 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Representational Alignment between Humans and Language Models is implicitly driven by a Concreteness Effect
May 21, 2025The nouns of our language refer to either concrete entities (like a table) or abstract concepts (like justice or love), and cognitive psychology has established that concreteness influences how words are processed. Accordingly, understanding how concreteness is represented in our mind and brain is a central question in psychology, neuroscience, and computational linguistics. While the advent of powerful language models has allowed for quantitative inquiries into the nature of semantic representations, it remains largely underexplored how they represent concreteness. Here, we used behavioral judgments to estimate semantic distances implicitly used by humans, for a set of carefully selected abstract and concrete nouns. Using Representational Similarity Analysis, we find that the implicit representational space of participants and the semantic representations of language models are significantly aligned. We also find that both representational spaces are implicitly aligned to an explicit representation of concreteness, which was obtained from our participants using an additional concreteness rating task. Importantly, using ablation experiments, we demonstrate that the human-to-model alignment is substantially driven by concreteness, but not by other important word characteristics established in psycholinguistics. These results indicate that humans and language models converge on the concreteness dimension, but not on other dimensions.
Limited but consistent gains in adversarial robustness by co-training object recognition models with human EEG
Sep 05, 2024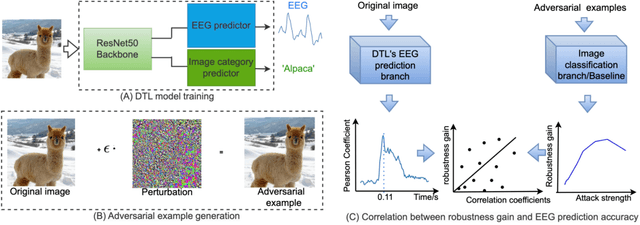
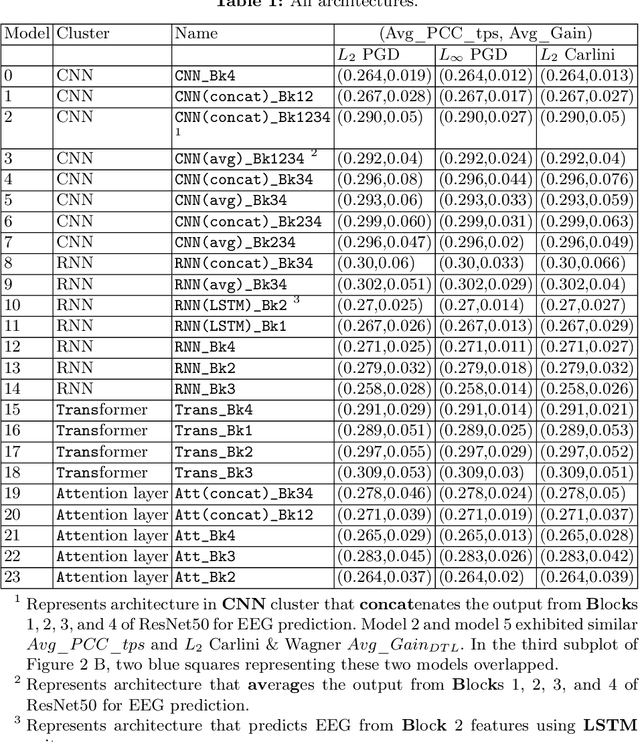
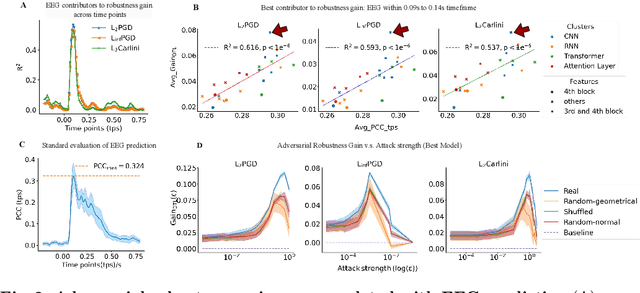
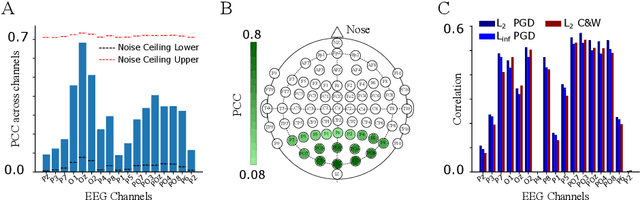
In contrast to human vision, artificial neural networks (ANNs) remain relatively susceptible to adversarial attacks. To address this vulnerability, efforts have been made to transfer inductive bias from human brains to ANNs, often by training the ANN representations to match their biological counterparts. Previous works relied on brain data acquired in rodents or primates using invasive techniques, from specific regions of the brain, under non-natural conditions (anesthetized animals), and with stimulus datasets lacking diversity and naturalness. In this work, we explored whether aligning model representations to human EEG responses to a rich set of real-world images increases robustness to ANNs. Specifically, we trained ResNet50-backbone models on a dual task of classification and EEG prediction; and evaluated their EEG prediction accuracy and robustness to adversarial attacks. We observed significant correlation between the networks' EEG prediction accuracy, often highest around 100 ms post stimulus onset, and their gains in adversarial robustness. Although effect size was limited, effects were consistent across different random initializations and robust for architectural variants. We further teased apart the data from individual EEG channels and observed strongest contribution from electrodes in the parieto-occipital regions. The demonstrated utility of human EEG for such tasks opens up avenues for future efforts that scale to larger datasets under diverse stimuli conditions with the promise of stronger effects.
