 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-inspired Computational Modeling of Action Recognition with Recurrent Spiking Neural Networks Equipped with Reinforcement Delay Learning
Jun 17, 2024



The growing interest in brain-inspired computational models arises from the remarkable problem-solving efficiency of the human brain. Action recognition, a complex task in computational neuroscience, has received significant attention due to both its intricate nature and the brain's exceptional performance in this area. Nevertheless, current solutions for action recognition either exhibit limitations in effectively addressing the problem or lack the necessary biological plausibility. Deep neural networks, for instance, demonstrate acceptable performance but deviate from biological evidence, thereby restricting their suitability for brain-inspired computational studies. On the other hand, the majority of brain-inspired models proposed for action recognition exhibit significantly lower effectiveness compared to deep models and fail to achieve human-level performance. This deficiency can be attributed to their disregard for the underlying mechanisms of the brain. In this article, we present an effective brain-inspired computational model for action recognition. We equip our model with novel biologically plausible mechanisms for spiking neural networks that are crucial for learning spatio-temporal patterns. The key idea behind these new mechanisms is to bridge the gap between the brain's capabilities and action recognition tasks by integrating key biological principles into our computational framework. Furthermore, we evaluate the performance of our model against other models using a benchmark dataset for action recognition, DVS-128 Gesture. The results show that our model outperforms previous biologically plausible models and competes with deep supervised models.
Modality-Agnostic fMRI Decoding of Vision and Language
Mar 18, 2024



Previous studies have shown that it is possible to map brain activation data of subjects viewing images onto the feature representation space of not only vision models (modality-specific decoding) but also language models (cross-modal decoding). In this work, we introduce and use a new large-scale fMRI dataset (~8,500 trials per subject) of people watching both images and text descriptions of such images. This novel dataset enables the development of modality-agnostic decoders: a single decoder that can predict which stimulus a