 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-inspired Computational Modeling of Action Recognition with Recurrent Spiking Neural Networks Equipped with Reinforcement Delay Learning
Jun 17, 2024



The growing interest in brain-inspired computational models arises from the remarkable problem-solving efficiency of the human brain. Action recognition, a complex task in computational neuroscience, has received significant attention due to both its intricate nature and the brain's exceptional performance in this area. Nevertheless, current solutions for action recognition either exhibit limitations in effectively addressing the problem or lack the necessary biological plausibility. Deep neural networks, for instance, demonstrate acceptable performance but deviate from biological evidence, thereby restricting their suitability for brain-inspired computational studies. On the other hand, the majority of brain-inspired models proposed for action recognition exhibit significantly lower effectiveness compared to deep models and fail to achieve human-level performance. This deficiency can be attributed to their disregard for the underlying mechanisms of the brain. In this article, we present an effective brain-inspired computational model for action recognition. We equip our model with novel biologically plausible mechanisms for spiking neural networks that are crucial for learning spatio-temporal patterns. The key idea behind these new mechanisms is to bridge the gap between the brain's capabilities and action recognition tasks by integrating key biological principles into our computational framework. Furthermore, we evaluate the performance of our model against other models using a benchmark dataset for action recognition, DVS-128 Gesture. The results show that our model outperforms previous biologically plausible models and competes with deep supervised models.
Meta-Learning in Spiking Neural Networks with Reward-Modulated STDP
Jun 07, 2023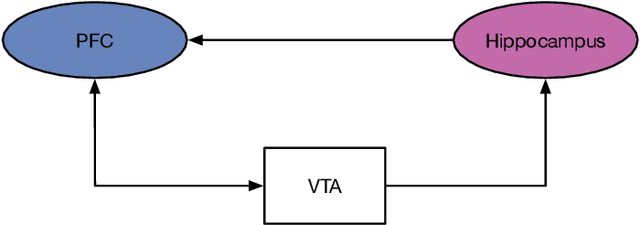
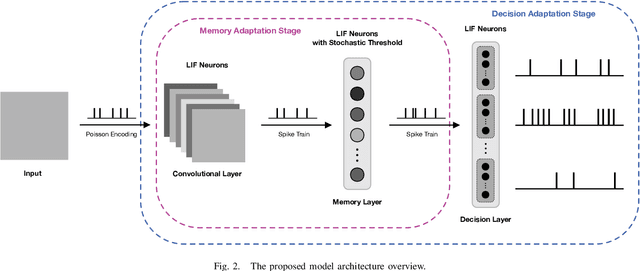


The human brain constantly learns and rapidly adapts to new situations by integrating acquired knowledge and experiences into memory. Developing this capability in machine learning models is considered an important goal of AI research since deep neural networks perform poorly when there is limited data or when they need to adapt quickly to new unseen tasks. Meta-learning models are proposed to facilitate quick learning in low-data regimes by employing absorbed information from the past. Although some models have recently been introduced that reached high-performance levels, they are not biologically plausible. We have proposed a bio-plausible meta-learning model inspired by the hippocampus and the prefrontal cortex using spiking neural networks with a reward-based learning system. Our proposed model includes a memory designed to prevent catastrophic forgetting, a phenomenon that occurs when meta-learning models forget what they have learned as soon as the new task begins. Also, our new model can easily be applied to spike-based neuromorphic devices and enables fast learning in neuromorphic hardware. The final analysis will discuss the implications and predictions of the model for solving few-shot classification tasks. In solving these tasks, our model has demonstrated the ability to compete with the existing state-of-the-art meta-learning techniques.
