 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBook your room in the Turing Hotel! A symmetric and distributed Turing Test with multiple AIs and humans
Mar 19, 2026In this paper, we report our experience with ``TuringHotel'', a novel extension of the Turing Test based on interactions within mixed communities of Large Language Models (LLMs) and human participants. The classical one-to-one interaction of the Turing Test is reinterpreted in a group setting, where both human and artificial agents engage in time-bounded discussions and, interestingly, are both judges and respondents. This community is instantiated in the novel platform UNaIVERSE (https://unaiverse.io), creating a ``World'' which defines the roles and interaction dynamics, facilitated by the platform's built-in programming tools. All communication occurs over an authenticated peer-to-peer network, ensuring that no third parties can access the exchange. The platform also provides a unified interface for humans, accessible via both mobile devices and laptops, that was a key component of the experience in this paper. Results of our experimentation involving 17 human participants and 19 LLMs revealed that current models are still sometimes confused as humans. Interestingly, there are several unexpected mistakes, suggesting that human fingerprints are still identifiable but not fully unambiguous, despite the high-quality language skills of artificial participants. We argue that this is the first experiment conducted in such a distributed setting, and that similar initiatives could be of national interest to support ongoing experiments and competitions aimed at monitoring the evolution of large language models over time.
DeepProofLog: Efficient Proving in Deep Stochastic Logic Programs
Nov 11, 2025Neurosymbolic (NeSy) AI aims to combine the strengths of neural architectures and symbolic reasoning to improve the accuracy, interpretability, and generalization capability of AI models. While logic inference on top of subsymbolic modules has been shown to effectively guarantee these properties, this often comes at the cost of reduced scalability, which can severely limit the usability of NeSy models. This paper introduces DeepProofLog (DPrL), a novel NeSy system based on stochastic logic programs, which addresses the scalability limitations of previous methods. DPrL parameterizes all derivation steps with neural networks, allowing efficient neural guidance over the proving system. Additionally, we establish a formal mapping between the resolution process of our deep stochastic logic programs and Markov Decision Processes, enabling the application of dynamic programming and reinforcement learning techniques for efficient inference and learning. This theoretical connection improves scalability for complex proof spaces and large knowledge bases. Our experiments on standard NeSy benchmarks and knowledge graph reasoning tasks demonstrate that DPrL outperforms existing state-of-the-art NeSy systems, advancing scalability to larger and more complex settings than previously possible.
Generative System Dynamics in Recurrent Neural Networks
Apr 16, 2025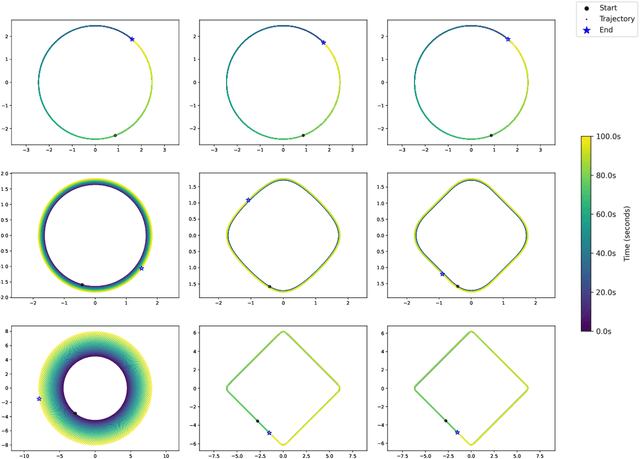



In this study, we investigate the continuous time dynamics of Recurrent Neural Networks (RNNs), focusing on systems with nonlinear activation functions. The objective of this work is to identify conditions under which RNNs exhibit perpetual oscillatory behavior, without converging to static fixed points. We establish that skew-symmetric weight matrices are fundamental to enable stable limit cycles in both linear and nonlinear configurations. We further demonstrate that hyperbolic tangent-like activation functions (odd, bounded, and continuous) preserve these oscillatory dynamics by ensuring motion invariants in state space. Numerical simulations showcase how nonlinear activation functions not only maintain limit cycles, but also enhance the numerical stability of the system integration process, mitigating those instabilities that are commonly associated with the forward Euler method. The experimental results of this analysis highlight practical considerations for designing neural architectures capable of capturing complex temporal dependencies, i.e., strategies for enhancing memorization skills in recurrent models.
