 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Based Classification of Respiratory Diseases using Advanced Signal Processing and Machine Learning for Assistive Diagnosis Support
Sep 12, 2023



In global healthcare, respiratory diseases are a leading cause of mortality, underscoring the need for rapid and accurate diagnostics. To advance rapid screening techniques via auscultation, our research focuses on employing one of the largest publicly available medical database of respiratory sounds to train multiple machine learning models able to classify different health conditions. Our method combines Empirical Mode Decomposition (EMD) and spectral analysis to extract physiologically relevant biosignals from acoustic data, closely tied to cardiovascular and respiratory patterns, making our approach apart in its departure from conventional audio feature extraction practices. We use Power Spectral Density analysis and filtering techniques to select Intrinsic Mode Functions (IMFs) strongly correlated with underlying physiological phenomena. These biosignals undergo a comprehensive feature extraction process for predictive modeling. Initially, we deploy a binary classification model that demonstrates a balanced accuracy of 87% in distinguishing between healthy and diseased individuals. Subsequently, we employ a six-class classification model that achieves a balanced accuracy of 72% in diagnosing specific respiratory conditions like pneumonia and chronic obstructive pulmonary disease (COPD). For the first time, we also introduce regression models that estimate age and body mass index (BMI) based solely on acoustic data, as well as a model for gender classification. Our findings underscore the potential of this approach to significantly enhance assistive and remote diagnostic capabilities.
Blur Invariants for Image Recognition
Jan 18, 2023Blur is an image degradation that is difficult to remove. Invariants with respect to blur offer an alternative way of a~description and recognition of blurred images without any deblurring. In this paper, we present an original unified theory of blur invariants. Unlike all previous attempts, the new theory does not require any prior knowledge of the blur type. The invariants are constructed in the Fourier domain by means of orthogonal projection operators and moment expansion is used for efficient and stable computation. It is shown that all blur invariants published earlier are just particular cases of this approach. Experimental comparison to concurrent approaches shows the advantages of the proposed theory.
Monocular Depth Estimation Primed by Salient Point Detection and Normalized Hessian Loss
Aug 25, 2021
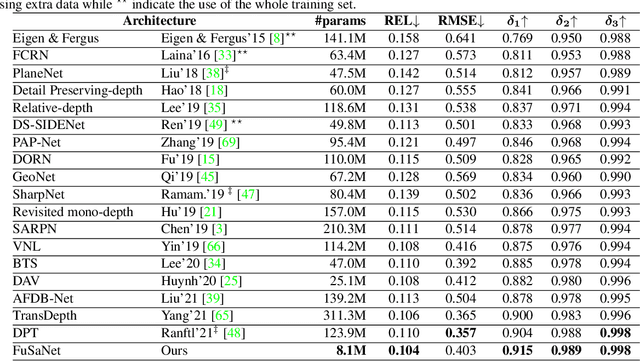
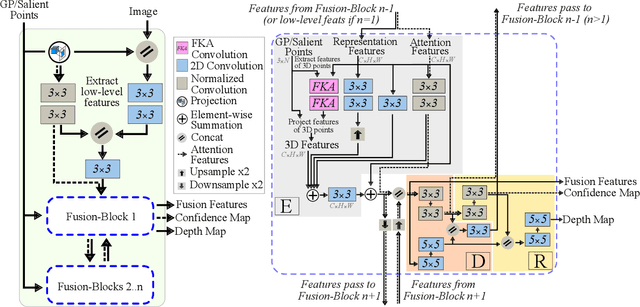
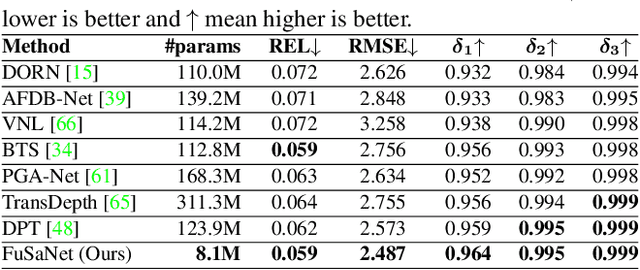
Deep neural networks have recently thrived on single image depth estimation. That being said, current developments on this topic highlight an apparent compromise between accuracy and network size. This work proposes an accurate and lightweight framework for monocular depth estimation based on a self-attention mechanism stemming from salient point detection. Specifically, we utilize a sparse set of keypoints to train a FuSaNet model that consists of two major components: Fusion-Net and Saliency-Net. In addition, we introduce a normalized Hessian loss term invariant to scaling and shear along the depth direction, which is shown to substantially improve the accuracy. The proposed method achieves state-of-the-art results on NYU-Depth-v2 and KITTI while using 3.1-38.4 times smaller model in terms of the number of parameters than baseline approaches. Experiments on the SUN-RGBD further demonstrate the generalizability of the proposed method.
Learning non-rigid surface reconstruction from spatio-temporal image patches
Jun 18, 2020

We present a method to reconstruct a dense spatio-temporal depth map of a non-rigidly deformable object directly from a video sequence. The estimation of depth is performed locally on spatio-temporal patches of the video, and then the full depth video of the entire shape is recovered by combining them together. Since the geometric complexity of a local spatio-temporal patch of a deforming non-rigid object is often simple enough to be faithfully represented with a parametric model, we artificially generate a database of small deforming rectangular meshes rendered with different material properties and light conditions, along with their corresponding depth videos, and use such data to train a convolutional neural network. We tested our method on both synthetic and Kinect data and experimentally observed that the reconstruction error is significantly lower than the one obtained using other approaches like conventional non-rigid structure from motion.