 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning non-rigid surface reconstruction from spatio-temporal image patches
Paper and Code
Jun 18, 2020

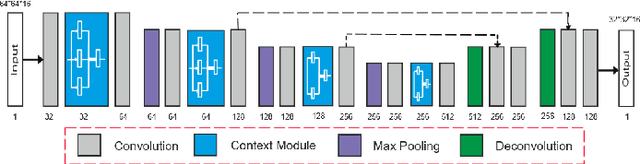
We present a method to reconstruct a dense spatio-temporal depth map of a non-rigidly deformable object directly from a video sequence. The estimation of depth is performed locally on spatio-temporal patches of the video, and then the full depth video of the entire shape is recovered by combining them together. Since the geometric complexity of a local spatio-temporal patch of a deforming non-rigid object is often simple enough to be faithfully represented with a parametric model, we artificially generate a database of small deforming rectangular meshes rendered with different material properties and light conditions, along with their corresponding depth videos, and use such data to train a convolutional neural network. We tested our method on both synthetic and Kinect data and experimentally observed that the reconstruction error is significantly lower than the one obtained using other approaches like conventional non-rigid structure from motion.