 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPS: A Synthetic Dataset for Probing Vision Models in a Controlled 3D Scene Space
May 19, 2026Modern vision models achieve strong performance on standard benchmarks, yet their aggregate accuracy reveals little about which scene properties drive their predictions. Existing robustness benchmarks provide important stress tests, but typically manipulate global 2D image properties, rely on entangled real-world variation, or cover only a limited set of 3D objects and scene parameters. We introduce MAPS (Manifolds of Artificial Parametric Scenes), a scalable instrument for controlled attribution of vision model behavior to scene parameters. MAPS comprises 2,618 curated photorealistic 3D meshes validated for recognizability across 560 ImageNet classes and provides a Blender-based rendering pipeline for on-demand image generation under continuous variation of nine independent scene-factors spanning background, camera, and lighting, extensible to other factors. To showcase its applicability, we use MAPS to evaluate 20 convolutional and transformer-based models by quantifying their reliance on these scene factors through regression-based sensitivity analysis. We find a near-universal failure axis across all tested architectures: camera distance and elevation consistently dominate recognition failure regardless of ImageNet accuracy. However, the full sensitivity structure reveals that modern CNNs and transformers cluster together, distinct from older architectures, suggesting that fine-grained architectural design choices, rather than the coarse CNN-versus-transformer distinction, are the stronger determinant of sensitivity profiles.
Mechanisms of Object Localization in Vision-Language Models
May 19, 2026Visually-grounded language models (VLMs) are highly effective in linking visual and textual information, yet they often struggle with basic classification and localization tasks. While classification mechanisms have been studied more extensively, the processes that support object localization remain poorly understood. In this work, we investigate two representative families, LLaVA-1.5 and InternVL-3.5, using a suite of mechanistic interpretability tools, including token ablations, attention knockout, and causal mediation analysis. We find that localization is driven by a containerization mechanism in which object-aligned tokens define the spatial extent of the object, while the semantic arrangement of tokens within those boundaries is largely irrelevant to the predicted box. Only a very small set of attention heads mediates the causal effect for both classification and localization, concentrating in early-mid layers for LLaVA and mid-late layers for InternVL. The two tasks share some early processing but ultimately depend on largely distinct specialized heads. Overall, we provide the first layer- and head-level account of localization in VLMs, revealing narrow computational pathways that can guide future model design and grounding objectives.
Shortcut Mitigation via Spurious-Positive Samples
May 13, 2026Shortcut mitigation strategies commonly rely on training data annotations, group-balanced held-out data or the presence of all groups, i.e., all combinations of (spurious) attributes and classes, in the training data. However, these requirements are rarely met in practice. We instead propose a method for targeted model analysis to identify a small set of instances in which the model relies on spurious attributes. Using that set and following ``this feature should not be used for prediction'' reasoning, we identify highly relevant neurons in an intermediate layer and regularize their impact. This ensures that models learn to depend on informative features rather than being right for the wrong reasons, thereby improving robustness without requiring additional balanced held-out data or annotations.
Evaluation of Randomization through Style Transfer for Enhanced Domain Generalization
Apr 07, 2026Deep learning models for computer vision often suffer from poor generalization when deployed in real-world settings, especially when trained on synthetic data due to the well-known Sim2Real gap. Despite the growing popularity of style transfer as a data augmentation strategy for domain generalization, the literature contains unresolved contradictions regarding three key design axes: the diversity of the style pool, the role of texture complexity, and the choice of style source. We present a systematic empirical study that isolates and evaluates each of these factors for driving scene understanding, resolving inconsistencies in prior work. Our findings show that (i) expanding the style pool yields larger gains than repeated augmentation with few styles, (ii) texture complexity has no significant effect when the pool is sufficiently large, and (iii) diverse artistic styles outperform domain-aligned alternatives. Guided by these insights, we derive StyleMixDG (Style-Mixing for Domain Generalization), a lightweight, model-agnostic augmentation recipe that requires no architectural modifications or additional losses. Evaluated on the GTAV $\rightarrow$ {BDD100k, Cityscapes, Mapillary Vistas} benchmark, StyleMixDG demonstrates consistent improvements over strong baselines, confirming that the empirically identified design principles translate into practical gains. The code will be released on GitHub.
Temporal Slowness in Central Vision Drives Semantic Object Learning
Feb 04, 2026Humans acquire semantic object representations from egocentric visual streams with minimal supervision. Importantly, the visual system processes with high resolution only the center of its field of view and learns similar representations for visual inputs occurring close in time. This emphasizes slowly changing information around gaze locations. This study investigates the role of central vision and slowness learning in the formation of semantic object representations from human-like visual experience. We simulate five months of human-like visual experience using the Ego4D dataset and generate gaze coordinates with a state-of-the-art gaze prediction model. Using these predictions, we extract crops that mimic central vision and train a time-contrastive Self-Supervised Learning model on them. Our results show that combining temporal slowness and central vision improves the encoding of different semantic facets of object representations. Specifically, focusing on central vision strengthens the extraction of foreground object features, while considering temporal slowness, especially during fixational eye movements, allows the model to encode broader semantic information about objects. These findings provide new insights into the mechanisms by which humans may develop semantic object representations from natural visual experience.