Reconstruction of Perceived Images from fMRI Patterns and Semantic Brain Exploration using Instance-Conditioned GANs
Feb 25, 2022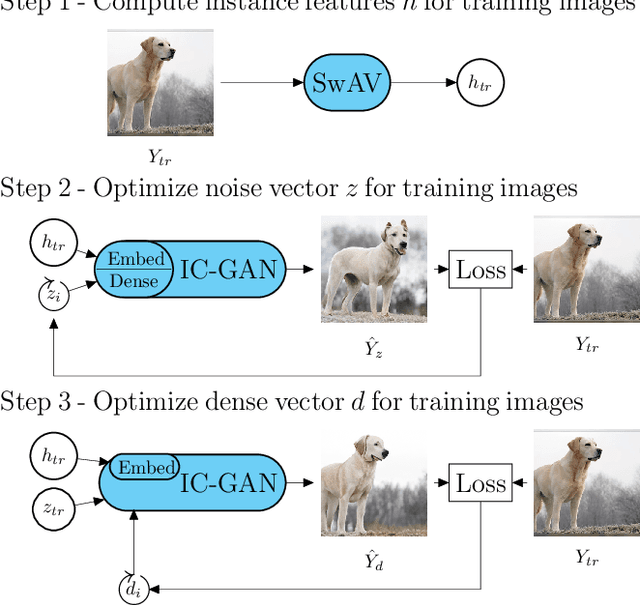
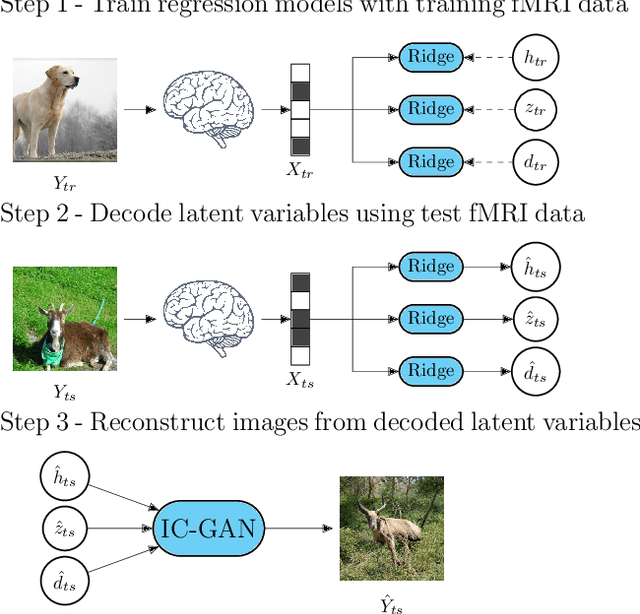
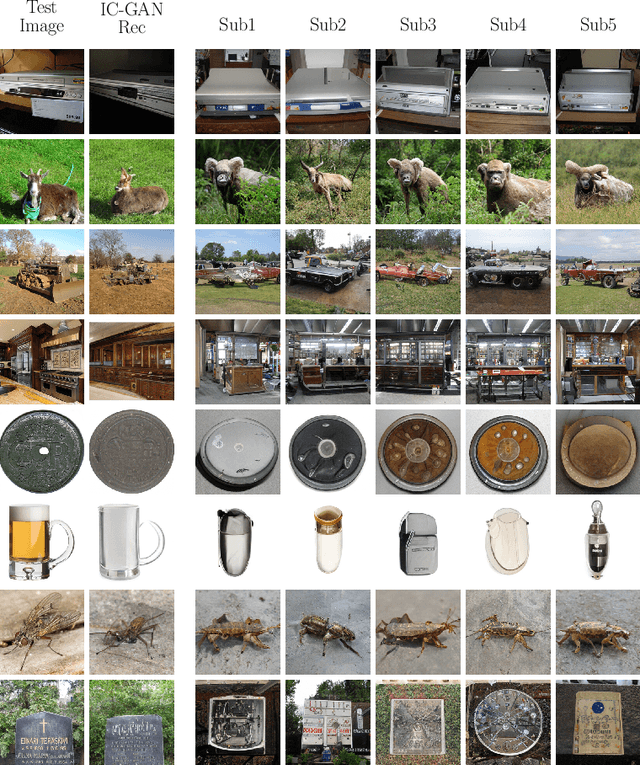

Reconstructing perceived natural images from fMRI signals is one of the most engaging topics of neural decoding research. Prior studies had success in reconstructing either the low-level image features or the semantic/high-level aspects, but rarely both. In this study, we utilized an Instance-Conditioned GAN (IC-GAN) model to reconstruct images from fMRI patterns with both accurate semantic attributes and preserved low-level details. The IC-GAN model takes as input a 119-dim noise vector and a 2048-dim instance feature vector extracted from a target image via a self-supervised learning model (SwAV ResNet-50); these instance features act as a conditioning for IC-GAN image generation, while the noise vector introduces variability between samples. We trained ridge regression models to predict instance features, noise vectors, and dense vectors (the output of the first dense layer of the IC-GAN generator) of stimuli from corresponding fMRI patterns. Then, we used the IC-GAN generator to reconstruct novel test images based on these fMRI-predicted variables. The generated images presented state-of-the-art results in terms of capturing the semantic attributes of the original test images while remaining relatively faithful to low-level image details. Finally, we use the learned regression model and the IC-GAN generator to systematically explore and visualize the semantic features that maximally drive each of several regions-of-interest in the human brain.
On the role of feedback in visual processing: a predictive coding perspective
