 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-efficient Training Updates for Malware Detection over Time
Mar 30, 2026Machine Learning (ML)-based detectors are becoming essential to counter the proliferation of malware. However, common ML algorithms are not designed to cope with the dynamic nature of real-world settings, where both legitimate and malicious software evolve. This distribution drift causes models trained under static assumptions to degrade over time unless they are continuously updated. Regularly retraining these models, however, is expensive, since labeling new acquired data requires costly manual analysis by security experts. To reduce labeling costs and address distribution drift in malware detection, prior work explored active learning (AL) and semi-supervised learning (SSL) techniques. Yet, existing studies (i) are tightly coupled to specific detector architectures and restricted to a specific malware domain, resulting in non-uniform comparisons; and (ii) lack a consistent methodology for analyzing the distribution drift, despite the critical sensitivity of the malware domain to temporal changes. In this work, we bridge this gap by proposing a model-agnostic framework that evaluates an extensive set of AL and SSL techniques, isolated and combined, for Android and Windows malware detection. We show that these techniques, when combined, can reduce manual annotation costs by up to 90% across both domains while achieving comparable detection performance to full-labeling retraining. We also introduce a methodology for feature-level drift analysis that measures feature stability over time, showing its correlation with the detector performance. Overall, our study provides a detailed understanding of how AL and SSL behave under distribution drift and how they can be successfully combined, offering practical insights for the design of effective detectors over time.
RAID: A Dataset for Testing the Adversarial Robustness of AI-Generated Image Detectors
Jun 09, 2025AI-generated images have reached a quality level at which humans are incapable of reliably distinguishing them from real images. To counteract the inherent risk of fraud and disinformation, the detection of AI-generated images is a pressing challenge and an active research topic. While many of the presented methods claim to achieve high detection accuracy, they are usually evaluated under idealized conditions. In particular, the adversarial robustness is often neglected, potentially due to a lack of awareness or the substantial effort required to conduct a comprehensive