The Representational Alignment between Humans and Language Models is implicitly driven by a Concreteness Effect
May 21, 2025The nouns of our language refer to either concrete entities (like a table) or abstract concepts (like justice or love), and cognitive psychology has established that concreteness influences how words are processed. Accordingly, understanding how concreteness is represented in our mind and brain is a central question in psychology, neuroscience, and computational linguistics. While the advent of powerful language models has allowed for quantitative inquiries into the nature of semantic representations, it remains largely underexplored how they represent concreteness. Here, we used behavioral judgments to estimate semantic distances implicitly used by humans, for a set of carefully selected abstract and concrete nouns. Using Representational Similarity Analysis, we find that the implicit representational space of participants and the semantic representations of language models are significantly aligned. We also find that both representational spaces are implicitly aligned to an explicit representation of concreteness, which was obtained from our participants using an additional concreteness rating task. Importantly, using ablation experiments, we demonstrate that the human-to-model alignment is substantially driven by concreteness, but not by other important word characteristics established in psycholinguistics. These results indicate that humans and language models converge on the concreteness dimension, but not on other dimensions.
Human Gaze Boosts Object-Centered Representation Learning
Jan 06, 2025Recent self-supervised learning (SSL) models trained on human-like egocentric visual inputs substantially underperform on image recognition tasks compared to humans. These models train on raw, uniform visual inputs collected from head-mounted cameras. This is different from humans, as the anatomical structure of the retina and visual cortex relatively amplifies the central visual information, i.e. around humans' gaze location. This selective amplification in humans likely aids in forming object-centered visual representations. Here, we investigate whether focusing on central visual information boosts egocentric visual object learning. We simulate 5-months of egocentric visual experience using the large-scale Ego4D dataset and generate gaze locations with a human gaze prediction model. To account for the importance of central vision in humans, we crop the visual area around the gaze location. Finally, we train a time-based SSL model on these modified inputs. Our experiments demonstrate that focusing on central vision leads to better object-centered representations. Our analysis shows that the SSL model leverages the temporal dynamics of the gaze movements to build stronger visual representations. Overall, our work marks a significant step toward bio-inspired learning of visual representations.