Jun 08, 2021
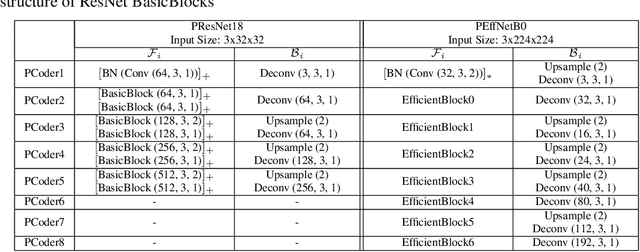


Brain-inspired machine learning is gaining increasing consideration, particularly in computer vision. Several studies investigated the inclusion of top-down feedback connections in convolutional networks; however, it remains unclear how and when these connections are functionally helpful. Here we address this question in the context of object recognition under noisy conditions. We consider deep convolutional networks (CNNs) as models of feed-forward visual processing and implement Predictive Coding (PC) dynamics through feedback connections (predictive feedback) trained for reconstruction or classification of clean images. To directly assess the computational role of predictive feedback in various experimental situations, we optimize and interpret the hyper-parameters controlling the network's recurrent dynamics. That is, we let the optimization process determine whether top-down connections and predictive coding dynamics are functionally beneficial. Across different model depths and architectures (3-layer CNN, ResNet18, and EfficientNetB0) and against various types of noise (CIFAR100-C), we find that the network increasingly relies on top-down predictions as the noise level increases; in deeper networks, this effect is most prominent at lower layers. In addition, the accuracy of the network implementing PC dynamics significantly increases over time-steps, compared to its equivalent forward network. All in all, our results provide novel insights relevant to Neuroscience by confirming the computational role of feedback connections in sensory systems, and to Machine Learning by revealing how these can improve the robustness of current vision models.
