 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPerception: Advancing R1-like Cognitive Visual Perception in MLLMs for Knowledge-Intensive Visual Grounding
Mar 17, 2025Human experts excel at fine-grained visual discrimination by leveraging domain knowledge to refine perceptual features, a capability that remains underdeveloped in current Multimodal Large Language Models (MLLMs). Despite possessing vast expert-level knowledge, MLLMs struggle to integrate reasoning into visual perception, often generating direct responses without deeper analysis. To bridge this gap, we introduce knowledge-intensive visual grounding (KVG), a novel visual grounding task that requires both fine-grained perception and domain-specific knowledge integration. To address the challenges of KVG, we propose DeepPerception, an MLLM enhanced with cognitive visual perception capabilities. Our approach consists of (1) an automated data synthesis pipeline that generates high-quality, knowledge-aligned training samples, and (2) a two-stage training framework combining supervised fine-tuning for cognitive reasoning scaffolding and reinforcement learning to optimize perception-cognition synergy. To benchmark performance, we introduce KVG-Bench a comprehensive dataset spanning 10 domains with 1.3K manually curated test cases. Experimental results demonstrate that DeepPerception significantly outperforms direct fine-tuning, achieving +8.08\% accuracy improvements on KVG-Bench and exhibiting +4.60\% superior cross-domain generalization over baseline approaches. Our findings highlight the importance of integrating cognitive processes into MLLMs for human-like visual perception and open new directions for multimodal reasoning research. The data, codes, and models are released at https://github.com/thunlp/DeepPerception.
Over-parameterization and Adversarial Robustness in Neural Networks: An Overview and Empirical Analysis
Jun 14, 2024



Thanks to their extensive capacity, over-parameterized neural networks exhibit superior predictive capabilities and generalization. However, having a large parameter space is considered one of the main suspects of the neural networks' vulnerability to adversarial example -- input samples crafted ad-hoc to induce a desired misclassification. Relevant literature has claimed contradictory remarks in support of and against the robustness of over-parameterized networks. These contradictory findings might be due to the failure of the attack employed to evaluate the networks' robustness. Previous research has demonstrated that depending on the considered model, the algorithm employed to generate adversarial examples may not function properly, leading to overestimating the model's robustness. In this work, we empirically study the robustness of over-parameterized networks against adversarial examples. However, unlike the previous works, we also evaluate the considered attack's reliability to support the results' veracity. Our results show that over-parameterized networks are robust against adversarial attacks as opposed to their under-parameterized counterparts.
Kinship Verification from rPPG using 1DCNN Attention networks
Sep 14, 2023



Facial kinship verification aims at automatically determining whether two subjects have a kinship relation. It has been widely studied from different modalities, such as faces, voices, gait, and smiling expressions. However, the potential of bio-signals, such as remote Photoplethysmography (rPPG) extracted from facial videos, remains largely unexplored in the kinship verification problem. In this paper, we investigate for the first time the usage of the rPPG signal for kinship verification. Specifically, we proposed a one-dimensional Convolutional Neural Network (1DCNN) with a 1DCNN-Attention module and contrastive loss to learn the kinship similarity from rPPGs. The network takes multiple rPPG signals extracted from various facial Regions of Interest (ROIs) as inputs. Additionally, the 1DCNN attention module is designed to learn and capture the discriminative kin features from feature embeddings. Finally, the proposed method is evaluated on the UvANEMO Smile Database from different kin relations, showing the usefulness of rPPG signals in verifying kinship.