subject is seeing, irrespective of the modality (image or text) in which the stimulus is presented. We train and evaluate such decoders to map brain signals onto stimulus representations from a large range of publicly available vision, language and multimodal (vision+language) models. Our findings reveal that (1) modality-agnostic decoders perform as well as (and sometimes even better than) modality-specific decoders (2) modality-agnostic decoders mapping brain data onto representations from unimodal models perform as well as decoders relying on multimodal representations (3) while language and low-level visual (occipital) brain regions are best at decoding text and image stimuli, respectively, high-level visual (temporal) regions perform well on both stimulus types.
Reconstruction of Perceived Images from fMRI Patterns and Semantic Brain Exploration using Instance-Conditioned GANs
Feb 25, 2022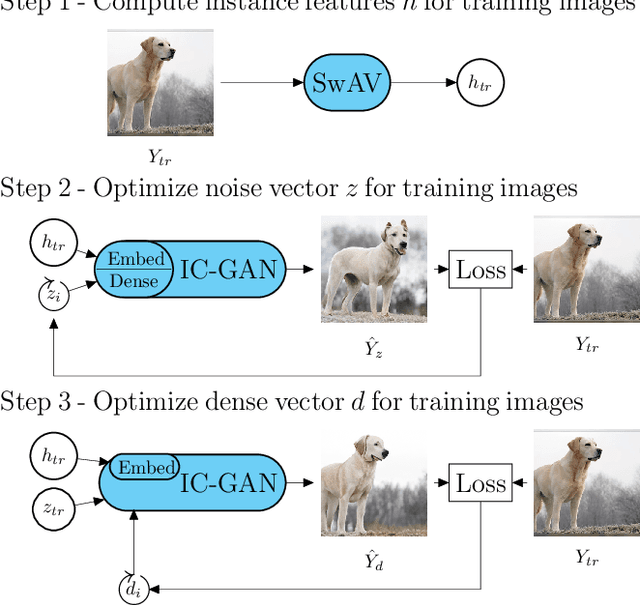
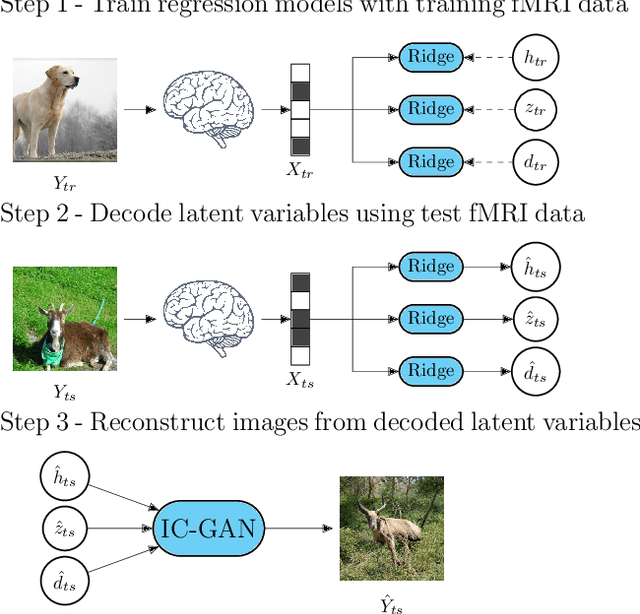
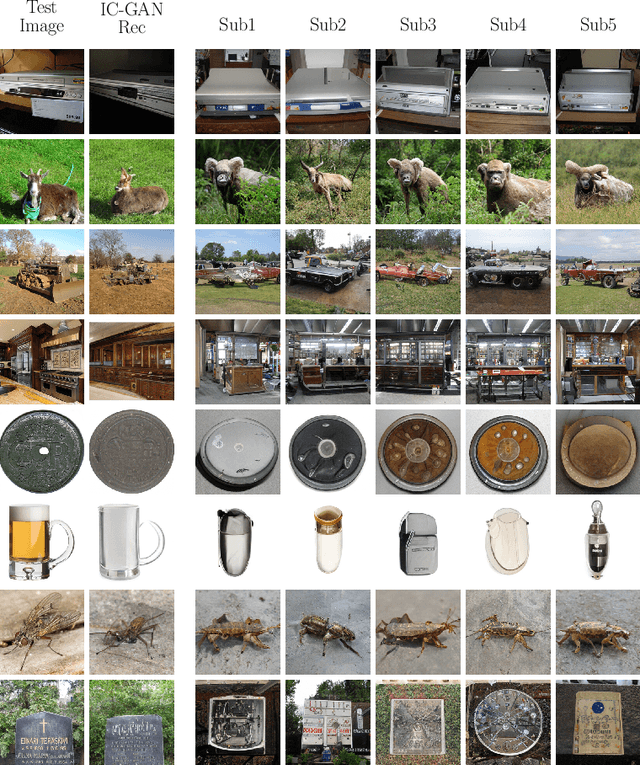

Reconstructing perceived natural images from fMRI signals is one of the most engaging topics of neural decoding research. Prior studies had success in reconstructing either the low-level image features or the semantic/high-level aspects, but rarely both. In this study, we utilized an Instance-Conditioned GAN (IC-GAN) model to reconstruct images from fMRI patterns with both accurate semantic attributes and preserved low-level details. The IC-GAN model takes as input a 119-dim noise vector and a 2048-dim instance feature vector extracted from a target image via a self-supervised learning model (SwAV ResNet-50); these instance features act as a conditioning for IC-GAN image generation, while the noise vector introduces variability between samples. We trained ridge regression models to predict instance features, noise vectors, and dense vectors (the output of the first dense layer of the IC-GAN generator) of stimuli from corresponding fMRI patterns. Then, we used the IC-GAN generator to reconstruct novel test images based on these fMRI-predicted variables. The generated images presented state-of-the-art results in terms of capturing the semantic attributes of the original test images while remaining relatively faithful to low-level image details. Finally, we use the learned regression model and the IC-GAN generator to systematically explore and visualize the semantic features that maximally drive each of several regions-of-interest in the human brain.