robustness analysis. In this work, we tackle this problem by providing a simpler means to assess the robustness of AI-generated image detectors. We present RAID (Robust evaluation of AI-generated image Detectors), a dataset of 72k diverse and highly transferable adversarial examples. The dataset is created by running attacks against an ensemble of seven state-of-the-art detectors and images generated by four different text-to-image models. Extensive experiments show that our methodology generates adversarial images that transfer with a high success rate to unseen detectors, which can be used to quickly provide an approximate yet still reliable estimate of a detector's adversarial robustness. Our findings indicate that current state-of-the-art AI-generated image detectors can be easily deceived by adversarial examples, highlighting the critical need for the development of more robust methods. We release our dataset at https://huggingface.co/datasets/aimagelab/RAID and evaluation code at https://github.com/pralab/RAID.
Robust image classification with multi-modal large language models
Dec 13, 2024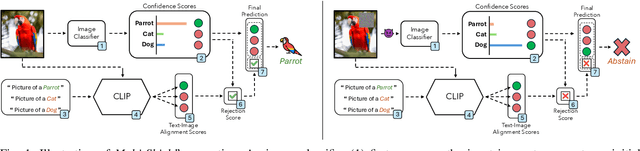
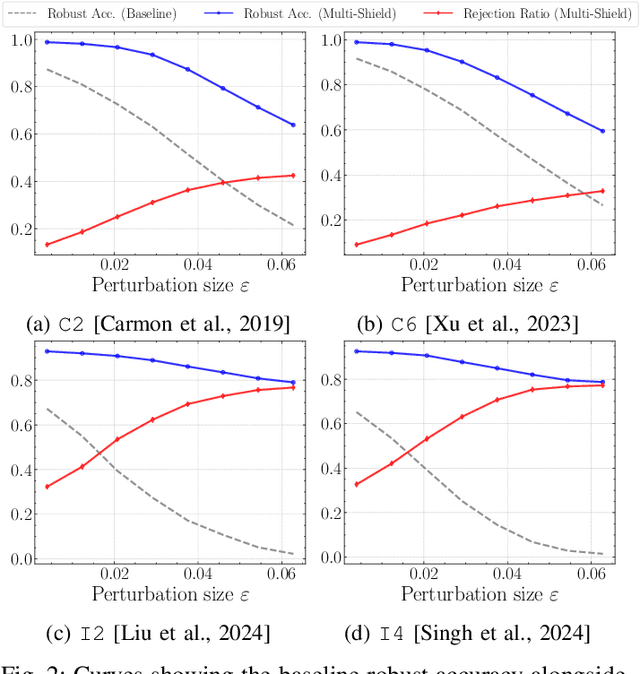
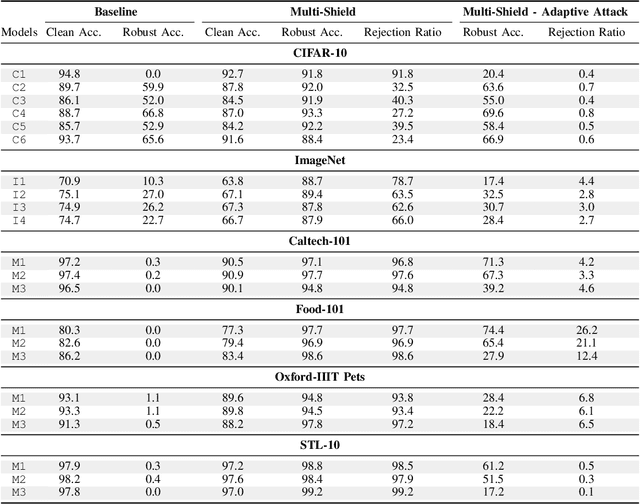
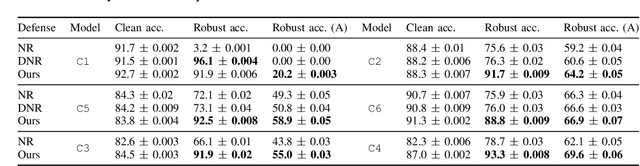
Deep Neural Networks are vulnerable to adversarial examples, i.e., carefully crafted input samples that can cause models to make incorrect predictions with high confidence. To mitigate these vulnerabilities, adversarial training and detection-based defenses have been proposed to strengthen models in advance. However, most of these approaches focus on a single data modality, overlooking the relationships between visual patterns and textual descriptions of the input. In this paper, we propose a novel defense, Multi-Shield, designed to combine and complement these defenses with multi-modal information to further enhance their robustness. Multi-Shield leverages multi-modal large language models to detect adversarial examples and abstain from uncertain classifications when there is no alignment between textual and visual representations of the input. Extensive evaluations on CIFAR-10 and ImageNet datasets, using robust and non-robust image classification models, demonstrate that Multi-Shield can be easily integrated to detect and reject adversarial examples, outperforming the original defenses.
ImageNet-Patch: A Dataset for Benchmarking Machine Learning Robustness against Adversarial Patches
Mar 07, 2022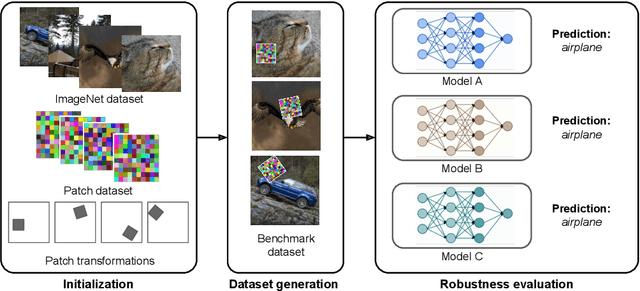
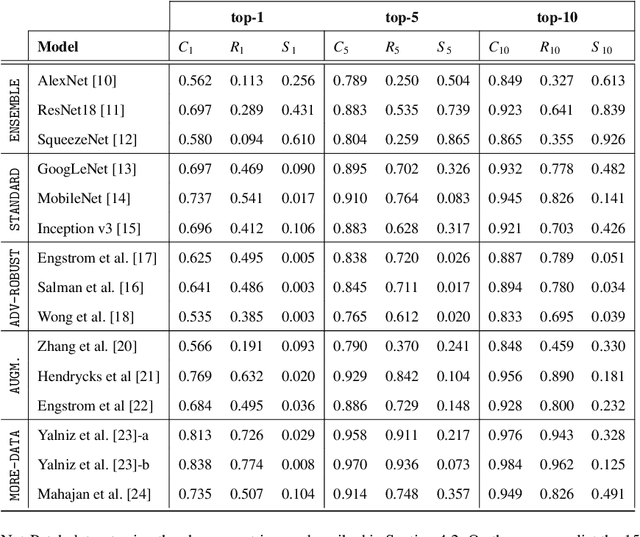
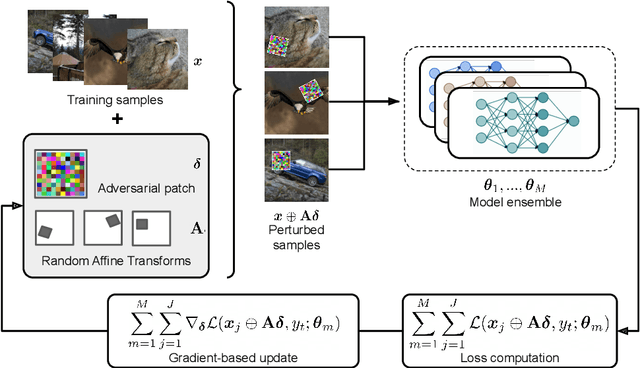