Enhancing efficiency of object recognition in different categorization levels by reinforcement learning in modular spiking neural networks
Feb 10, 2021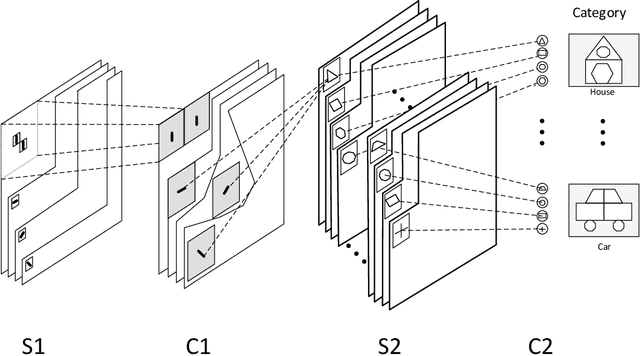
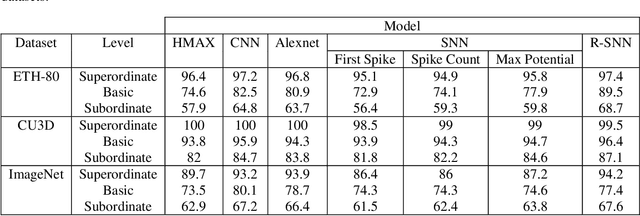
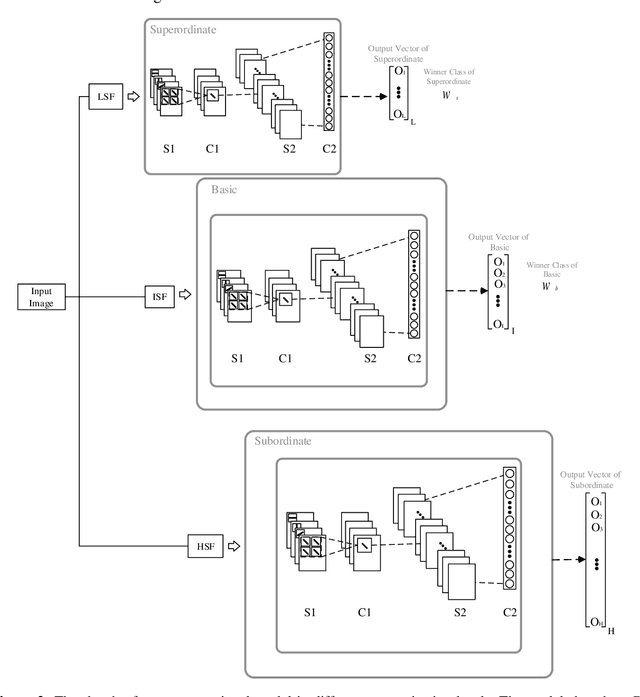
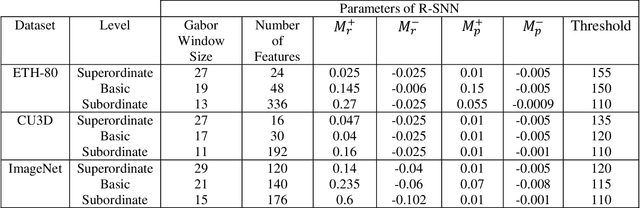
The human visual system contains a hierarchical sequence of modules that take part in visual perception at superordinate, basic, and subordinate categorization levels. During the last decades, various computational models have been proposed to mimic the hierarchical feed-forward processing of visual cortex, but many critical characteristics of the visual system, such actual neural processing and learning mechanisms, are ignored. Pursuing the line of biological inspiration, we propose a computational model for object recognition in different categorization levels, in which a spiking neural network equipped with the reinforcement learning rule is used as a module at each categorization level. Each module solves the object recognition problem at each categorization level, solely based on the earliest spike of class-specific neurons at its last layer, without using any external classifier. According to the required information at each categorization level, the relevant band-pass filtered images are utilized. The performance of our proposed model is evaluated by various appraisal criteria with three benchmark datasets and significant improvement in recognition accuracy of our proposed model is achieved in all experiments.