On the role of feedback in visual processing: a predictive coding perspective
Jun 08, 2021
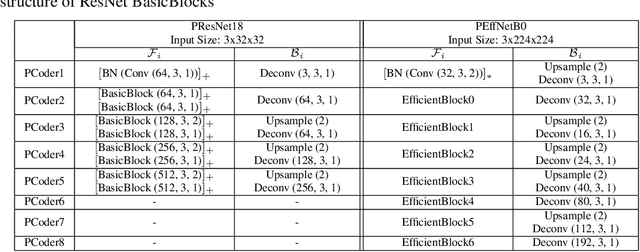


Brain-inspired machine learning is gaining increasing consideration, particularly in computer vision. Several studies investigated the inclusion of top-down feedback connections in convolutional networks; however, it remains unclear how and when these connections are functionally helpful. Here we address this question in the context of object recognition under noisy conditions. We consider deep convolutional networks (CNNs) as models of feed-forward visual processing and implement Predictive Coding (PC) dynamics through feedback connections (predictive feedback) trained for reconstruction or classification of clean images. To directly assess the computational role of predictive feedback in various experimental situations, we optimize and interpret the hyper-parameters controlling the network's recurrent dynamics. That is, we let the optimization process determine whether top-down connections and predictive coding dynamics are functionally beneficial. Across different model depths and architectures (3-layer CNN, ResNet18, and EfficientNetB0) and against various types of noise (CIFAR100-C), we find that the network increasingly relies on top-down predictions as the noise level increases; in deeper networks, this effect is most prominent at lower layers. In addition, the accuracy of the network implementing PC dynamics significantly increases over time-steps, compared to its equivalent forward network. All in all, our results provide novel insights relevant to Neuroscience by confirming the computational role of feedback connections in sensory systems, and to Machine Learning by revealing how these can improve the robustness of current vision models.
Predify: Augmenting deep neural networks with brain-inspired predictive coding dynamics
Jun 04, 2021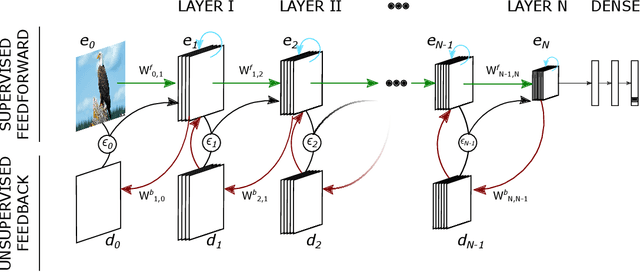

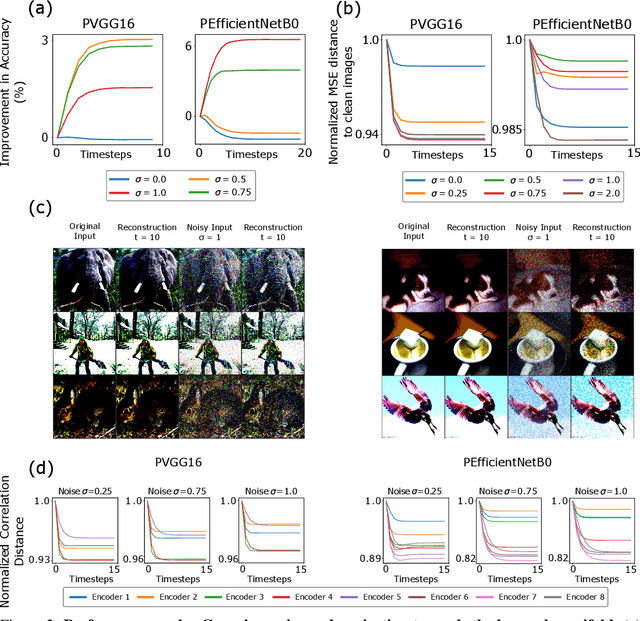