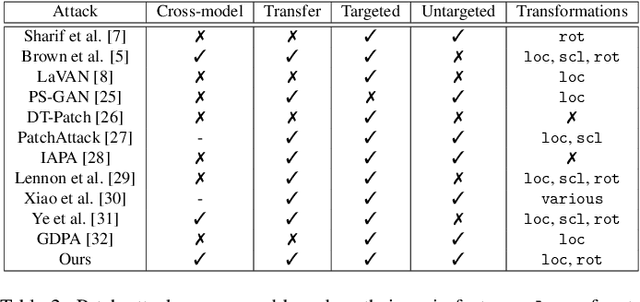
Adversarial patches are optimized contiguous pixel blocks in an input image that cause a machine-learning model to misclassify it. However, their optimization is computationally demanding, and requires careful hyperparameter tuning, potentially leading to suboptimal robustness evaluations. To overcome these issues, we propose ImageNet-Patch, a dataset to benchmark machine-learning models against adversarial patches. It consists of a set of patches, optimized to generalize across different models, and readily applicable to ImageNet data after preprocessing them with affine transformations. This process enables an approximate yet faster robustness evaluation, leveraging the transferability of adversarial perturbations. We showcase the usefulness of this dataset by testing the effectiveness of the computed patches against 127 models. We conclude by discussing how our dataset could be used as a benchmark for robustness, and how our methodology can be generalized to other domains. We open source our dataset and evaluation code at https://github.com/pralab/ImageNet-Patch.
Indicators of Attack Failure: Debugging and Improving Optimization of Adversarial Examples
Jun 18, 2021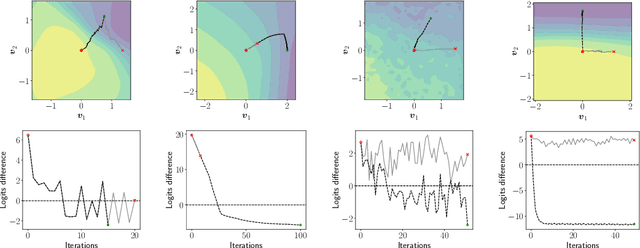
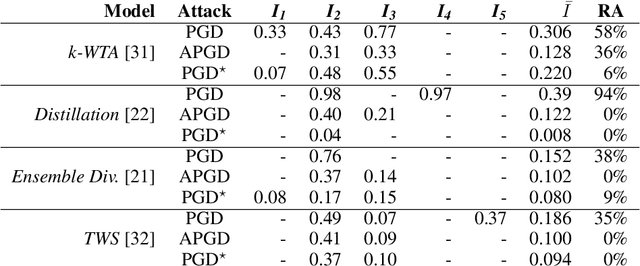
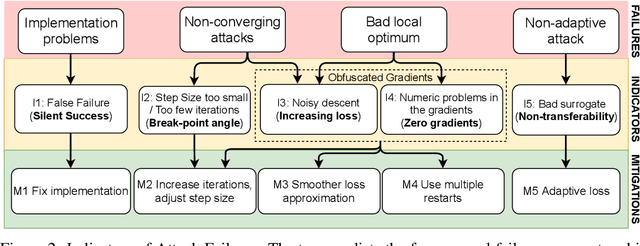
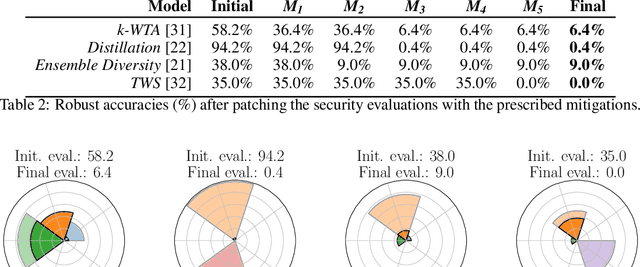
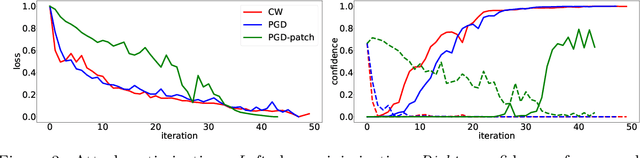
Evaluating robustness of machine-learning models to adversarial examples is a challenging problem. Many defenses have been shown to provide a false sense of security by causing gradient-based attacks to fail, and they have been broken under more rigorous evaluations. Although guidelines and best practices have been suggested to improve current adversarial robustness evaluations, the lack of automatic testing and debugging tools makes it difficult to apply these recommendations in a systematic manner. In this work, we overcome these limitations by (i) defining a set of quantitative indicators which unveil common failures in the optimization of gradient-based attacks, and (ii) proposing specific mitigation strategies within a systematic evaluation protocol. Our extensive experimental analysis shows that the proposed indicators of failure can be used to visualize, debug and improve current adversarial robustness evaluations, providing a first concrete step towards automatizing and systematizing current adversarial robustness evaluations. Our open-source code is available at: https://github.com/pralab/IndicatorsOfAttackFailure.