Hardening RGB-D Object Recognition Systems against Adversarial Patch Attacks
Sep 13, 2023



RGB-D object recognition systems improve their predictive performances by fusing color and depth information, outperforming neural network architectures that rely solely on colors. While RGB-D systems are expected to be more robust to adversarial examples than RGB-only systems, they have also been proven to be highly vulnerable. Their robustness is similar even when the adversarial examples are generated by altering only the original images' colors. Different works highlighted the vulnerability of RGB-D systems; however, there is a lacking of technical explanations for this weakness. Hence, in our work, we bridge this gap by investigating the learned deep representation of RGB-D systems, discovering that color features make the function learned by the network more complex and, thus, more sensitive to small perturbations. To mitigate this problem, we propose a defense based on a detection mechanism that makes RGB-D systems more robust against adversarial examples. We empirically show that this defense improves the performances of RGB-D systems against adversarial examples even when they are computed ad-hoc to circumvent this detection mechanism, and that is also more effective than adversarial training.
Why Adversarial Reprogramming Works, When It Fails, and How to Tell the Difference
Aug 31, 2021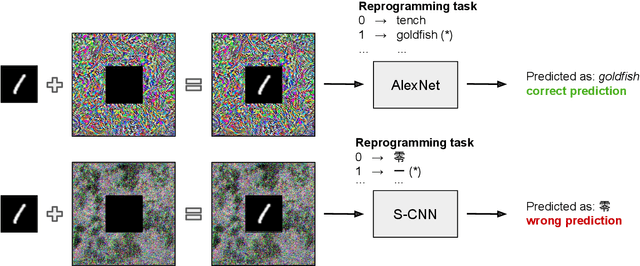
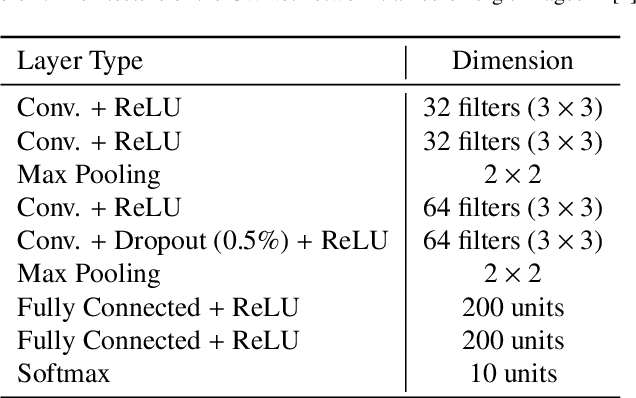
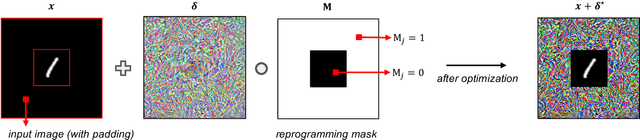
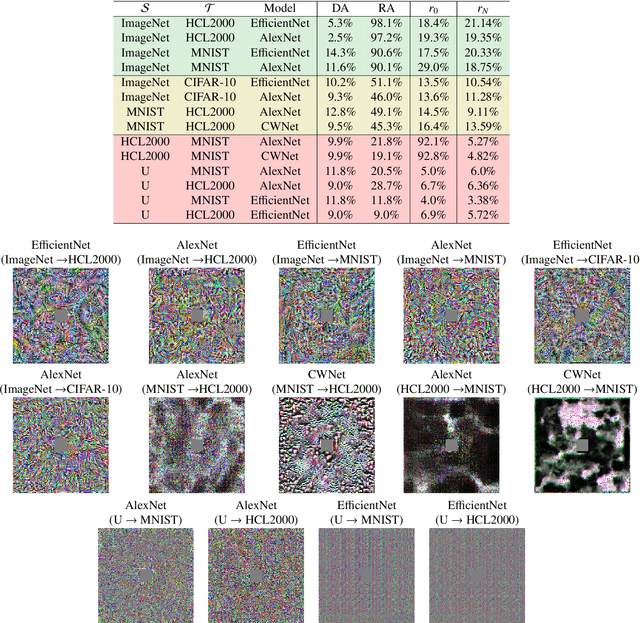
Adversarial reprogramming allows repurposing a machine-learning model to perform a different task. For example, a model trained to recognize animals can be reprogrammed to recognize digits by embedding an adversarial program in the digit images provided as input. Recent work has shown that adversarial reprogramming may not only be used to abuse machine-learning models provided as a service, but also beneficially, to improve transfer learning when training data is scarce. However, the factors affecting its success are still largely unexplained. In this work, we develop a first-order linear model of adversarial reprogramming to show that its success inherently depends on the size of the average input gradient, which grows when input gradients are more aligned, and when inputs have higher dimensionality. The results of our experimental analysis, involving fourteen distinct reprogramming tasks, show that the above factors are correlated with the success and the failure of adversarial reprogramming.