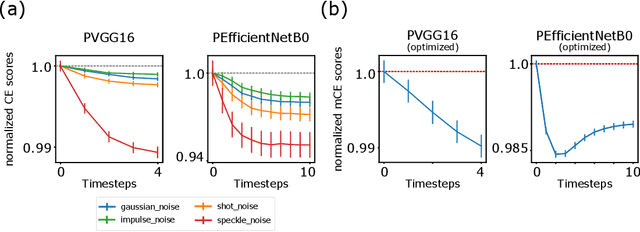
Deep neural networks excel at image classification, but their performance is far less robust to input perturbations than human perception. In this work we explore whether this shortcoming may be partly addressed by incorporating brain-inspired recurrent dynamics in deep convolutional networks. We take inspiration from a popular framework in neuroscience: 'predictive coding'. At each layer of the hierarchical model, generative feedback 'predicts' (i.e., reconstructs) the pattern of activity in the previous layer. The reconstruction errors are used to iteratively update the network's representations across timesteps, and to optimize the network's feedback weights over the natural image dataset-a form of unsupervised training. We show that implementing this strategy into two popular networks, VGG16 and EfficientNetB0, improves their robustness against various corruptions. We hypothesize that other feedforward networks could similarly benefit from the proposed framework. To promote research in this direction, we provide an open-sourced PyTorch-based package called Predify, which can be used to implement and investigate the impacts of the predictive coding dynamics in any convolutional neural network.
Reconstructing Natural Scenes from fMRI Patterns using BigBiGAN
Jan 31, 2020



Decoding and reconstructing images from brain imaging data is a research area of high interest. Recent progress in deep generative neural networks has introduced new opportunities to tackle this problem. Here, we employ a recently proposed large-scale bi-directional generative adversarial network, called BigBiGAN, to decode and reconstruct natural scenes from fMRI patterns. BigBiGAN converts images into a 120-dimensional latent space which encodes class and attribute information together, and can also reconstruct images based on their latent vectors. We trained a linear mapping between fMRI data, acquired over