Bio-plausible Unsupervised Delay Learning for Extracting Temporal Features in Spiking Neural Networks
Nov 18, 2020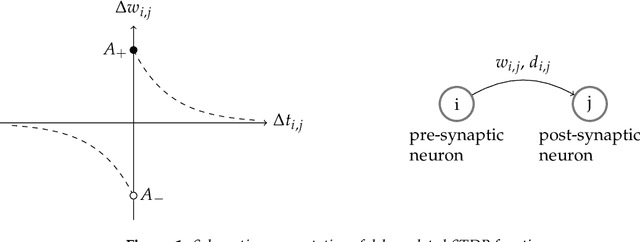
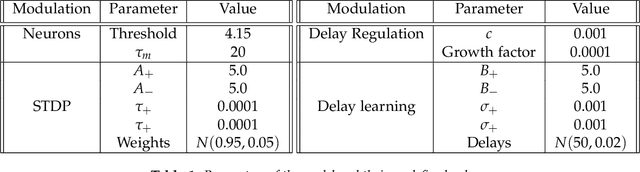
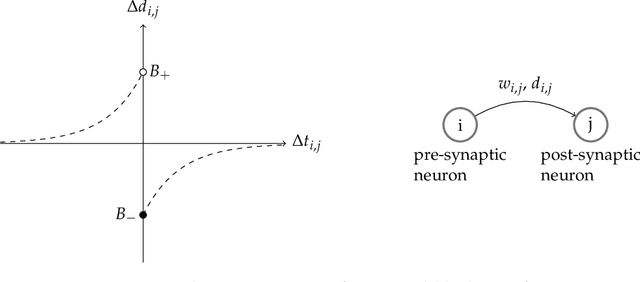
The plasticity of the conduction delay between neurons plays a fundamental role in learning. However, the exact underlying mechanisms in the brain for this modulation is still an open problem. Understanding the precise adjustment of synaptic delays could help us in developing effective brain-inspired computational models in providing aligned insights with the experimental evidence. In this paper, we propose an unsupervised biologically plausible learning rule for adjusting the synaptic delays in spiking neural networks. Then, we provided some mathematical proofs to show that our learning rule gives a neuron the ability to learn repeating spatio-temporal patterns. Furthermore, the experimental results of applying an STDP-based spiking neural network equipped with our proposed delay learning rule on Random Dot Kinematogram indicate the efficacy of the proposed delay learning rule in extracting temporal features.
SpykeTorch: Efficient Simulation of Convolutional Spiking Neural Networks with at most one Spike per Neuron
Mar 06, 2019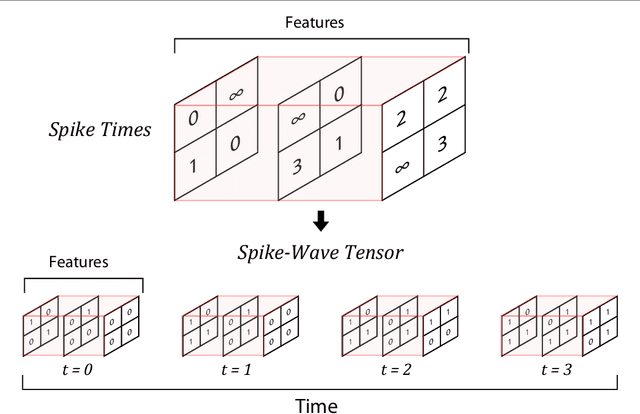

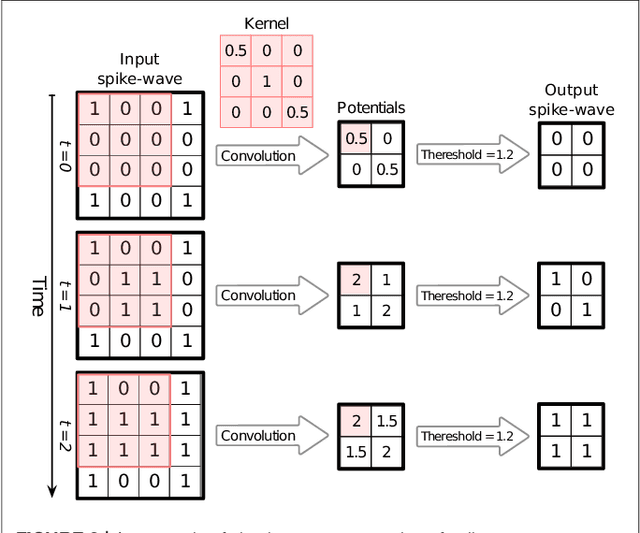
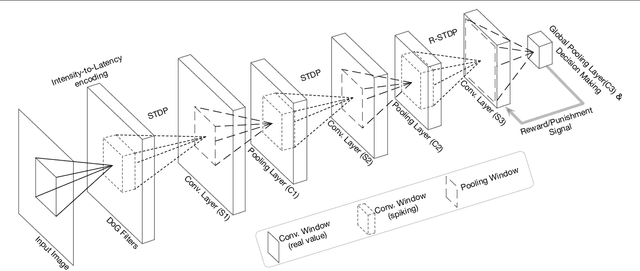
Application of deep convolutional spiking neural networks (SNNs) to artificial intelligence (AI) tasks has recently gained a lot of interest since SNNs are hardware-friendly and energy-efficient. Unlike the non-spiking counterparts, most of the existing SNN simulation frameworks are not practically efficient enough for large-scale AI tasks. In this paper, we introduce SpykeTorch, an open-source high-speed simulation framework based on PyTorch. This framework simulates convolutional SNNs with at most one spike per neuron and the rank-order encoding scheme. In terms of learning rules, both spike-timing-dependent plasticity (STDP) and reward-modulated STDP (R-STDP) are implemented, but other rules could be implemented easily. Apart from the aforementioned properties, SpykeTorch is highly generic and capable of reproducing the results of various studies. Computations in the proposed framework are tensor-based and totally done by PyTorch functions, which in turn brings the ability of just-in-time optimization for running on CPUs, GPUs, or Multi-GPU platforms.
