 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning of Conjugated Visual Representations through Higher-order Motion Flows
Paper and Code
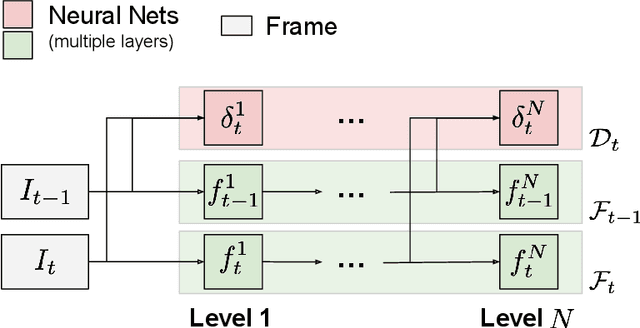
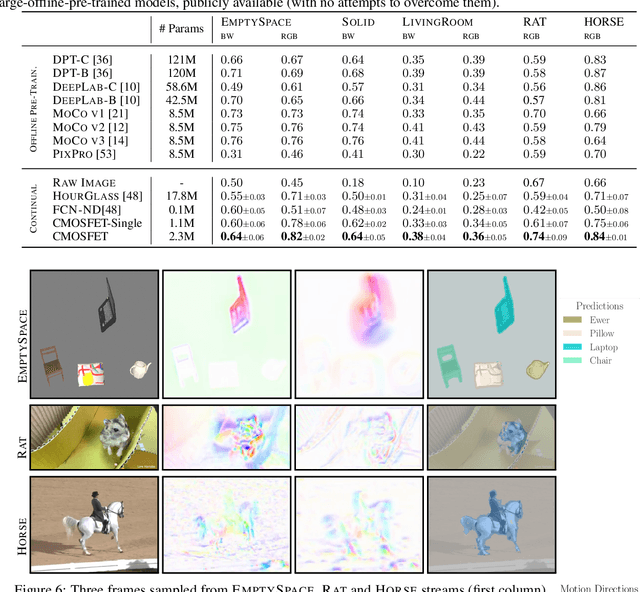
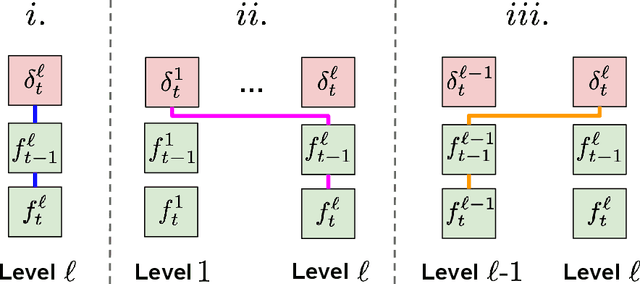

Learning with neural networks from a continuous stream of visual information presents several challenges due to the non-i.i.d. nature of the data. However, it also offers novel opportunities to develop representations that are consistent with the information flow. In this paper we investigate the case of unsupervised continual learning of pixel-wise features subject to multiple motion-induced constraints, therefore named motion-conjugated feature representations. Differently from existing approaches, motion is not a given signal (either ground-truth or estimated by external modules), but is the outcome of a progressive and autonomous learning process, occurring at various levels of the feature hierarchy. Multiple motion flows are estimated with neural networks and characterized by different levels of abstractions, spanning from traditional optical flow to other latent signals originating from higher-level features, hence called higher-order motions. Continuously learning to develop consistent multi-order flows and representations is prone to trivial solutions, which we counteract by introducing a self-supervised contrastive loss, spatially-aware and based on flow-induced similarity. We assess our model on photorealistic synthetic streams and real-world videos, comparing to pre-trained state-of-the art feature extractors (also based on Transformers) and to recent unsupervised learning models, significantly outperforming these alternatives.