From Arabic Text to Puzzles: LLM-Driven Development of Arabic Educational Crosswords
Jan 19, 2025We present an Arabic crossword puzzle generator from a given text that utilizes advanced language models such as GPT-4-Turbo, GPT-3.5-Turbo and Llama3-8B-Instruct, specifically developed for educational purposes, this innovative generator leverages a meticulously compiled dataset named Arabic-Clue-Instruct with over 50,000 entries encompassing text, answers, clues, and categories. This dataset is intricately designed to aid in the generation of pertinent clues linked to specific texts and keywords within defined categories. This project addresses the scarcity of advanced educational tools tailored for the Arabic language, promoting enhanced language learning and cognitive development. By providing a culturally and linguistically relevant tool, our objective is to make learning more engaging and effective through gamification and interactivity. Integrating state-of-the-art artificial intelligence with contemporary learning methodologies, this tool can generate crossword puzzles from any given educational text, thereby facilitating an interactive and enjoyable learning experience. This tool not only advances educational paradigms but also sets a new standard in interactive and cognitive learning technologies. The model and dataset are publicly available.
Advancing Student Writing Through Automated Syntax Feedback
Jan 13, 2025
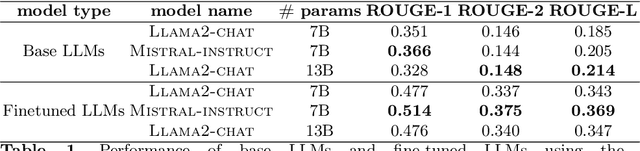

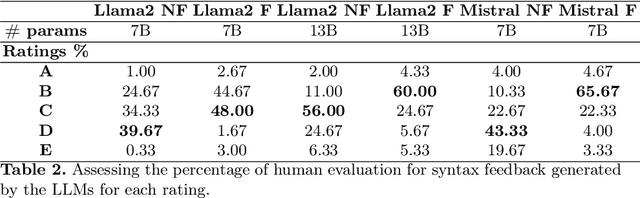
This study underscores the pivotal role of syntax feedback in augmenting the syntactic proficiency of students. Recognizing the challenges faced by learners in mastering syntactic nuances, we introduce a specialized dataset named Essay-Syntax-Instruct designed to enhance the understanding and application of English syntax among these students. Leveraging the capabilities of Large Language Models (LLMs) such as GPT3.5-Turbo, Llama-2-7b-chat-hf, Llama-2-13b-chat-hf, and Mistral-7B-Instruct-v0.2, this work embarks on a comprehensive fine-tuning process tailored to the syntax improvement task. Through meticulous evaluation, we demonstrate that the fine-tuned LLMs exhibit a marked improvement in addressing syntax-related challenges, thereby serving as a potent tool for students to identify and rectify their syntactic errors. The findings not only highlight the effectiveness of the proposed dataset in elevating the performance of LLMs for syntax enhancement but also illuminate a promising path for utilizing advanced language models to support language acquisition efforts. This research contributes to the broader field of language learning technology by showcasing the potential of LLMs in facilitating the linguistic development of Students.
Harnessing LLMs for Educational Content-Driven Italian Crossword Generation
Nov 25, 2024In this work, we unveil a novel tool for generating Italian crossword puzzles from text, utilizing advanced language models such as GPT-4o, Mistral-7B-Instruct-v0.3, and Llama3-8b-Instruct. Crafted specifically for educational applications, this cutting-edge generator makes use of the comprehensive Italian-Clue-Instruct dataset, which comprises over 30,000 entries including diverse text, solutions, and types of clues. This carefully assembled dataset is designed to facilitate the creation of contextually relevant clues in various styles associated with specific texts and keywords. The study delves into four distinctive styles of crossword clues: those without format constraints, those formed as definite determiner phrases, copular sentences, and bare noun phrases. Each style introduces unique linguistic structures to diversify clue presentation. Given the lack of sophisticated educational tools tailored to the Italian language, this project seeks to enhance learning experiences and cognitive development through an engaging, interactive platform. By meshing state-of-the-art AI with contemporary educational strategies, our tool can dynamically generate crossword puzzles from Italian educational materials, thereby providing an enjoyable and interactive learning environment. This technological advancement not only redefines educational paradigms but also sets a new benchmark for interactive and cognitive language learning solutions.