First-spike based visual categorization using reward-modulated STDP
Jul 10, 2018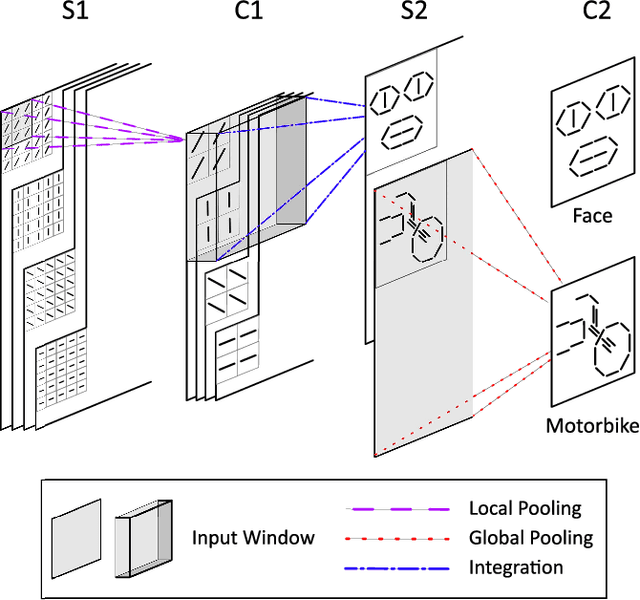
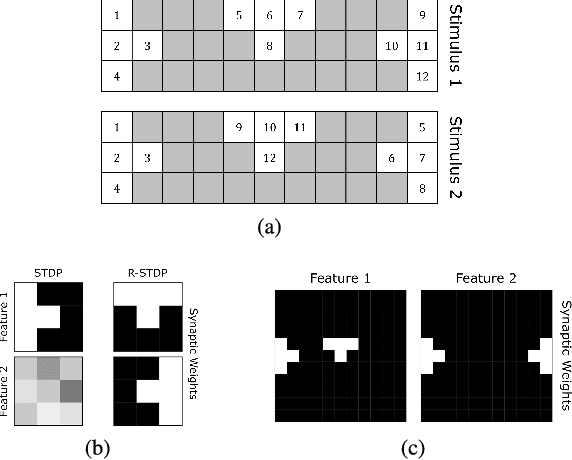
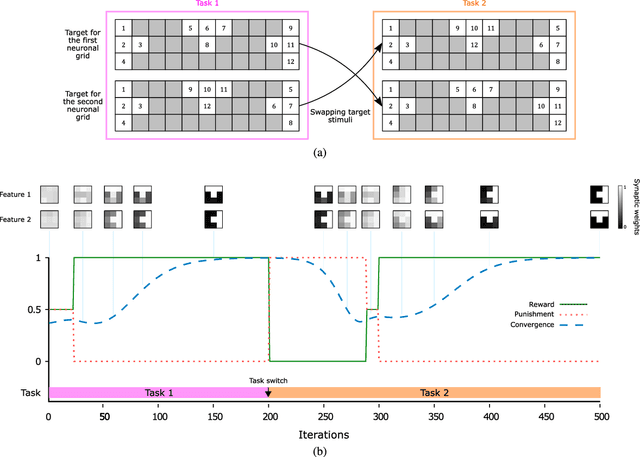
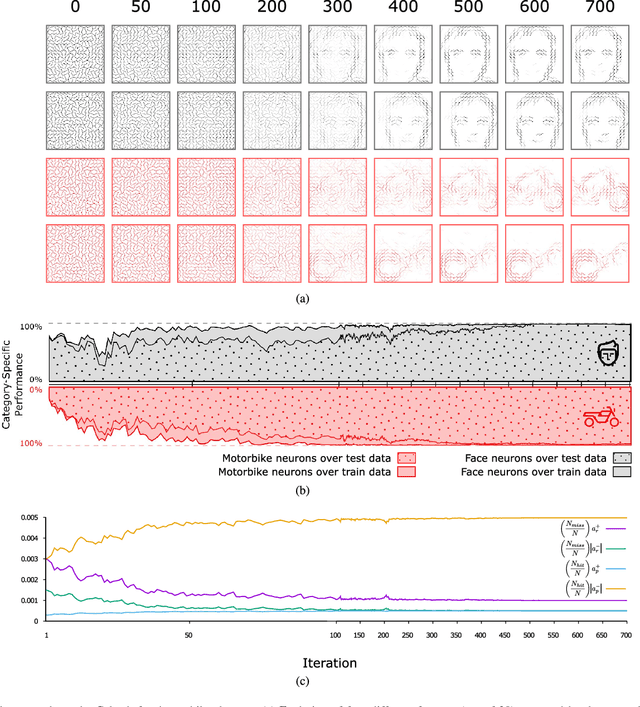
Reinforcement learning (RL) has recently regained popularity, with major achievements such as beating the European game of Go champion. Here, for the first time, we show that RL can be used efficiently to train a spiking neural network (SNN) to perform object recognition in natural images without using an external classifier. We used a feedforward convolutional SNN and a temporal coding scheme where the most strongly activated neurons fire first, while less activated ones fire later, or not at all. In the highest layers, each neuron was assigned to an object category, and it was assumed that the stimulus category was the category of the first neuron to fire. If this assumption was correct, the neuron was rewarded, i.e. spike-timing-dependent plasticity (STDP) was applied, which reinforced the neuron's selectivity. Otherwise, anti-STDP was applied, which encouraged the neuron to learn something else. As demonstrated on various image datasets (Caltech, ETH-80, and NORB), this reward modulated STDP (R-STDP) approach extracted particularly discriminative visual features, whereas classic unsupervised STDP extracts any feature that consistently repeats. As a result, R-STDP outperformed STDP on these datasets. Furthermore, R-STDP is suitable for online learning, and can adapt to drastic changes such as label permutations. Finally, it is worth mentioning that both feature extraction and classification were done with spikes, using at most one spike per neuron. Thus the network is hardware friendly and energy efficient.
