 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Evaluate Autonomous Behaviour in Human-Robot Interaction
Jul 08, 2025Evaluating and comparing the performance of autonomous Humanoid Robots is challenging, as success rate metrics are difficult to reproduce and fail to capture the complexity of robot movement trajectories, critical in Human-Robot Interaction and Collaboration (HRIC). To address these challenges, we propose a general evaluation framework that measures the quality of Imitation Learning (IL) methods by focusing on trajectory performance. We devise the Neural Meta Evaluator (NeME), a deep learning model trained to classify actions from robot joint trajectories. NeME serves as a meta-evaluator to compare the performance of robot control policies, enabling policy evaluation without requiring human involvement in the loop. We validate our framework on ergoCub, a humanoid robot, using teleoperation data and comparing IL methods tailored to the available platform. The experimental results indicate that our method is more aligned with the success rate obtained on the robot than baselines, offering a reproducible, systematic, and insightful means for comparing the performance of multimodal imitation learning approaches in complex HRI tasks.
A Unified Framework for Neural Computation and Learning Over Time
Sep 18, 2024This paper proposes Hamiltonian Learning, a novel unified framework for learning with neural networks "over time", i.e., from a possibly infinite stream of data, in an online manner, without having access to future information. Existing works focus on the simplified setting in which the stream has a known finite length or is segmented into smaller sequences, leveraging well-established learning strategies from statistical machine learning. In this paper, the problem of learning over time is rethought from scratch, leveraging tools from optimal control theory, which yield a unifying view of the temporal dynamics of neural computations and learning. Hamiltonian Learning is based on differential equations that: (i) can be integrated without the need of external software solvers; (ii) generalize the well-established notion of gradient-based learning in feed-forward and recurrent networks; (iii) open to novel perspectives. The proposed framework is showcased by experimentally proving how it can recover gradient-based learning, comparing it to out-of-the box optimizers, and describing how it is flexible enough to switch from fully-local to partially/non-local computational schemes, possibly distributed over multiple devices, and BackPropagation without storing activations. Hamiltonian Learning is easy to implement and can help researches approach in a principled and innovative manner the problem of learning over time.
Continual Learning of Conjugated Visual Representations through Higher-order Motion Flows
Sep 16, 2024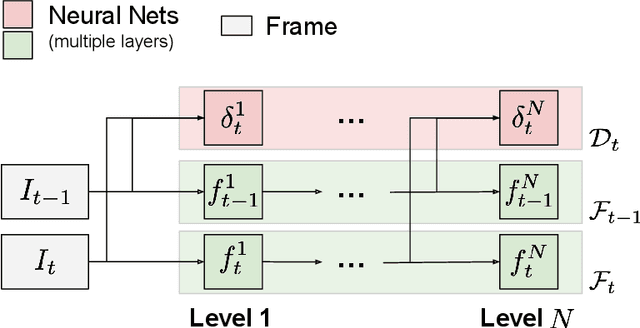
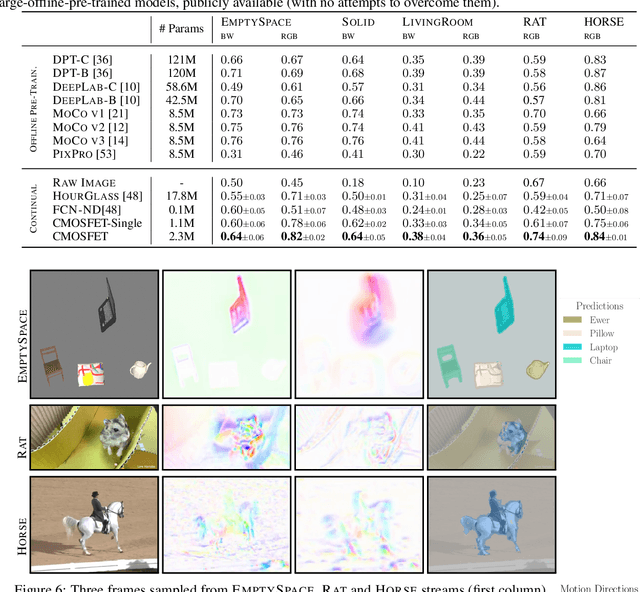
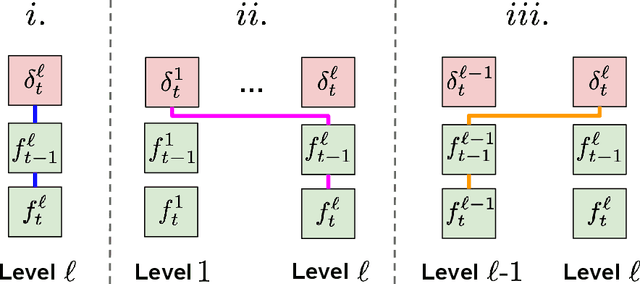