Efficient Unsupervised Shortcut Learning Detection and Mitigation in Transformers
Jan 01, 2025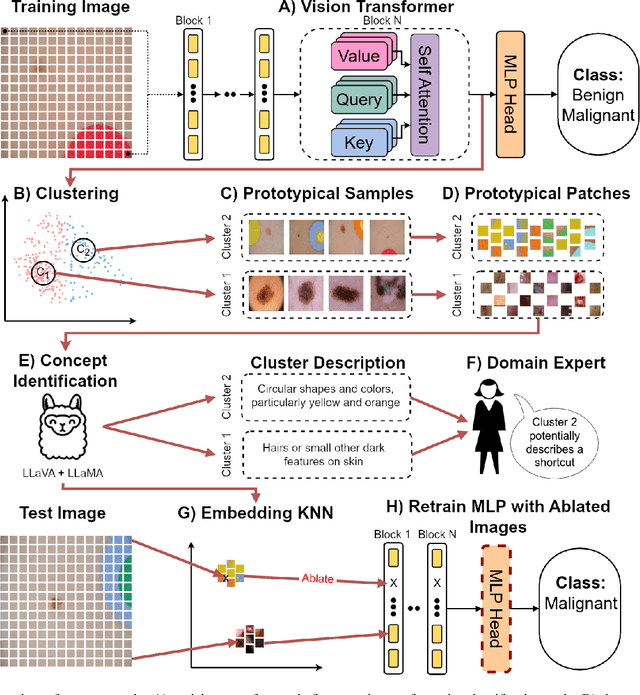
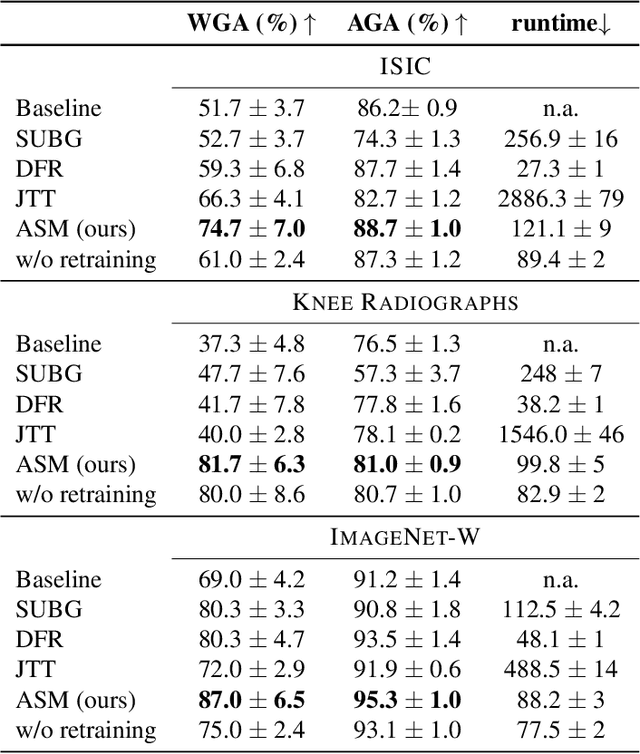


Shortcut learning, i.e., a model's reliance on undesired features not directly relevant to the task, is a major challenge that severely limits the applications of machine learning algorithms, particularly when deploying them to assist in making sensitive decisions, such as in medical diagnostics. In this work, we leverage recent advancements in machine learning to create an unsupervised framework that is capable of both detecting and mitigating shortcut learning in transformers. We validate our method on multiple datasets. Results demonstrate that our framework significantly improves both worst-group accuracy (samples misclassified due to shortcuts) and average accuracy, while minimizing human annotation effort. Moreover, we demonstrate that the detected shortcuts are meaningful and informative to human experts, and that our framework is computationally efficient, allowing it to be run on consumer hardware.
On Explaining Knowledge Distillation: Measuring and Visualising the Knowledge Transfer Process
Dec 18, 2024
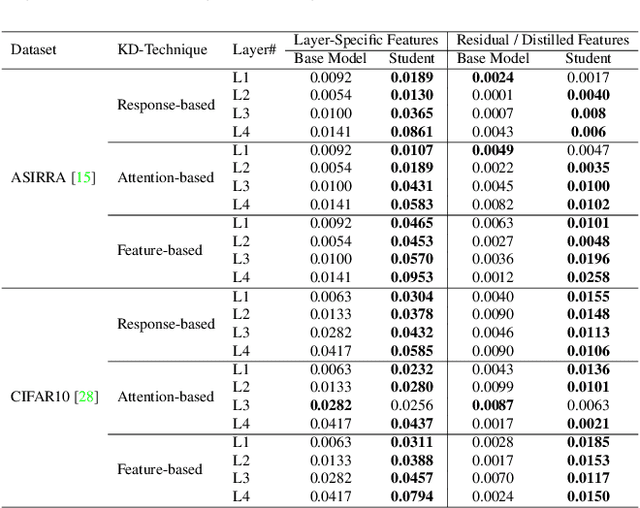
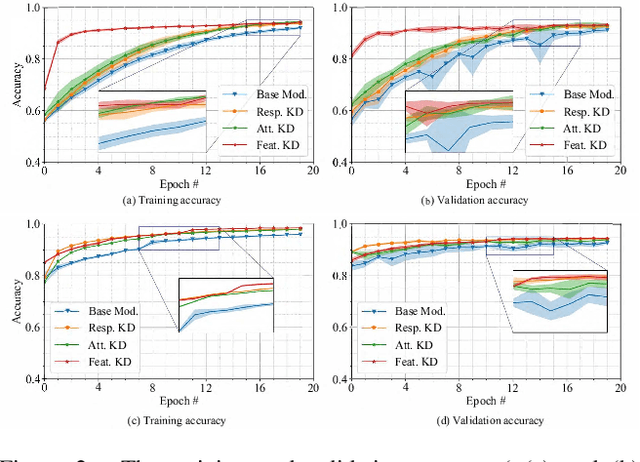
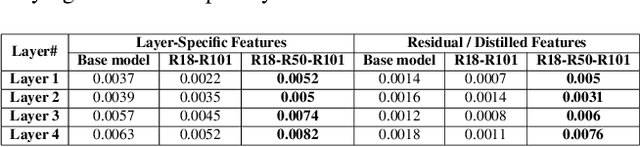
Knowledge distillation (KD) remains challenging due to the opaque nature of the knowledge transfer process from a Teacher to a Student, making it difficult to address certain issues related to KD. To address this, we proposed UniCAM, a novel gradient-based visual explanation method, which effectively interprets the knowledge learned during KD. Our experimental results demonstrate that with the guidance of the Teacher's knowledge, the Student model becomes more efficient, learning more relevant features while discarding those that are not relevant. We refer to the features learned with the Teacher's guidance as distilled features and the features irrelevant to the task and ignored by the Student as residual features. Distilled features focus on key aspects of the input, such as textures and parts of objects. In contrast, residual features demonstrate more diffused attention, often targeting irrelevant areas, including the backgrounds of the target objects. In addition, we proposed two novel metrics: the feature similarity score (FSS) and the relevance score (RS), which quantify the relevance of the distilled knowledge. Experiments on the CIFAR10, ASIRRA, and Plant Disease datasets demonstrate that UniCAM and the two metrics offer valuable insights to explain the KD process.