* supplementary materials are added, Caltech face/motorbike demonstration figure is updated, some parts of the main manuscript are moved to the supplementary materials, additional network analysis and performance comparison with deep nets are added
Combining STDP and Reward-Modulated STDP in Deep Convolutional Spiking Neural Networks for Digit Recognition
Mar 31, 2018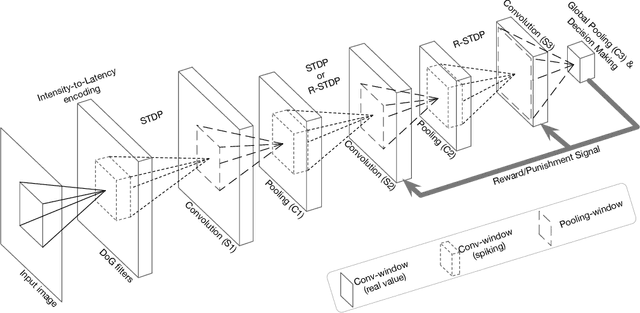

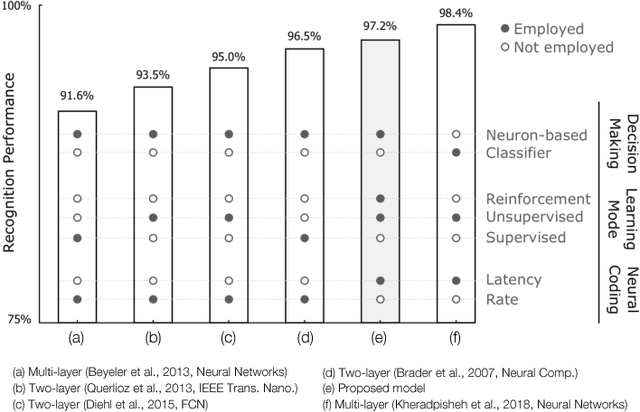
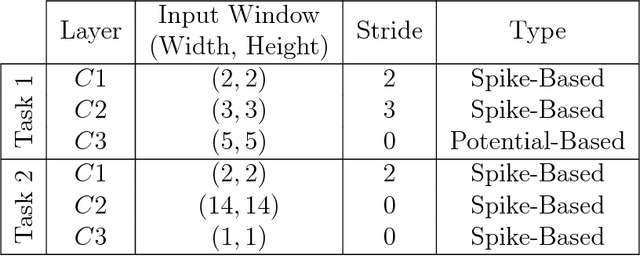
The primate visual system has inspired the development of deep artificial neural networks, which have revolutionized the computer vision domain. Yet these networks are much less energy-efficient than their biological counterparts, and they are typically trained with backpropagation, which is extremely data-hungry. To address these limitations, we used a deep convolutional spiking neural network (DCSNN) and a latency-coding scheme. We trained it using a combination of spike-timing-dependent plasticity (STDP) for the lowest layers and reward-modulated STDP (R-STDP) for the highest ones. In short, with R-STDP a correct (resp. incorrect) decision leads to STDP (resp. anti-STDP). This approach led to an accuracy of 97.2% on MNIST, without requiring an external classifier. In addition, we demonstrated that R-STDP extracts features that are diagnostic for the task at hand, and discards the other ones, whereas STDP extracts any feature that repeats. Finally, our approach is biologically plausible, hardware friendly, and energy-efficient.
STDP-based spiking deep convolutional neural networks for object recognition
Dec 25, 2017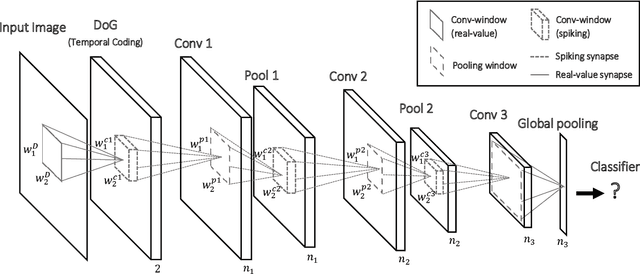