images from 150 different categories of ImageNet, and their corresponding BigBiGAN latent vectors. Then, we applied this mapping to the fMRI activity patterns obtained from 50 new test images from 50 unseen categories in order to retrieve their latent vectors, and reconstruct the corresponding images. Pairwise image decoding from the predicted latent vectors was highly accurate (84%). Moreover, qualitative and quantitative assessments revealed that the resulting image reconstructions were visually plausible, successfully captured many attributes of the original images, and had high perceptual similarity with the original content. This method establishes a new state-of-the-art for fMRI-based natural image reconstruction, and can be flexibly updated to take into account any future improvements in generative models of natural scene images.
SpykeTorch: Efficient Simulation of Convolutional Spiking Neural Networks with at most one Spike per Neuron
Mar 06, 2019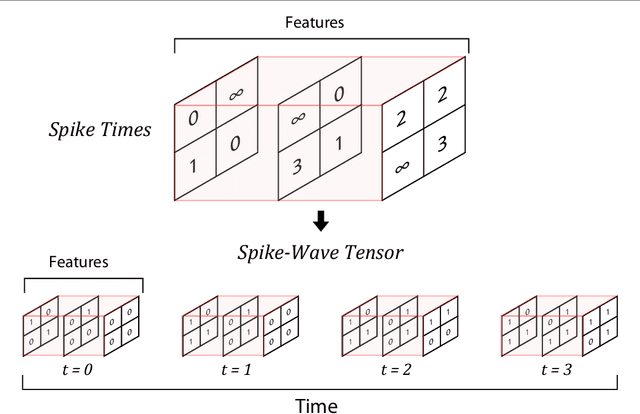

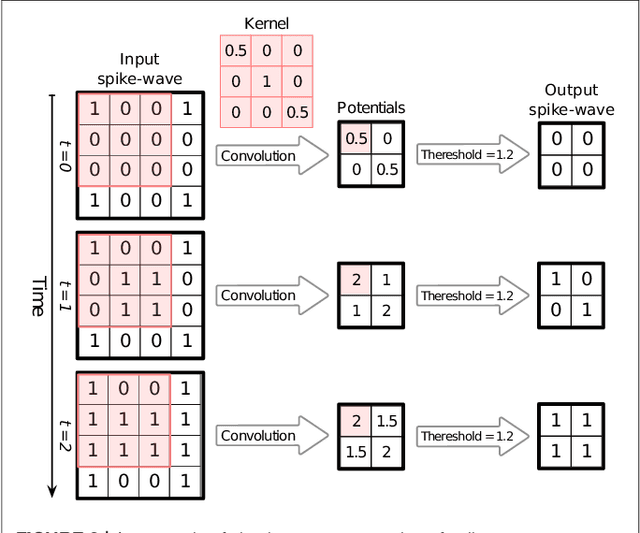
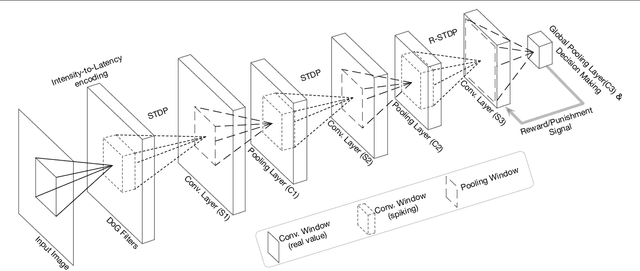
Application of deep convolutional spiking neural networks (SNNs) to artificial intelligence (AI) tasks has recently gained a lot of interest since SNNs are hardware-friendly and energy-efficient. Unlike the non-spiking counterparts, most of the existing SNN simulation frameworks are not practically efficient enough for large-scale AI tasks. In this paper, we introduce SpykeTorch, an open-source high-speed simulation framework based on PyTorch. This framework simulates convolutional SNNs with at most one spike per neuron and the rank-order encoding scheme. In terms of learning rules, both spike-timing-dependent plasticity (STDP) and reward-modulated STDP (R-STDP) are implemented, but other rules could be implemented easily. Apart from the aforementioned properties, SpykeTorch is highly generic and capable of reproducing the results of various studies. Computations in the proposed framework are tensor-based and totally done by PyTorch functions, which in turn brings the ability of just-in-time optimization for running on CPUs, GPUs, or Multi-GPU platforms.