A Systematic Literature Review of Spatio-Temporal Graph Neural Network Models for Time Series Forecasting and Classification
Oct 29, 2024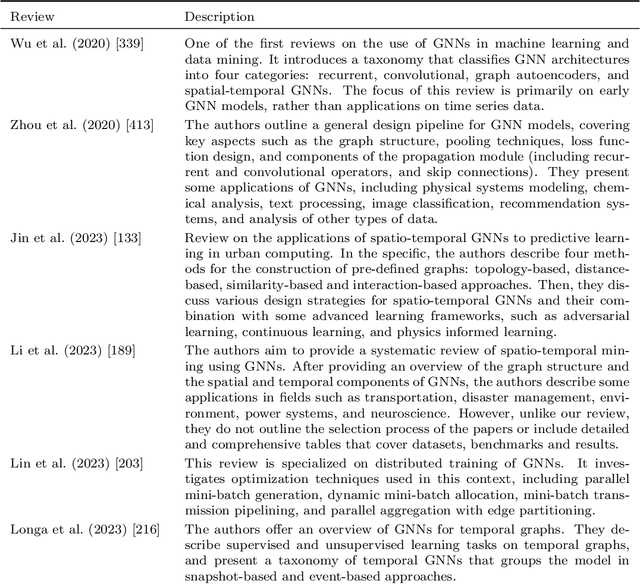
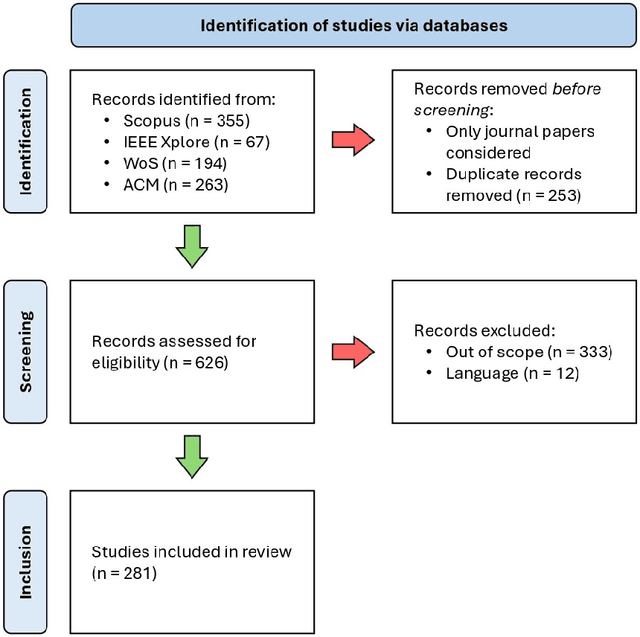
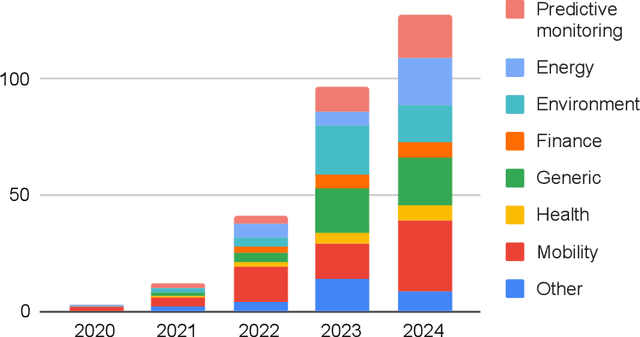
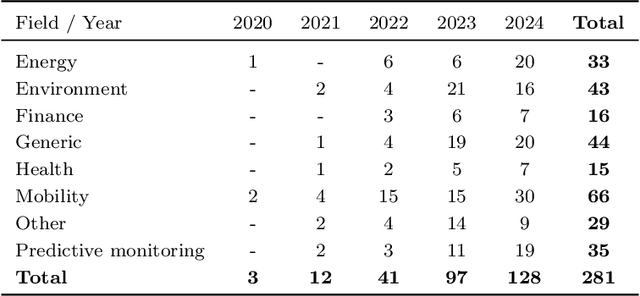
In recent years, spatio-temporal graph neural networks (GNNs) have attracted considerable interest in the field of time series analysis, due to their ability to capture dependencies among variables and across time points. The objective of the presented systematic literature review is hence to provide a comprehensive overview of the various modeling approaches and application domains of GNNs for time series classification and forecasting. A database search was conducted, and over 150 journal papers were selected for a detailed examination of the current state-of-the-art in the field. This examination is intended to offer to the reader a comprehensive collection of proposed models, links to related source code, available datasets, benchmark models, and fitting results. All this information is hoped to assist researchers in future studies. To the best of our knowledge, this is the first systematic literature review presenting a detailed comparison of the results of current spatio-temporal GNN models in different domains. In addition, in its final part this review discusses current limitations and challenges in the application of spatio-temporal GNNs, such as comparability, reproducibility, explainability, poor information capacity, and scalability.