Previous studies have shown that spike-timing-dependent plasticity (STDP) can be used in spiking neural networks (SNN) to extract visual features of low or intermediate complexity in an unsupervised manner. These studies, however, used relatively shallow architectures, and only one layer was trainable. Another line of research has demonstrated - using rate-based neural networks trained with back-propagation - that having many layers increases the recognition robustness, an approach known as deep learning. We thus designed a deep SNN, comprising several convolutional (trainable with STDP) and pooling layers. We used a temporal coding scheme where the most strongly activated neurons fire first, and less activated neurons fire later or not at all. The network was exposed to natural images. Thanks to STDP, neurons progressively learned features corresponding to prototypical patterns that were both salient and frequent. Only a few tens of examples per category were required and no label was needed. After learning, the complexity of the extracted features increased along the hierarchy, from edge detectors in the first layer to object prototypes in the last layer. Coding was very sparse, with only a few thousands spikes per image, and in some cases the object category could be reasonably well inferred from the activity of a single higher-order neuron. More generally, the activity of a few hundreds of such neurons contained robust category information, as demonstrated using a classifier on Caltech 101, ETH-80, and MNIST databases. We also demonstrate the superiority of STDP over other unsupervised techniques such as random crops (HMAX) or auto-encoders. Taken together, our results suggest that the combination of STDP with latency coding may be a key to understanding the way that the primate visual system learns, its remarkable processing speed and its low energy consumption.