Predify: Augmenting deep neural networks with brain-inspired predictive coding dynamics
Jun 04, 2021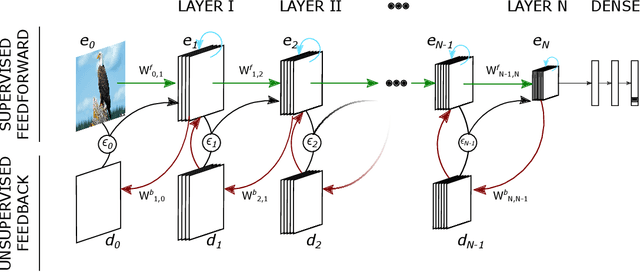

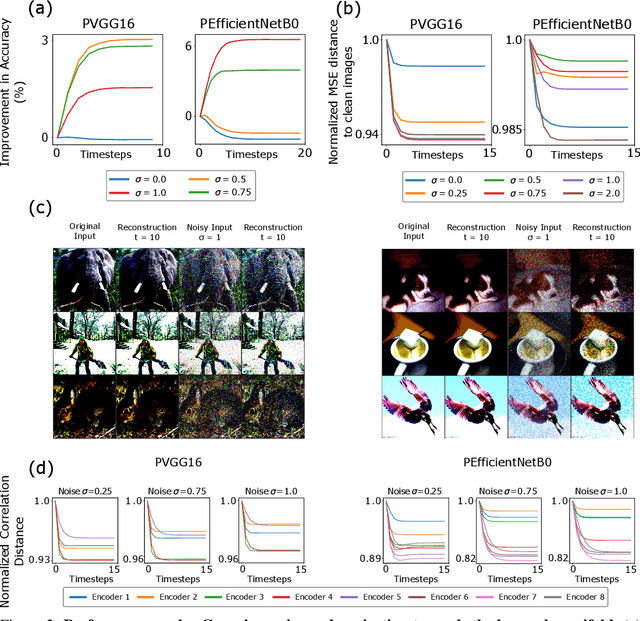
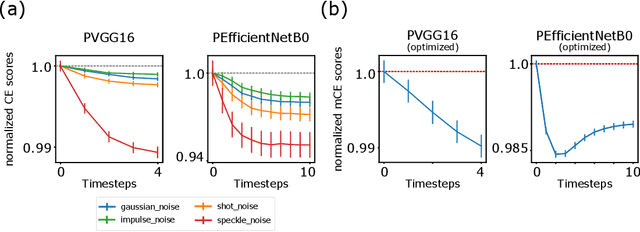
Deep neural networks excel at image classification, but their performance is far less robust to input perturbations than human perception. In this work we explore whether this shortcoming may be partly addressed by incorporating brain-inspired recurrent dynamics in deep convolutional networks. We take inspiration from a popular framework in neuroscience: 'predictive coding'. At each layer of the hierarchical model, generative feedback 'predicts' (i.e., reconstructs) the pattern of activity in the previous layer. The reconstruction errors are used to iteratively update the network's representations across timesteps, and to optimize the network's feedback weights over the natural image dataset-a form of unsupervised training. We show that implementing this strategy into two popular networks, VGG16 and EfficientNetB0, improves their robustness against various corruptions. We hypothesize that other feedforward networks could similarly benefit from the proposed framework. To promote research in this direction, we provide an open-sourced PyTorch-based package called Predify, which can be used to implement and investigate the impacts of the predictive coding dynamics in any convolutional neural network.
Does language help generalization in vision models?
