 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePalette of Language Models: A Solver for Controlled Text Generation
Mar 14, 2025



Recent advancements in large language models have revolutionized text generation with their remarkable capabilities. These models can produce controlled texts that closely adhere to specific requirements when prompted appropriately. However, designing an optimal prompt to control multiple attributes simultaneously can be challenging. A common approach is to linearly combine single-attribute models, but this strategy often overlooks attribute overlaps and can lead to conflicts. Therefore, we propose a novel combination strategy inspired by the Law of Total Probability and Conditional Mutual Information Minimization on generative language models. This method has been adapted for single-attribute control scenario and is termed the Palette of Language Models due to its theoretical linkage between attribute strength and generation style, akin to blending colors on an artist's palette. Moreover, positive correlation and attribute enhancement are advanced as theoretical properties to guide a rational combination strategy design. We conduct experiments on both single control and multiple control settings, and achieve surpassing results.
Non-contact Multimodal Indoor Human Monitoring Systems: A Survey
Dec 11, 2023



Indoor human monitoring systems leverage a wide range of sensors, including cameras, radio devices, and inertial measurement units, to collect extensive data from users and the environment. These sensors contribute diverse data modalities, such as video feeds from cameras, received signal strength indicators and channel state information from WiFi devices, and three-axis acceleration data from inertial measurement units. In this context, we present a comprehensive survey of multimodal approaches for indoor human monitoring systems, with a specific focus on their relevance in elderly care. Our survey primarily highlights non-contact technologies, particularly cameras and radio devices, as key components in the development of indoor human monitoring systems. Throughout this article, we explore well-established techniques for extracting features from multimodal data sources. Our exploration extends to methodologies for fusing these features and harnessing multiple modalities to improve the accuracy and robustness of machine learning models. Furthermore, we conduct comparative analysis across different data modalities in diverse human monitoring tasks and undertake a comprehensive examination of existing multimodal datasets. This extensive survey not only highlights the significance of indoor human monitoring systems but also affirms their versatile applications. In particular, we emphasize their critical role in enhancing the quality of elderly care, offering valuable insights into the development of non-contact monitoring solutions applicable to the needs of aging populations.
Kinship Verification from rPPG using 1DCNN Attention networks
Sep 14, 2023



Facial kinship verification aims at automatically determining whether two subjects have a kinship relation. It has been widely studied from different modalities, such as faces, voices, gait, and smiling expressions. However, the potential of bio-signals, such as remote Photoplethysmography (rPPG) extracted from facial videos, remains largely unexplored in the kinship verification problem. In this paper, we investigate for the first time the usage of the rPPG signal for kinship verification. Specifically, we proposed a one-dimensional Convolutional Neural Network (1DCNN) with a 1DCNN-Attention module and contrastive loss to learn the kinship similarity from rPPGs. The network takes multiple rPPG signals extracted from various facial Regions of Interest (ROIs) as inputs. Additionally, the 1DCNN attention module is designed to learn and capture the discriminative kin features from feature embeddings. Finally, the proposed method is evaluated on the UvANEMO Smile Database from different kin relations, showing the usefulness of rPPG signals in verifying kinship.
Audio-Based Classification of Respiratory Diseases using Advanced Signal Processing and Machine Learning for Assistive Diagnosis Support
Sep 12, 2023