First-spike based visual categorization using reward-modulated STDP
Jul 10, 2018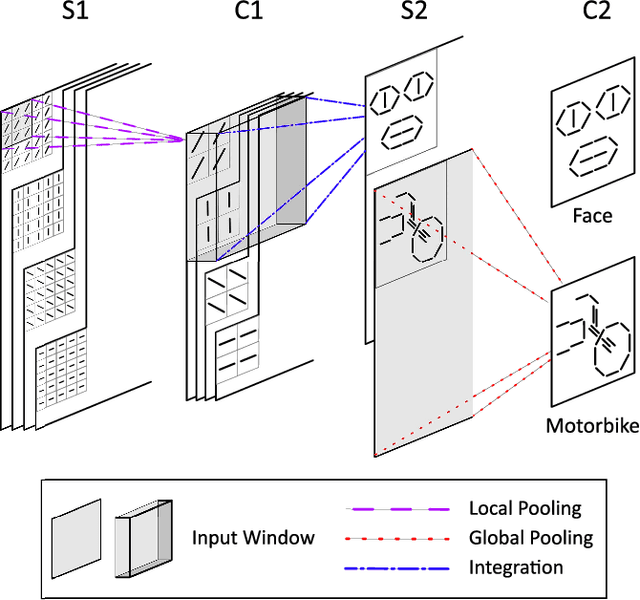
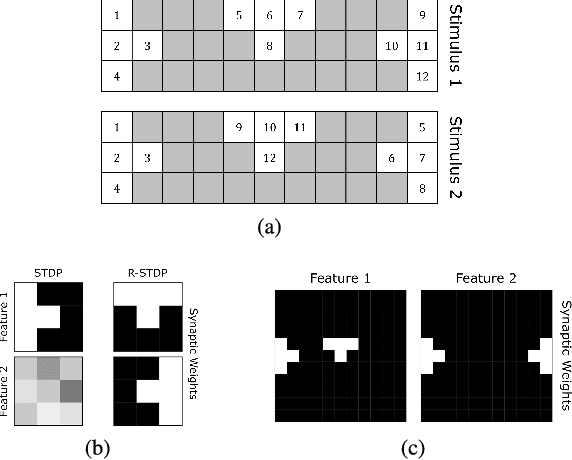
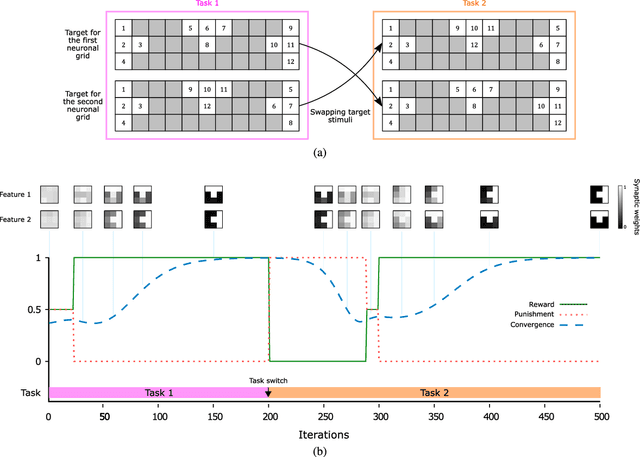
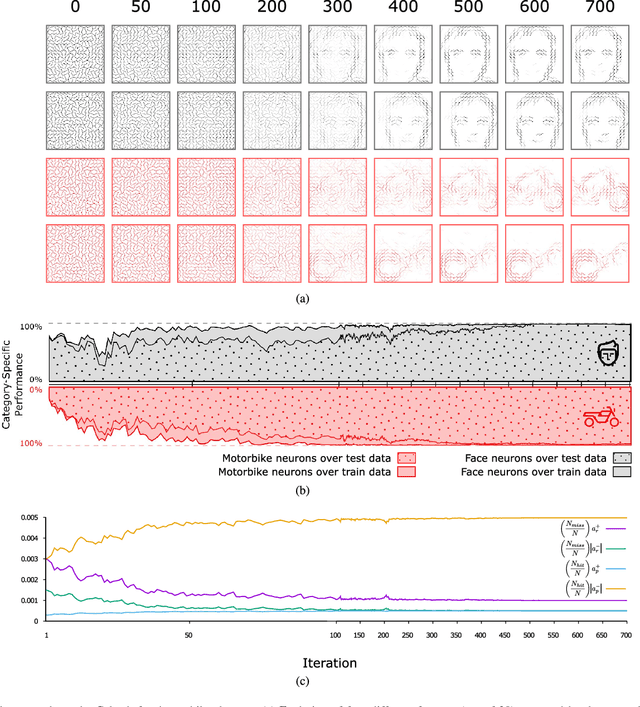
Reinforcement learning (RL) has recently regained popularity, with major achievements such as beating the European game of Go champion. Here, for the first time, we show that RL can be used efficiently to train a spiking neural network (SNN) to perform object recognition in natural images without using an external classifier. We used a feedforward convolutional SNN and a temporal coding scheme where the most strongly activated neurons fire first, while less activated ones fire later, or not at all. In the highest layers, each neuron was assigned to an object category, and it was assumed that the stimulus category was the category of the first neuron to fire. If this assumption was correct, the neuron was rewarded, i.e. spike-timing-dependent plasticity (STDP) was applied, which reinforced the neuron's selectivity. Otherwise, anti-STDP was applied, which encouraged the neuron to learn something else. As demonstrated on various image datasets (Caltech, ETH-80, and NORB), this reward modulated STDP (R-STDP) approach extracted particularly discriminative visual features, whereas classic unsupervised STDP extracts any feature that consistently repeats. As a result, R-STDP outperformed STDP on these datasets. Furthermore, R-STDP is suitable for online learning, and can adapt to drastic changes such as label permutations. Finally, it is worth mentioning that both feature extraction and classification were done with spikes, using at most one spike per neuron. Thus the network is hardware friendly and energy efficient.