FADER: Fast Adversarial Example Rejection
Oct 18, 2020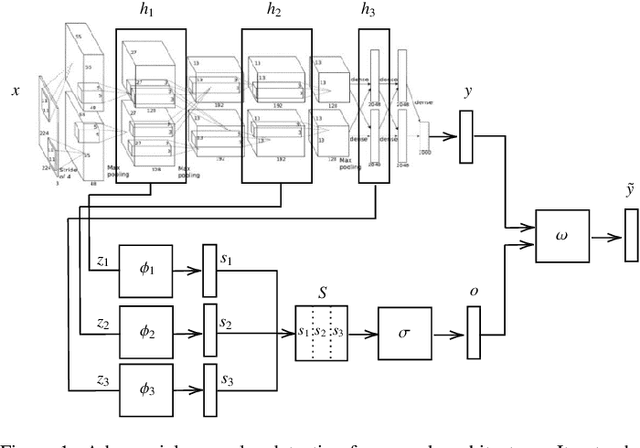
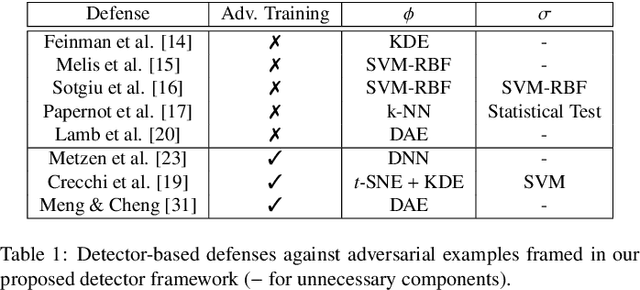
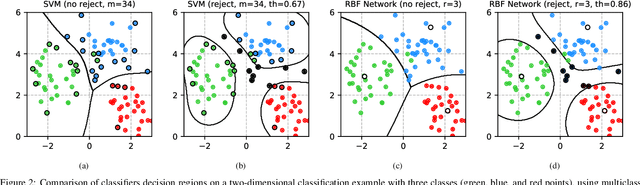

Deep neural networks are vulnerable to adversarial examples, i.e., carefully-crafted inputs that mislead classification at test time. Recent defenses have been shown to improve adversarial robustness by detecting anomalous deviations from legitimate training samples at different layer representations - a behavior normally exhibited by adversarial attacks. Despite technical differences, all aforementioned methods share a common backbone structure that we formalize and highlight in this contribution, as it can help in identifying promising research directions and drawbacks of existing methods. The first main contribution of this work is the review of these detection methods in the form of a unifying framework designed to accommodate both existing defenses and newer ones to come. In terms of drawbacks, the overmentioned defenses require comparing input samples against an oversized number of reference prototypes, possibly at different representation layers, dramatically worsening the test-time efficiency. Besides, such defenses are typically based on ensembling classifiers with heuristic methods, rather than optimizing the whole architecture in an end-to-end manner to better perform detection. As a second main contribution of this work, we introduce FADER, a novel technique for speeding up detection-based methods. FADER overcome the issues above by employing RBF networks as detectors: by fixing the number of required prototypes, the runtime complexity of adversarial examples detectors can be controlled. Our experiments outline up to 73x prototypes reduction compared to analyzed detectors for MNIST dataset and up to 50x for CIFAR10 dataset respectively, without sacrificing classification accuracy on both clean and adversarial data.