Non-contact Pain Recognition from Video Sequences with Remote Physiological Measurements Prediction
May 18, 2021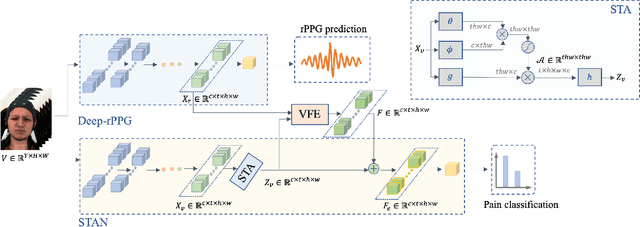
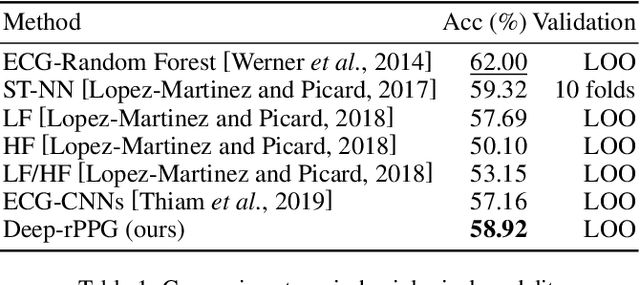


Automatic pain recognition is paramount for medical diagnosis and treatment. The existing works fall into three categories: assessing facial appearance changes, exploiting physiological cues, or fusing them in a multi-modal manner. However, (1) appearance changes are easily affected by subjective factors which impedes objective pain recognition. Besides, the appearance-based approaches ignore long-range spatial-temporal dependencies that are important for modeling expressions over time; (2) the physiological cues are obtained by attaching sensors on human body, which is inconvenient and uncomfortable. In this paper, we present a novel multi-task learning framework which encodes both appearance changes and physiological cues in a non-contact manner for pain recognition. The framework is able to capture both local and long-range dependencies via the proposed attention mechanism for the learned appearance representations, which are further enriched by temporally attended physiological cues (remote photoplethysmography, rPPG) that are recovered from videos in the auxiliary task. This framework is dubbed rPPG-enriched Spatio-Temporal Attention Network (rSTAN) and allows us to establish the state-of-the-art performance of non-contact pain recognition on publicly available pain databases. It demonstrates that rPPG predictions can be used as an auxiliary task to facilitate non-contact automatic pain recognition.
Are spoofs from latent fingerprints a real threat for the best state-of-art liveness detectors?
Jul 07, 2020
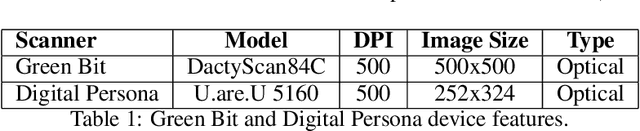


We investigated the threat level of realistic attacks using latent fingerprints against sensors equipped with state-of-art liveness detectors and fingerprint verification systems which integrate such liveness algorithms. To the best of our knowledge, only a previous investigation was done with spoofs from latent prints. In this paper, we focus on using snapshot pictures of latent fingerprints. These pictures provide molds, that allows, after some digital processing, to fabricate high-quality spoofs. Taking a snapshot picture is much simpler than developing fingerprints left on a surface by magnetic powders and lifting the trace by a tape. What we are interested here is to evaluate preliminary at which extent attacks of the kind can be considered a real threat for state-of-art fingerprint liveness detectors and verification systems. To this aim, we collected a novel data set of live and spoof images fabricated with snapshot pictures of latent fingerprints. This data set provide a set of attacks at the most favourable conditions. We refer to this method and the related data set as "ScreenSpoof". Then, we tested with it the performances of the best liveness detection algorithms, namely, the three winners of the LivDet competition. Reported results point out that the ScreenSpoof method is a threat of the same level, in terms of detection and verification errors, than that of attacks using spoofs fabricated with the full consensus of the victim. We think that this is a notable result, never reported in previous work.
