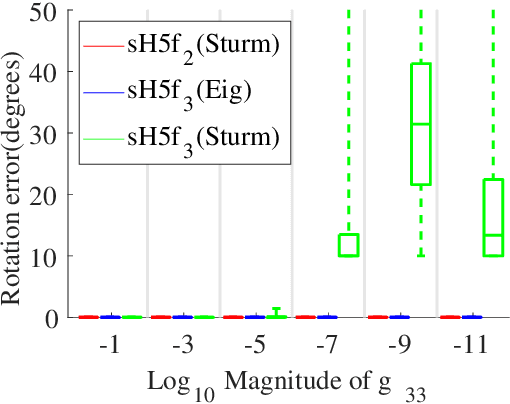
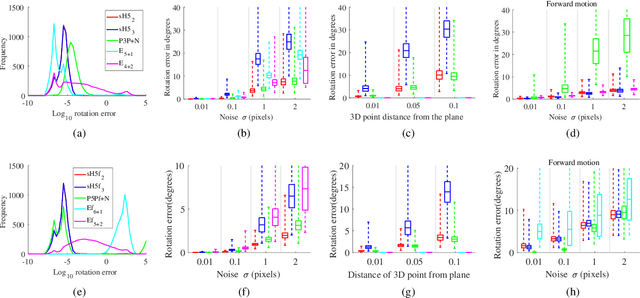
In this paper, we propose the first minimal solutions for estimating the semi-generalized homography given a perspective and a generalized camera. The proposed solvers use five 2D-2D image point correspondences induced by a scene plane. One of them assumes the perspective camera to be fully calibrated, while the other solver estimates the unknown focal length together with the absolute pose parameters. This setup is particularly important in structure-from-motion and image-based localization pipelines, where a new camera is localized in each step with respect to a set of known cameras and 2D-3D correspondences might not be available. As a consequence of a clever parametrization and the elimination ideal method, our approach only needs to solve a univariate polynomial of degree five or three. The proposed solvers are stable and efficient as demonstrated by a number of synthetic and real-world experiments.
Boosting Monocular Depth Estimation with Lightweight 3D Point Fusion
Dec 18, 2020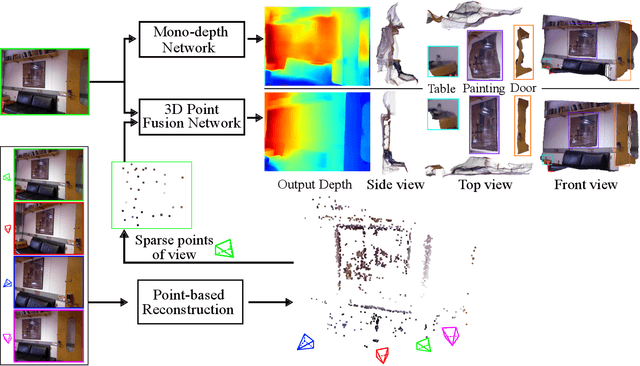
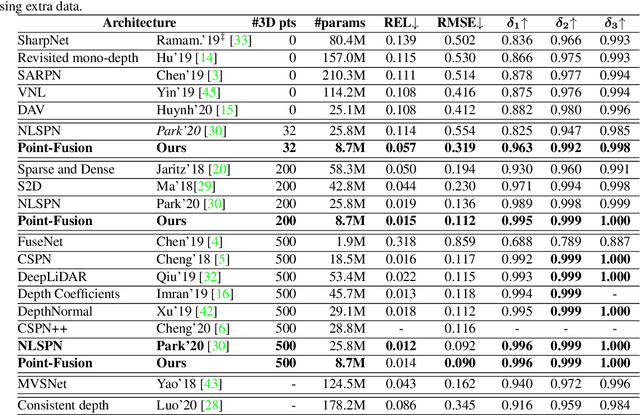
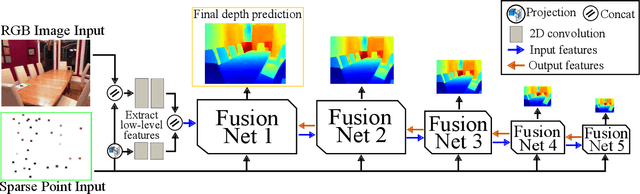
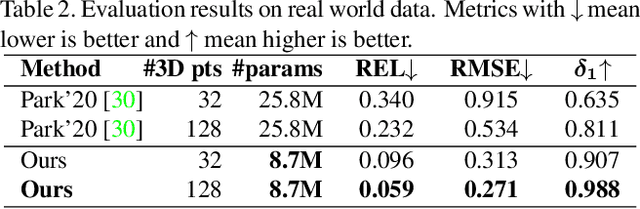
In this paper, we address the problem of fusing monocular depth estimation with a conventional multi-view stereo or SLAM to exploit the best of both worlds, that is, the accurate dense depth of the first one and lightweightness of the second one. More specifically, we use a conventional pipeline to produce a sparse 3D point cloud that is fed to a monocular depth estimation network to enhance its performance. In this way, we can achieve accuracy similar to multi-view stereo with a considerably smaller number of weights. We also show that even as few as 32 points is sufficient to outperform the best monocular depth estimation methods, and around 200 points to gain full advantage of the additional information. Moreover, we demonstrate the efficacy of our approach by integrating it with a SLAM system built-in on mobile devices.