A Unified Framework for Neural Computation and Learning Over Time
Sep 18, 2024This paper proposes Hamiltonian Learning, a novel unified framework for learning with neural networks "over time", i.e., from a possibly infinite stream of data, in an online manner, without having access to future information. Existing works focus on the simplified setting in which the stream has a known finite length or is segmented into smaller sequences, leveraging well-established learning strategies from statistical machine learning. In this paper, the problem of learning over time is rethought from scratch, leveraging tools from optimal control theory, which yield a unifying view of the temporal dynamics of neural computations and learning. Hamiltonian Learning is based on differential equations that: (i) can be integrated without the need of external software solvers; (ii) generalize the well-established notion of gradient-based learning in feed-forward and recurrent networks; (iii) open to novel perspectives. The proposed framework is showcased by experimentally proving how it can recover gradient-based learning, comparing it to out-of-the box optimizers, and describing how it is flexible enough to switch from fully-local to partially/non-local computational schemes, possibly distributed over multiple devices, and BackPropagation without storing activations. Hamiltonian Learning is easy to implement and can help researches approach in a principled and innovative manner the problem of learning over time.
Continual Learning of Conjugated Visual Representations through Higher-order Motion Flows
Sep 16, 2024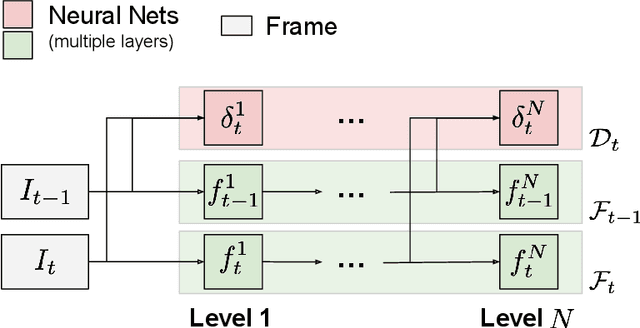
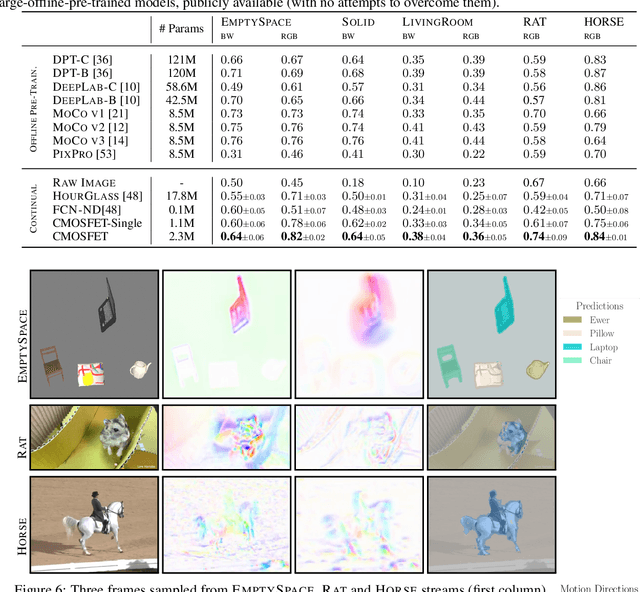
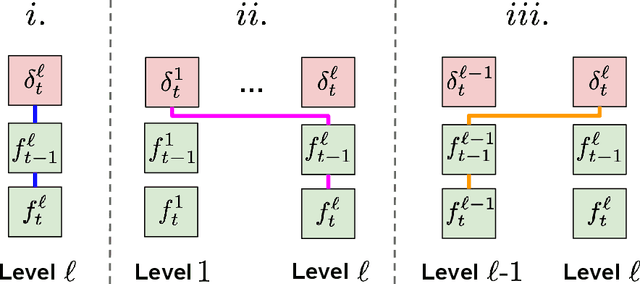

Learning with neural networks from a continuous stream of visual information presents several challenges due to the non-i.i.d. nature of the data. However, it also offers novel opportunities to develop representations that are consistent with the information flow. In this paper we investigate the case of unsupervised continual learning of pixel-wise features subject to multiple motion-induced constraints, therefore named motion-conjugated feature representations. Differently from existing approaches, motion is not a given signal (either ground-truth or estimated by external modules), but is the outcome of a progressive and autonomous learning process, occurring at various levels of the feature hierarchy. Multiple motion flows are estimated with neural networks and characterized by different levels of abstractions, spanning from traditional optical flow to other latent signals originating from higher-level features, hence called higher-order motions. Continuously learning to develop consistent multi-order flows and representations is prone to trivial solutions, which we counteract by introducing a self-supervised contrastive loss, spatially-aware and based on flow-induced similarity. We assess our model on photorealistic synthetic streams and real-world videos, comparing to pre-trained state-of-the art feature extractors (also based on Transformers) and to recent unsupervised learning models, significantly outperforming these alternatives.