Revealing the Invisible with Model and Data Shrinking for Composite-database Micro-expression Recognition
Jun 17, 2020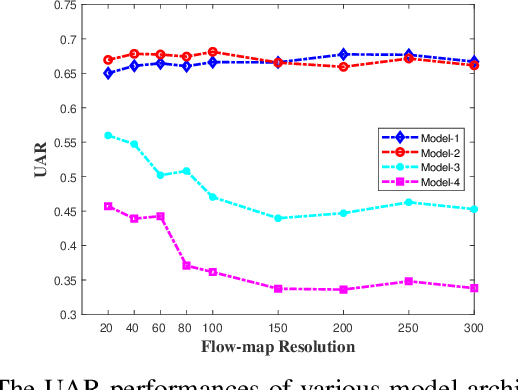
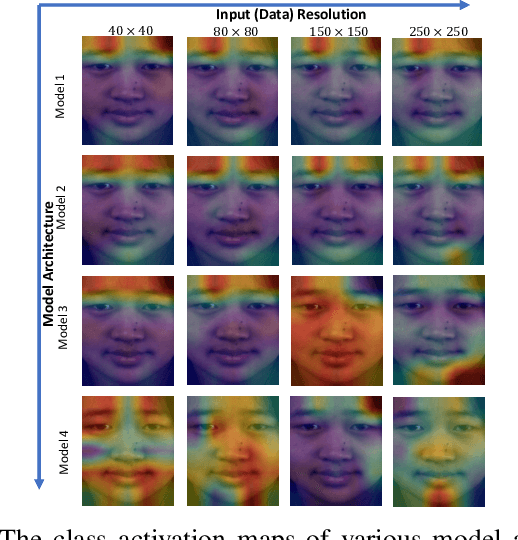

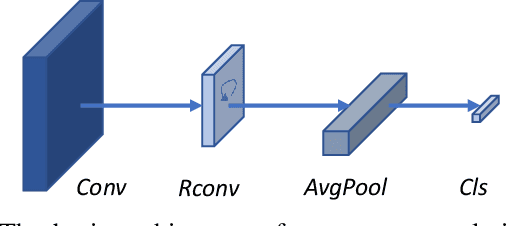
Composite-database micro-expression recognition is attracting increasing attention as it is more practical to real-world applications. Though the composite database provides more sample diversity for learning good representation models, the important subtle dynamics are prone to disappearing in the domain shift such that the models greatly degrade their performance, especially for deep models. In this paper, we analyze the influence of learning complexity, including the input complexity and model complexity, and discover that the lower-resolution input data and shallower-architecture model are helpful to ease the degradation of deep models in composite-database task. Based on this, we propose a recurrent convolutional network (RCN) to explore the shallower-architecture and lower-resolution input data, shrinking model and input complexities simultaneously. Furthermore, we develop three parameter-free modules (i.e., wide expansion, shortcut connection and attention unit) to integrate with RCN without increasing any learnable parameters. These three modules can enhance the representation ability in various perspectives while preserving not-very-deep architecture for lower-resolution data. Besides, three modules can further be combined by an automatic strategy (a neural architecture search strategy) and the searched architecture becomes more robust. Extensive experiments on MEGC2019 dataset (composited of existing SMIC, CASME II and SAMM datasets) have verified the influence of learning complexity and shown that RCNs with three modules and the searched combination outperform the state-of-the-art approaches.