Learning with neural networks from a continuous stream of visual information presents several challenges due to the non-i.i.d. nature of the data. However, it also offers novel opportunities to develop representations that are consistent with the information flow. In this paper we investigate the case of unsupervised continual learning of pixel-wise features subject to multiple motion-induced constraints, therefore named motion-conjugated feature representations. Differently from existing approaches, motion is not a given signal (either ground-truth or estimated by external modules), but is the outcome of a progressive and autonomous learning process, occurring at various levels of the feature hierarchy. Multiple motion flows are estimated with neural networks and characterized by different levels of abstractions, spanning from traditional optical flow to other latent signals originating from higher-level features, hence called higher-order motions. Continuously learning to develop consistent multi-order flows and representations is prone to trivial solutions, which we counteract by introducing a self-supervised contrastive loss, spatially-aware and based on flow-induced similarity. We assess our model on photorealistic synthetic streams and real-world videos, comparing to pre-trained state-of-the art feature extractors (also based on Transformers) and to recent unsupervised learning models, significantly outperforming these alternatives.
Human-inspired Explanations for Vision Transformers and Convolutional Neural Networks
Aug 20, 2024We introduce Foveation-based Explanations (FovEx), a novel human-inspired visual explainability (XAI) method for Deep Neural Networks. Our method achieves state-of-the-art performance on both transformer (on 4 out of 5 metrics) and convolutional models (on 3 out of 5 metrics), demonstrating its versatility. Furthermore, we show the alignment between the explanation map produced by FovEx and human gaze patterns (+14\% in NSS compared to RISE, +203\% in NSS compared to gradCAM), enhancing our confidence in FovEx's ability to close the interpretation gap between humans and machines.
FovEx: Human-inspired Explanations for Vision Transformers and Convolutional Neural Networks
Aug 04, 2024Explainability in artificial intelligence (XAI) remains a crucial aspect for fostering trust and understanding in machine learning models. Current visual explanation techniques, such as gradient-based or class-activation-based methods, often exhibit a strong dependence on specific model architectures. Conversely, perturbation-based methods, despite being model-agnostic, are computationally expensive as they require evaluating models on a large number of forward passes. In this work, we introduce Foveation-based Explanations (FovEx), a novel XAI method inspired by human vision. FovEx seamlessly integrates biologically inspired perturbations by iteratively creating foveated renderings of the image and combines them with gradient-based visual explorations to determine locations of interest efficiently. These locations are selected to maximize the performance of the model to be explained with respect to the downstream task and then combined to generate an attribution map. We provide a thorough evaluation with qualitative and quantitative assessments on established benchmarks. Our method achieves state-of-the-art performance on both transformers (on 4 out of 5 metrics) and convolutional models (on 3 out of 5 metrics), demonstrating its versatility among various architectures. Furthermore, we show the alignment between the explanation map produced by FovEx and human gaze patterns (+14\% in NSS compared to RISE, +203\% in NSS compared to GradCAM). This comparison enhances our confidence in FovEx's ability to close the interpretation gap between humans and machines.