Can Domain Knowledge Alleviate Adversarial Attacks in Multi-Label Classifiers?
Jun 06, 2020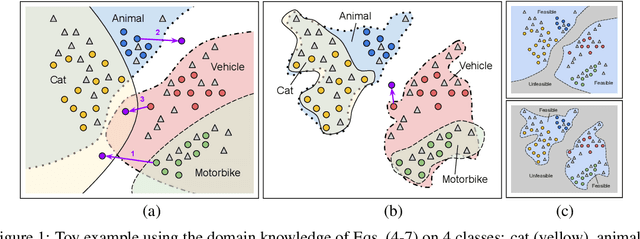

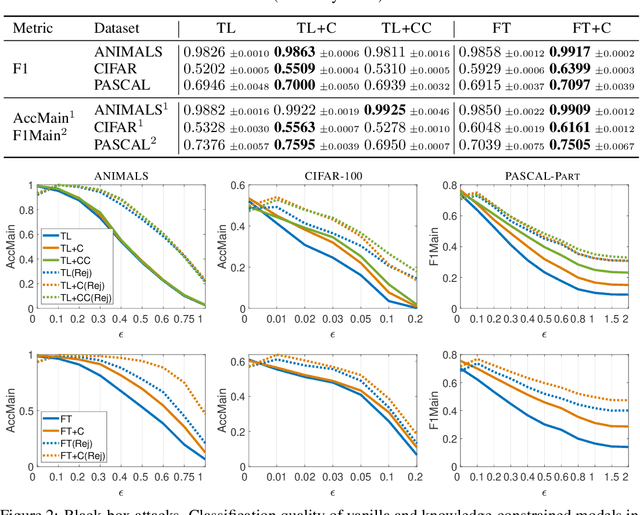
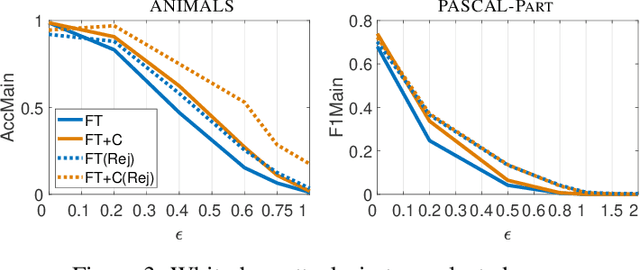
Adversarial attacks on machine learning-based classifiers, along with defense mechanisms, have been widely studied in the context of single-label classification problems. In this paper, we shift the attention to multi-label classification, where the availability of domain knowledge on the relationships among the considered classes may offer a natural way to spot incoherent predictions, i.e., predictions associated to adversarial examples lying outside of the training data distribution. We explore this intuition in a framework in which first-order logic knowledge is converted into constraints and injected into a semi-supervised learning problem. Within this setting, the constrained classifier learns to fulfill the domain knowledge over the marginal distribution, and can naturally reject samples with incoherent predictions. Even though our method does not exploit any knowledge of attacks during training, our experimental analysis surprisingly unveils that domain-knowledge constraints can help detect adversarial examples effectively, especially if such constraints are not known to the attacker. While we also show that an adaptive attack exploiting knowledge of the constraints may still deceive our classifier, it remains an open issue to understand how hard for an attacker would be to infer such constraints in practical cases. For this reason, we believe that our approach may provide a significant step towards designing robust multi-label classifiers.
secml: A Python Library for Secure and Explainable Machine Learning
Dec 20, 2019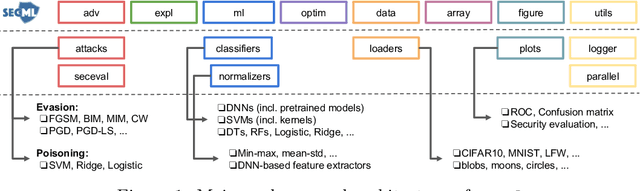

We present secml, an open-source Python library for secure and explainable machine learning. It implements the most popular attacks against machine learning, including not only test-time evasion attacks to generate adversarial examples against deep neural networks, but also training-time poisoning attacks against support vector machines and many other algorithms. These attacks enable evaluating the security of learning algorithms and of the corresponding defenses under both white-box and black-box threat models. To this end, secml provides built-in functions to compute security evaluation curves, showing how quickly classification performance decreases against increasing adversarial perturbations of the input data. secml also includes explainability methods to help understand why adversarial attacks succeed against a given model, by visualizing the most influential features and training prototypes contributing to each decision. It is distributed under the Apache License 2.0, and hosted at https://gitlab.com/secml/secml.