Deep Neural Rejection against Adversarial Examples
Oct 01, 2019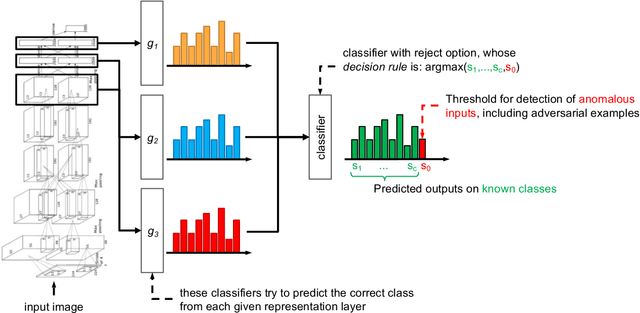
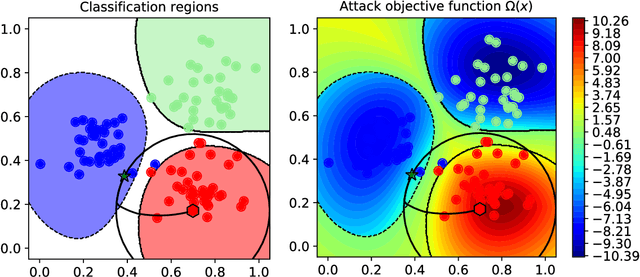
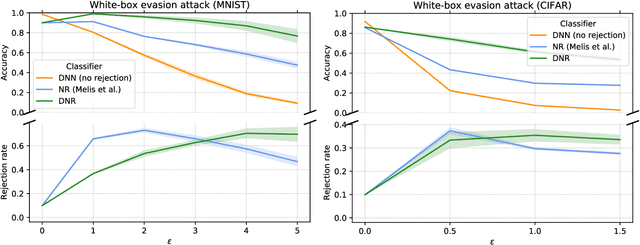
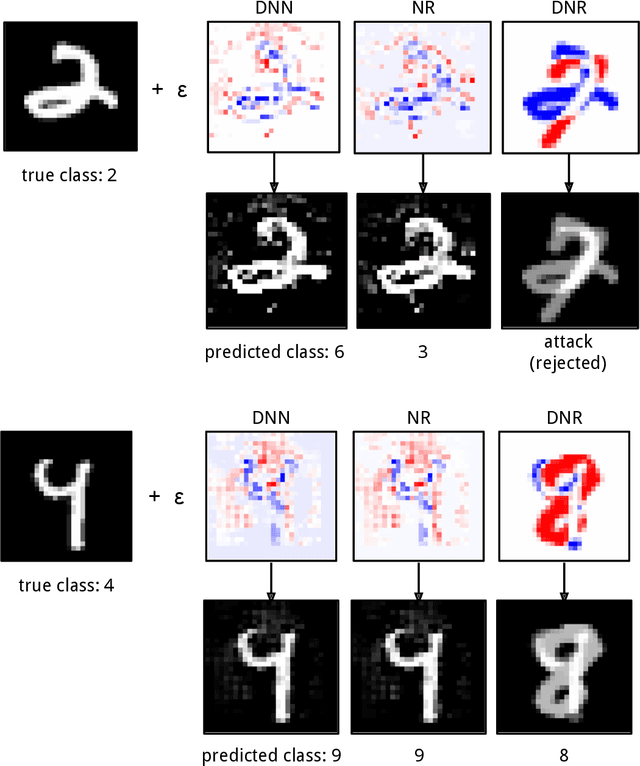
Despite the impressive performances reported by deep neural networks in different application domains, they remain largely vulnerable to adversarial examples, i.e., input samples that are carefully perturbed to cause misclassification at test time. In this work, we propose a deep neural rejection mechanism to detect adversarial examples, based on the idea of rejecting samples that exhibit anomalous feature representations at different network layers. With respect to competing approaches, our method does not require generating adversarial examples at training time, and it is less computationally demanding. To properly evaluate our method, we define an adaptive white-box attack that is aware of the defense mechanism and aims to bypass it. Under this worst-case setting, we empirically show that our approach outperforms previously-proposed methods that detect adversarial examples by only analyzing the feature representation provided by the output network layer.