In global healthcare, respiratory diseases are a leading cause of mortality, underscoring the need for rapid and accurate diagnostics. To advance rapid screening techniques via auscultation, our research focuses on employing one of the largest publicly available medical database of respiratory sounds to train multiple machine learning models able to classify different health conditions. Our method combines Empirical Mode Decomposition (EMD) and spectral analysis to extract physiologically relevant biosignals from acoustic data, closely tied to cardiovascular and respiratory patterns, making our approach apart in its departure from conventional audio feature extraction practices. We use Power Spectral Density analysis and filtering techniques to select Intrinsic Mode Functions (IMFs) strongly correlated with underlying physiological phenomena. These biosignals undergo a comprehensive feature extraction process for predictive modeling. Initially, we deploy a binary classification model that demonstrates a balanced accuracy of 87% in distinguishing between healthy and diseased individuals. Subsequently, we employ a six-class classification model that achieves a balanced accuracy of 72% in diagnosing specific respiratory conditions like pneumonia and chronic obstructive pulmonary disease (COPD). For the first time, we also introduce regression models that estimate age and body mass index (BMI) based solely on acoustic data, as well as a model for gender classification. Our findings underscore the potential of this approach to significantly enhance assistive and remote diagnostic capabilities.
Audio-Visual Kinship Verification
Jun 24, 2019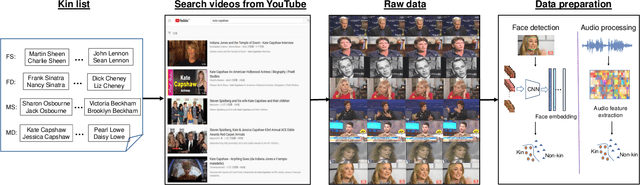
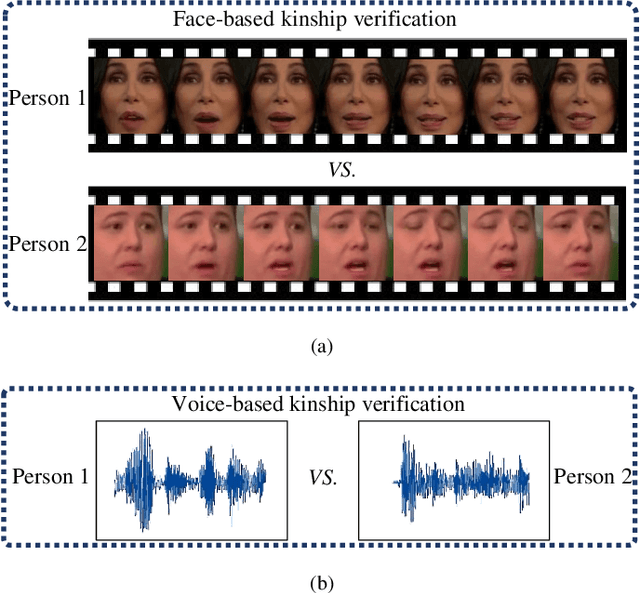
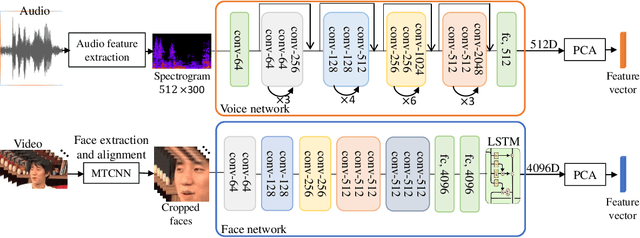

Visual kinship verification entails confirming whether or not two individuals in a given pair of images or videos share a hypothesized kin relation. As a generalized face verification task, visual kinship verification is particularly difficult with low-quality found Internet data. Due to uncontrolled variations in background, pose, facial expression, blur, illumination and occlusion, state-of-the-art methods fail to provide high level of recognition accuracy. As with many other visual recognition tasks, kinship verification may benefit from combining visual and audio signals. However, voice-based kinship verification has received very little prior attention. We hypothesize that the human voice contains kin-related cues that are complementary to visual cues. In this paper, we address, for the first time, the use of audio-visual information from face and voice modalities to perform kinship verification. We first propose a new multi-modal kinship dataset, called TALking KINship (TALKIN), that contains several pairs of Internet-quality video sequences. Using TALKIN, we then study the utility of various kinship verification methods including traditional local feature based methods, statistical methods and more recent deep learning approaches. Then, early and late fusion methods are evaluated on the TALKIN dataset for the study of kinship verification with both face and voice modalities. Finally, we propose a deep Siamese fusion network with contrastive loss for multi-modal fusion of kinship relations. Extensive experiments on the TALKIN dataset indicate that by combining face and voice modalities, the proposed Siamese network can provide a significantly higher level of accuracy compared to baseline uni-modal and multi-modal fusion techniques. Experimental results also indicate that audio (vocal) information is complementary (to facial information) and useful for kinship verification.