State-Space Modeling in Long Sequence Processing: A Survey on Recurrence in the Transformer Era
Jun 13, 2024Effectively learning from sequential data is a longstanding goal of Artificial Intelligence, especially in the case of long sequences. From the dawn of Machine Learning, several researchers engaged in the search of algorithms and architectures capable of processing sequences of patterns, retaining information about the past inputs while still leveraging the upcoming data, without losing precious long-term dependencies and correlations. While such an ultimate goal is inspired by the human hallmark of continuous real-time processing of sensory information, several solutions simplified the learning paradigm by artificially limiting the processed context or dealing with sequences of limited length, given in advance. These solutions were further emphasized by the large ubiquity of Transformers, that have initially shaded the role of Recurrent Neural Nets. However, recurrent networks are facing a strong recent revival due to the growing popularity of (deep) State-Space models and novel instances of large-context Transformers, which are both based on recurrent computations to go beyond several limits of currently ubiquitous technologies. In fact, the fast development of Large Language Models enhanced the interest in efficient solutions to process data over time. This survey provides an in-depth summary of the latest approaches that are based on recurrent models for sequential data processing. A complete taxonomy over the latest trends in architectural and algorithmic solutions is reported and discussed, guiding researchers in this appealing research field. The emerging picture suggests that there is room for thinking of novel routes, constituted by learning algorithms which depart from the standard Backpropagation Through Time, towards a more realistic scenario where patterns are effectively processed online, leveraging local-forward computations, opening to further research on this topic.
On the Resurgence of Recurrent Models for Long Sequences -- Survey and Research Opportunities in the Transformer Era
Feb 14, 2024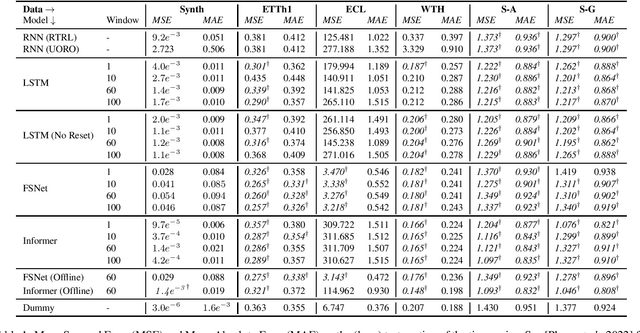
A longstanding challenge for the Machine Learning community is the one of developing models that are capable of processing and learning from very long sequences of data. The outstanding results of Transformers-based networks (e.g., Large Language Models) promotes the idea of parallel attention as the key to succeed in such a challenge, obfuscating the role of classic sequential processing of Recurrent Models. However, in the last few years, researchers who were concerned by the quadratic complexity of self-attention have been proposing a novel wave of neural models, which gets the best from the two worlds, i.e., Transformers and Recurrent Nets. Meanwhile, Deep Space-State Models emerged as robust approaches to function approximation over time, thus opening a new perspective in learning from sequential data, followed by many people in the field and exploited to implement a special class of (linear) Recurrent Neural Networks. This survey is aimed at providing an overview of these trends framed under the unifying umbrella of Recurrence. Moreover, it emphasizes novel research opportunities that become prominent when abandoning the idea of processing long sequences whose length is known-in-advance for the more realistic setting of potentially infinite-length sequences, thus intersecting the field of lifelong-online learning from streamed data.
Neural Time-Reversed Generalized Riccati Equation
Dec 14, 2023


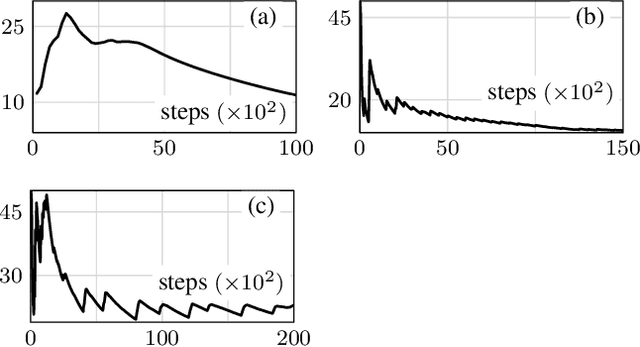
Optimal control deals with optimization problems in which variables steer a dynamical system, and its outcome contributes to the objective function. Two classical approaches to solving these problems are Dynamic Programming and the Pontryagin Maximum Principle. In both approaches, Hamiltonian equations offer an interpretation of optimality through auxiliary variables known as costates. However, Hamiltonian equations are rarely used due to their reliance on forward-backward algorithms across the entire temporal domain. This paper introduces a novel neural-based approach to optimal control, with the aim of working forward-in-time. Neural networks are employed not only for implementing state dynamics but also for estimating costate variables. The parameters of the latter network are determined at each time step using a newly introduced local policy referred to as the time-reversed generalized Riccati equation. This policy is inspired by a result discussed in the Linear Quadratic (LQ) problem, which we conjecture stabilizes state dynamics. We support this conjecture by discussing experimental results from a range of optimal control case studies.