Audio-Visual Kinship Verification
Jun 24, 2019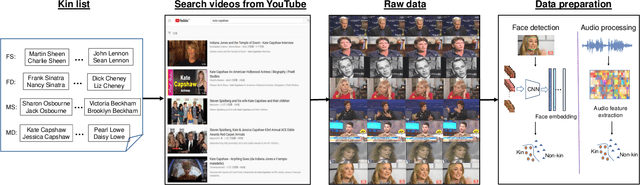
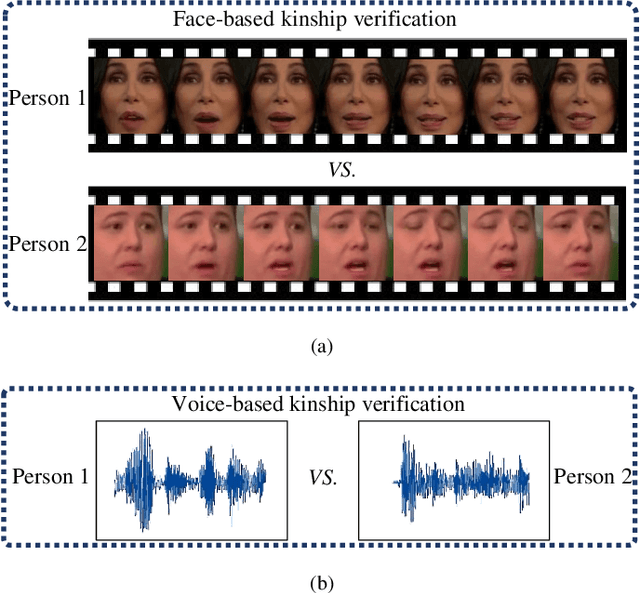
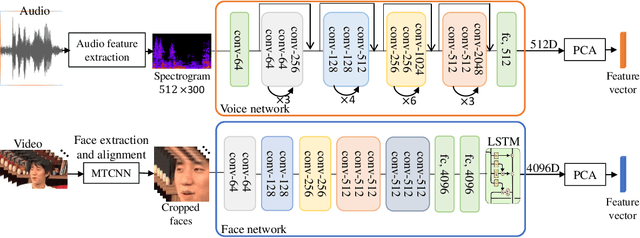

Visual kinship verification entails confirming whether or not two individuals in a given pair of images or videos share a hypothesized kin relation. As a generalized face verification task, visual kinship verification is particularly difficult with low-quality found Internet data. Due to uncontrolled variations in background, pose, facial expression, blur, illumination and occlusion, state-of-the-art methods fail to provide high level of recognition accuracy. As with many other visual recognition tasks, kinship verification may benefit from combining visual and audio signals. However, voice-based kinship verification has received very little prior attention. We hypothesize that the human voice contains kin-related cues that are complementary to visual cues. In this paper, we address, for the first time, the use of audio-visual information from face and voice modalities to perform kinship verification. We first propose a new multi-modal kinship dataset, called TALking KINship (TALKIN), that contains several pairs of Internet-quality video sequences. Using TALKIN, we then study the utility of various kinship verification methods including traditional local feature based methods, statistical methods and more recent deep learning approaches. Then, early and late fusion methods are evaluated on the TALKIN dataset for the study of kinship verification with both face and voice modalities. Finally, we propose a deep Siamese fusion network with contrastive loss for multi-modal fusion of kinship relations. Extensive experiments on the TALKIN dataset indicate that by combining face and voice modalities, the proposed Siamese network can provide a significantly higher level of accuracy compared to baseline uni-modal and multi-modal fusion techniques. Experimental results also indicate that audio (vocal) information is complementary (to facial information) and useful for kinship verification.