* supplementary materials are added, Caltech face/motorbike demonstration figure is updated, some parts of the main manuscript are moved to the supplementary materials, additional network analysis and performance comparison with deep nets are added
Combining STDP and Reward-Modulated STDP in Deep Convolutional Spiking Neural Networks for Digit Recognition
Mar 31, 2018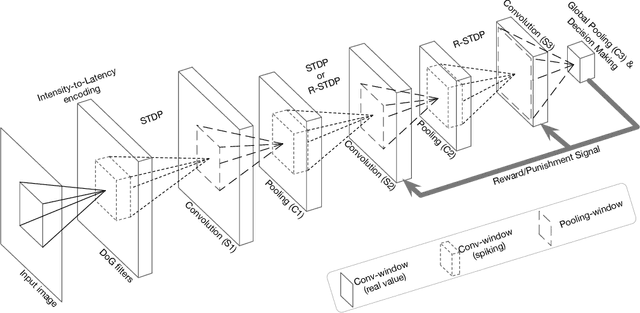

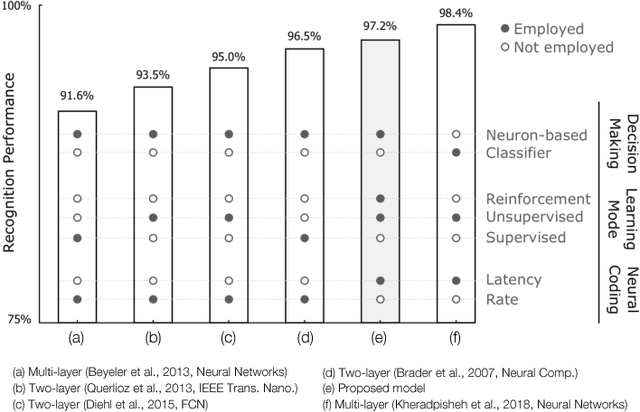
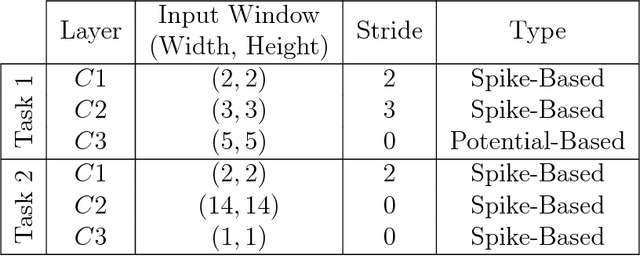
The primate visual system has inspired the development of deep artificial neural networks, which have revolutionized the computer vision domain. Yet these networks are much less energy-efficient than their biological counterparts, and they are typically trained with backpropagation, which is extremely data-hungry. To address these limitations, we used a deep convolutional spiking neural network (DCSNN) and a latency-coding scheme. We trained it using a combination of spike-timing-dependent plasticity (STDP) for the lowest layers and reward-modulated STDP (R-STDP) for the highest ones. In short, with R-STDP a correct (resp. incorrect) decision leads to STDP (resp. anti-STDP). This approach led to an accuracy of 97.2% on MNIST, without requiring an external classifier. In addition, we demonstrated that R-STDP extracts features that are diagnostic for the task at hand, and discards the other ones, whereas STDP extracts any feature that repeats. Finally, our approach is biologically plausible, hardware friendly, and energy-efficient.