Continual Learning with Pretrained Backbones by Tuning in the Input Space
Jun 08, 2023The intrinsic difficulty in adapting deep learning models to non-stationary environments limits the applicability of neural networks to real-world tasks. This issue is critical in practical supervised learning settings, such as the ones in which a pre-trained model computes projections toward a latent space where different task predictors are sequentially learned over time. As a matter of fact, incrementally fine-tuning the whole model to better adapt to new tasks usually results in catastrophic forgetting, with decreasing performance over the past experiences and losing valuable knowledge from the pre-training stage. In this paper, we propose a novel strategy to make the fine-tuning procedure more effective, by avoiding to update the pre-trained part of the network and learning not only the usual classification head, but also a set of newly-introduced learnable parameters that are responsible for transforming the input data. This process allows the network to effectively leverage the pre-training knowledge and find a good trade-off between plasticity and stability with modest computational efforts, thus especially suitable for on-the-edge settings. Our experiments on four image classification problems in a continual learning setting confirm the quality of the proposed approach when compared to several fine-tuning procedures and to popular continual learning methods.
PARTIME: Scalable and Parallel Processing Over Time with Deep Neural Networks
Oct 17, 2022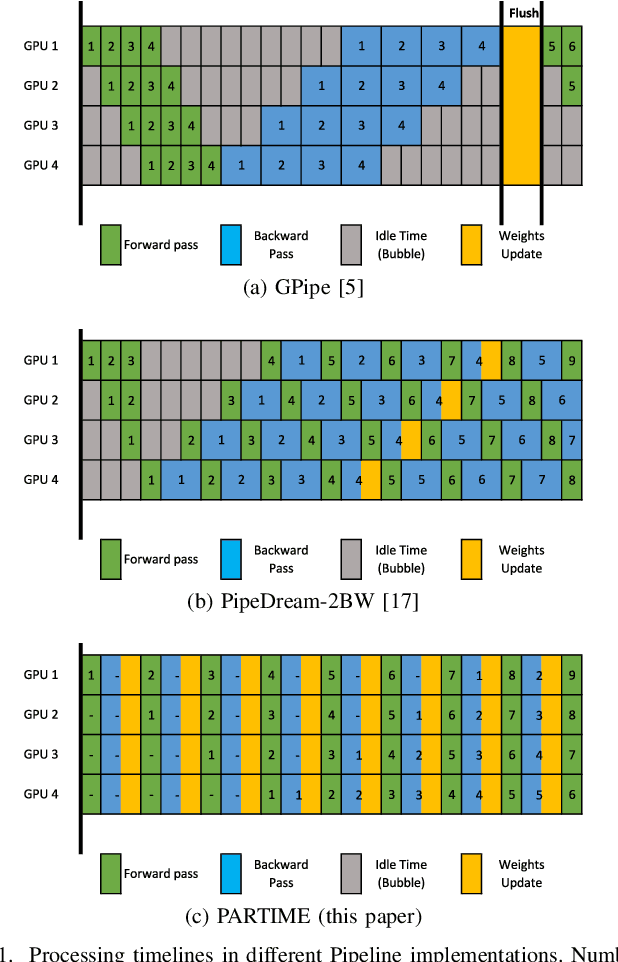


In this paper, we present PARTIME, a software library written in Python and based on PyTorch, designed specifically to speed up neural networks whenever data is continuously streamed over time, for both learning and inference. Existing libraries are designed to exploit data-level parallelism, assuming that samples are batched, a condition that is not naturally met in applications that are based on streamed data. Differently, PARTIME starts processing each data sample at the time in which it becomes available from the stream. PARTIME wraps the code that implements a feed-forward multi-layer network and it distributes the layer-wise processing among multiple devices, such as Graphics Processing Units (GPUs). Thanks to its pipeline-based computational scheme, PARTIME allows the devices to perform computations in parallel. At inference time this results in scaling capabilities that are theoretically linear with respect to the number of devices. During the learning stage, PARTIME can leverage the non-i.i.d. nature of the streamed data with samples that are smoothly evolving over time for efficient gradient computations. Experiments are performed in order to empirically compare PARTIME with classic non-parallel neural computations in online learning, distributing operations on up to 8 NVIDIA GPUs, showing significant speedups that are almost linear in the number of devices, mitigating the impact of the data transfer overhead.