Limited but consistent gains in adversarial robustness by co-training object recognition models with human EEG
Sep 05, 2024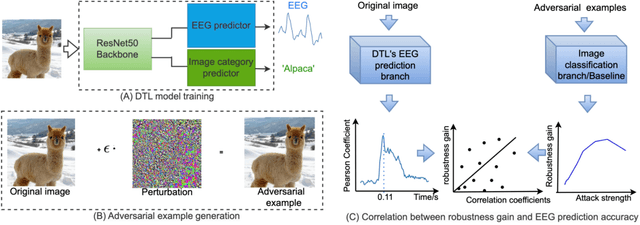
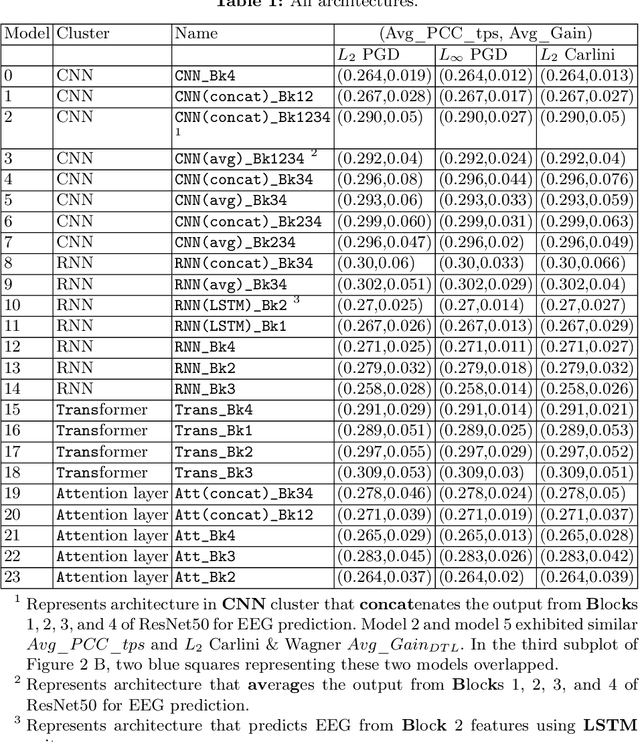
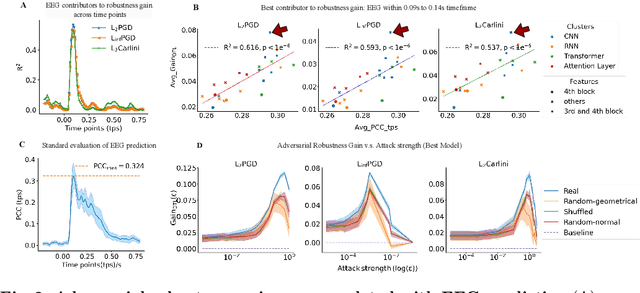
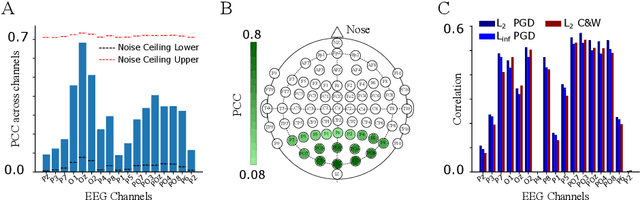
In contrast to human vision, artificial neural networks (ANNs) remain relatively susceptible to adversarial attacks. To address this vulnerability, efforts have been made to transfer inductive bias from human brains to ANNs, often by training the ANN representations to match their biological counterparts. Previous works relied on brain data acquired in rodents or primates using invasive techniques, from specific regions of the brain, under non-natural conditions (anesthetized animals), and with stimulus datasets lacking diversity and naturalness. In this work, we explored whether aligning model representations to human EEG responses to a rich set of real-world images increases robustness to ANNs. Specifically, we trained ResNet50-backbone models on a dual task of classification and EEG prediction; and evaluated their EEG prediction accuracy and robustness to adversarial attacks. We observed significant correlation between the networks' EEG prediction accuracy, often highest around 100 ms post stimulus onset, and their gains in adversarial robustness. Although effect size was limited, effects were consistent across different random initializations and robust for architectural variants. We further teased apart the data from individual EEG channels and observed strongest contribution from electrodes in the parieto-occipital regions. The demonstrated utility of human EEG for such tasks opens up avenues for future efforts that scale to larger datasets under diverse stimuli conditions with the promise of stronger effects.