May 15, 2021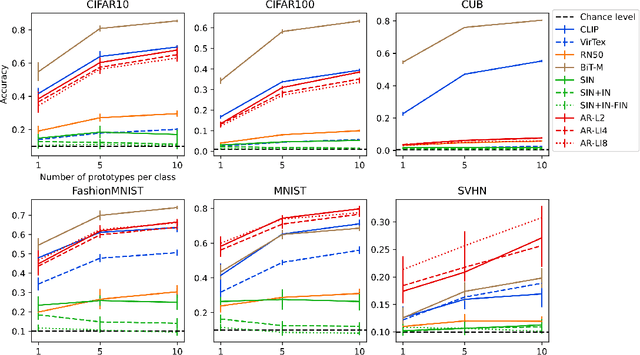
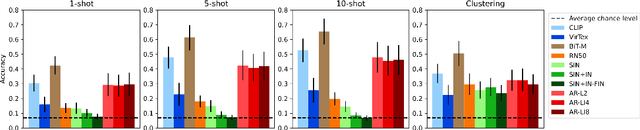
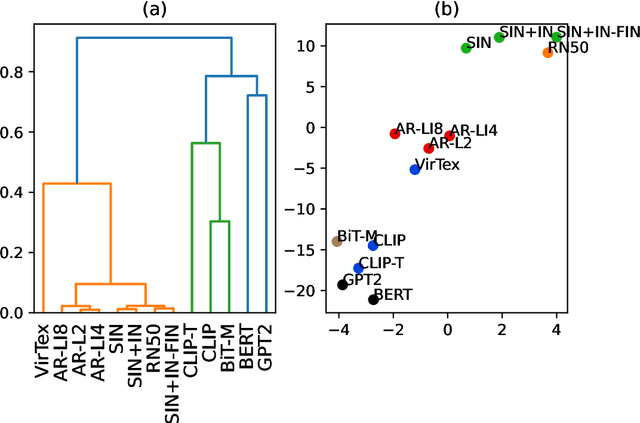
Vision models trained on multimodal datasets can benefit from the wide availability of large image-caption datasets. A recent model (CLIP) was found to generalize well in zero-shot and transfer learning settings. This could imply that linguistic or "semantic grounding" confers additional generalization abilities to the visual feature space. Here, we systematically evaluate various multimodal architectures and vision-only models in terms of unsupervised clustering, few-shot learning, transfer learning and adversarial robustness. In each setting, multimodal training produced no additional generalization capability compared to standard supervised visual training. We conclude that work is still required for semantic grounding to help improve vision models.
Predictive coding feedback results in perceived illusory contours in a recurrent neural network
Feb 03, 2021

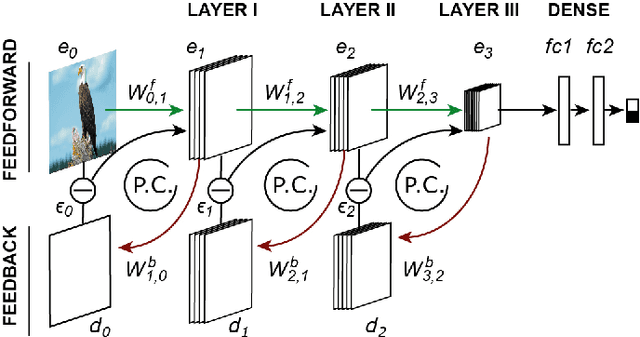
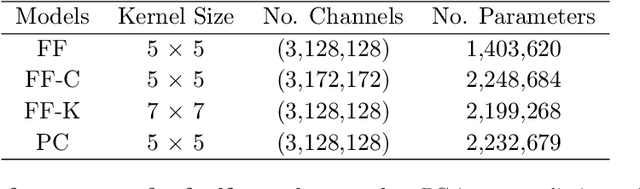
Modern feedforward convolutional neural networks (CNNs) can now solve some computer vision tasks at super-human levels. However, these networks only roughly mimic human visual perception. One difference from human vision is that they do not appear to perceive illusory contours (e.g. Kanizsa squares) in the same way humans do. Physiological evidence from visual cortex suggests that the perception of illusory contours could involve feedback connections. Would recurrent feedback neural networks perceive illusory contours like humans? In this work we equip a deep feedforward convolutional network with brain-inspired recurrent dynamics. The network was first pretrained with an unsupervised reconstruction objective on a natural image dataset, to expose it to natural object contour statistics. Then, a classification decision layer was added and the model was finetuned on a form discrimination task: squares vs. randomly oriented inducer shapes (no illusory contour). Finally, the model was tested with the unfamiliar "illusory contour" configuration: inducer shapes oriented to form an illusory square. Compared with feedforward baselines, the iterative "predictive coding" feedback resulted in more illusory contours being classified as physical squares. The perception of the illusory contour was measurable in the luminance profile of the image reconstructions produced by the model, demonstrating that the model really "sees" the illusion. Ablation studies revealed that natural image pretraining and feedback error correction are both critical to the perception of the illusion. Finally we validated our conclusions in a deeper network (VGG): adding the same predictive coding feedback dynamics again leads to the perception of illusory contours.