 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Kinship Verification
Paper and Code
Jun 24, 2019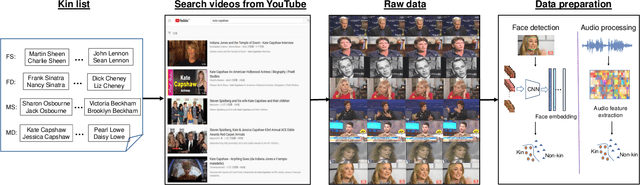
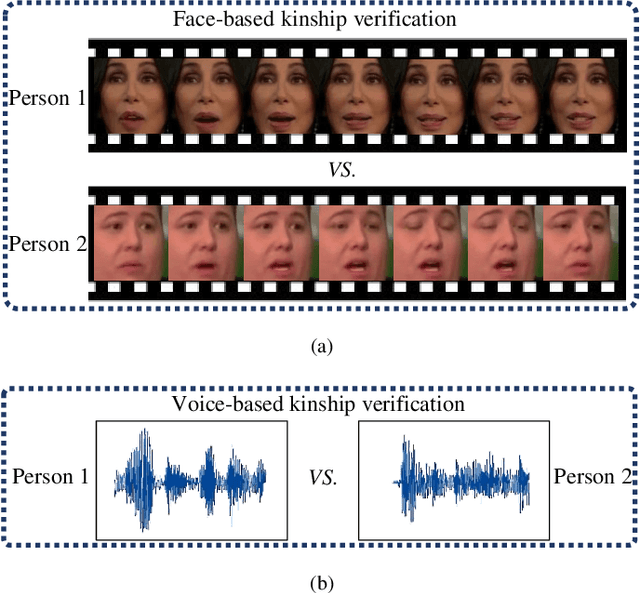
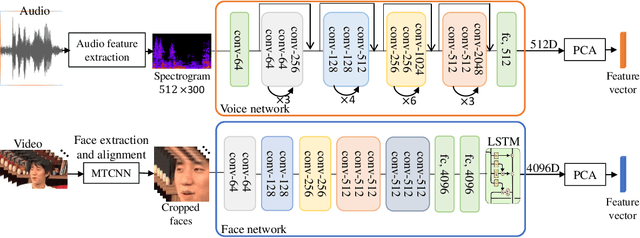

Visual kinship verification entails confirming whether or not two individuals in a given pair of images or videos share a hypothesized kin relation. As a generalized face verification task, visual kinship verification is particularly difficult with low-quality found Internet data. Due to uncontrolled variations in background, pose, facial expression, blur, illumination and occlusion, state-of-the-art methods fail to provide high level of recognition accuracy. As with many other visual recognition tasks, kinship verification may benefit from combining visual and audio signals. However, voice-based kinship verification has received very little prior attention. We hypothesize that the human voice contains kin-related cues that are complementary to visual cues. In this paper, we address, for the first time, the use of audio-visual information from face and voice modalities to perform kinship verification. We first propose a new multi-modal kinship dataset, called TALking KINship (TALKIN), that contains several pairs of Internet-quality video sequences. Using TALKIN, we then study the utility of various kinship verification methods including traditional local feature based methods, statistical methods and more recent deep learning approaches. Then, early and late fusion methods are evaluated on the TALKIN dataset for the study of kinship verification with both face and voice modalities. Finally, we propose a deep Siamese fusion network with contrastive loss for multi-modal fusion of kinship relations. Extensive experiments on the TALKIN dataset indicate that by combining face and voice modalities, the proposed Siamese network can provide a significantly higher level of accuracy compared to baseline uni-modal and multi-modal fusion techniques. Experimental results also indicate that audio (vocal) information is complementary (to facial information) and useful for kinship verification.