Deep Neural Rejection against Adversarial Examples
Oct 01, 2019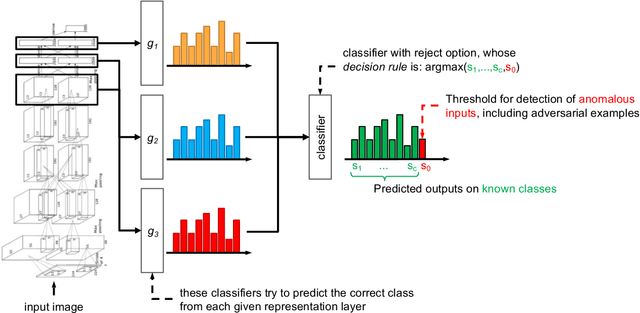
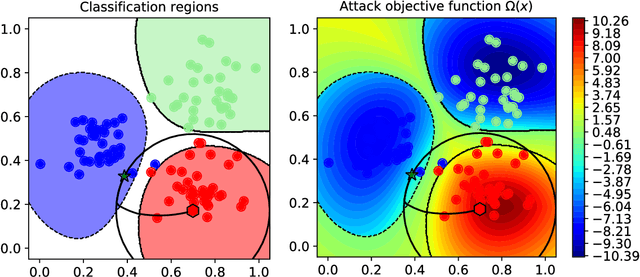
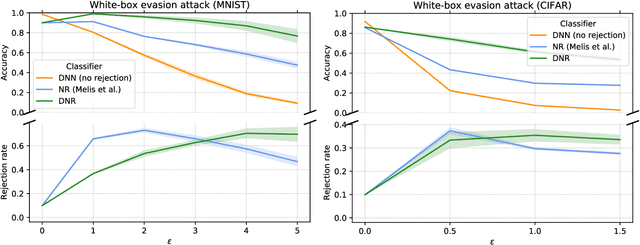
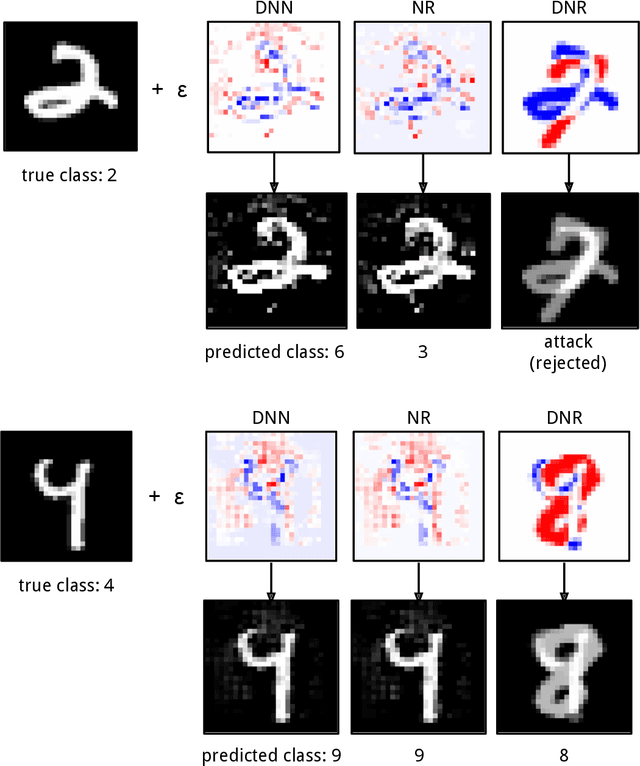
Despite the impressive performances reported by deep neural networks in different application domains, they remain largely vulnerable to adversarial examples, i.e., input samples that are carefully perturbed to cause misclassification at test time. In this work, we propose a deep neural rejection mechanism to detect adversarial examples, based on the idea of rejecting samples that exhibit anomalous feature representations at different network layers. With respect to competing approaches, our method does not require generating adversarial examples at training time, and it is less computationally demanding. To properly evaluate our method, we define an adaptive white-box attack that is aware of the defense mechanism and aims to bypass it. Under this worst-case setting, we empirically show that our approach outperforms previously-proposed methods that detect adversarial examples by only analyzing the feature representation provided by the output network layer.