Dynamic Decoupling of Placid Terminal Attractor-based Gradient Descent Algorithm
Sep 10, 2024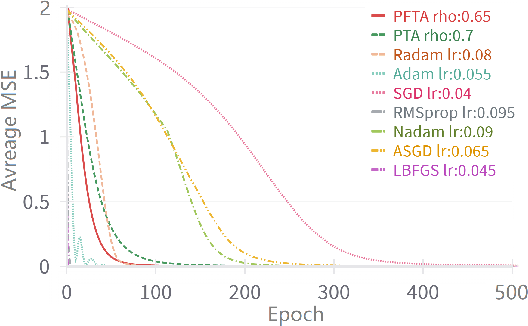
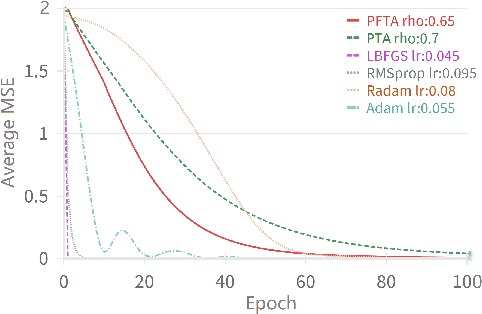
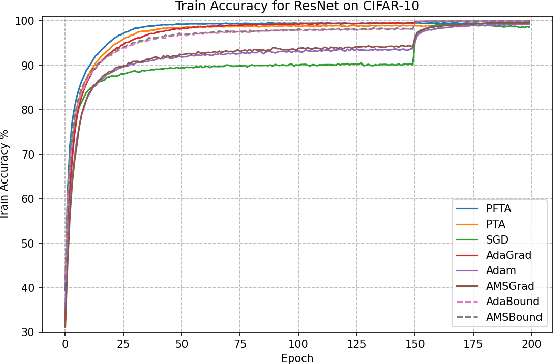
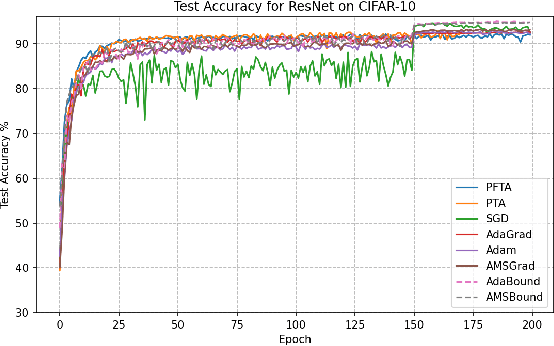
Gradient descent (GD) and stochastic gradient descent (SGD) have been widely used in a large number of application domains. Therefore, understanding the dynamics of GD and improving its convergence speed is still of great importance. This paper carefully analyzes the dynamics of GD based on the terminal attractor at different stages of its gradient flow. On the basis of the terminal sliding mode theory and the terminal attractor theory, four adaptive learning rates are designed. Their performances are investigated in light of a detailed theoretical investigation, and the running times of the learning procedures are evaluated and compared. The total times of their learning processes are also studied in detail. To evaluate their effectiveness, various simulation results are investigated on a function approximation problem and an image classification problem.