Object categorization in finer levels requires higher spatial frequencies, and therefore takes longer
Mar 29, 2017
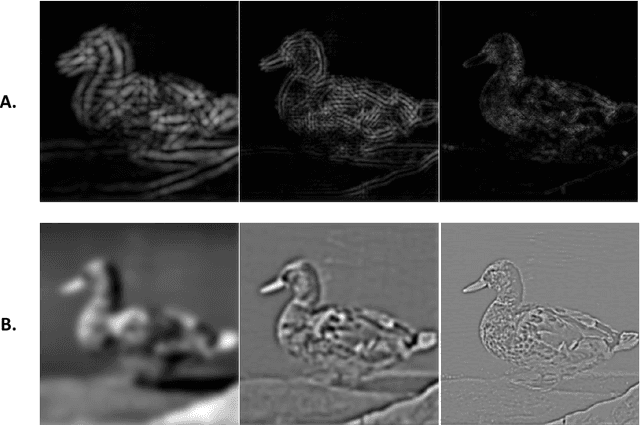
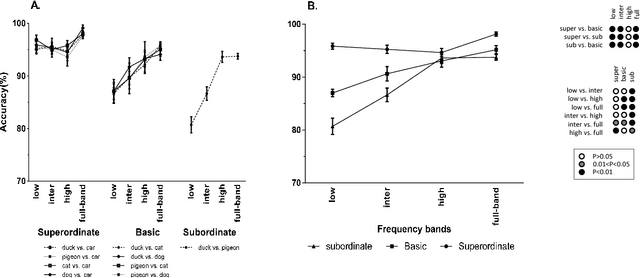
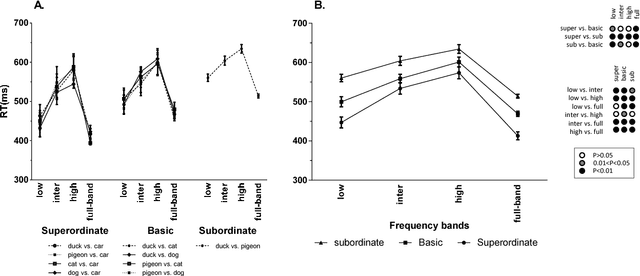
The human visual system contains a hierarchical sequence of modules that take part in visual perception at different levels of abstraction, i.e., superordinate, basic, and subordinate levels. One important question is to identify the "entry" level at which the visual representation is commenced in the process of object recognition. For a long time, it was believed that the basic level had advantage over two others; a claim that has been challenged recently. Here we used a series of psychophysics experiments, based on a rapid presentation paradigm, as well as two computational models, with bandpass filtered images to study the processing order of the categorization levels. In these experiments, we investigated the type of visual information required for categorizing objects in each level by varying the spatial frequency bands of the input image. The results of our psychophysics experiments and computational models are consistent. They indicate that the different spatial frequency information had different effects on object categorization in each level. In the absence of high frequency information, subordinate and basic level categorization are performed inaccurately, while superordinate level is performed well. This means that, low frequency information is sufficient for superordinate level, but not for the basic and subordinate levels. These finer levels require high frequency information, which appears to take longer to be processed, leading to longer reaction times. Finally, to avoid the ceiling effect, we evaluated the robustness of the results by adding different amounts of noise to the input images and repeating the experiments. As expected, the categorization accuracy decreased and the reaction time increased significantly, but the trends were the same.This shows that our results are not due to a ceiling effect.
Deep Networks Can Resemble Human Feed-forward Vision in Invariant Object Recognition
Jun 28, 2016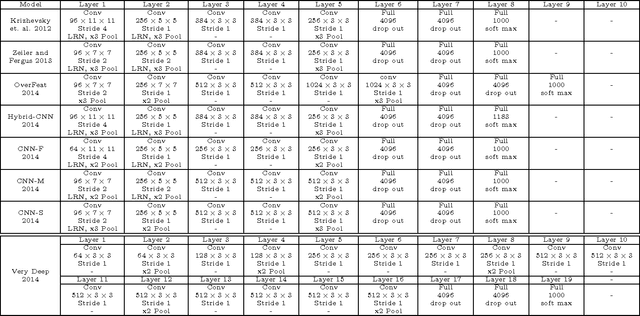

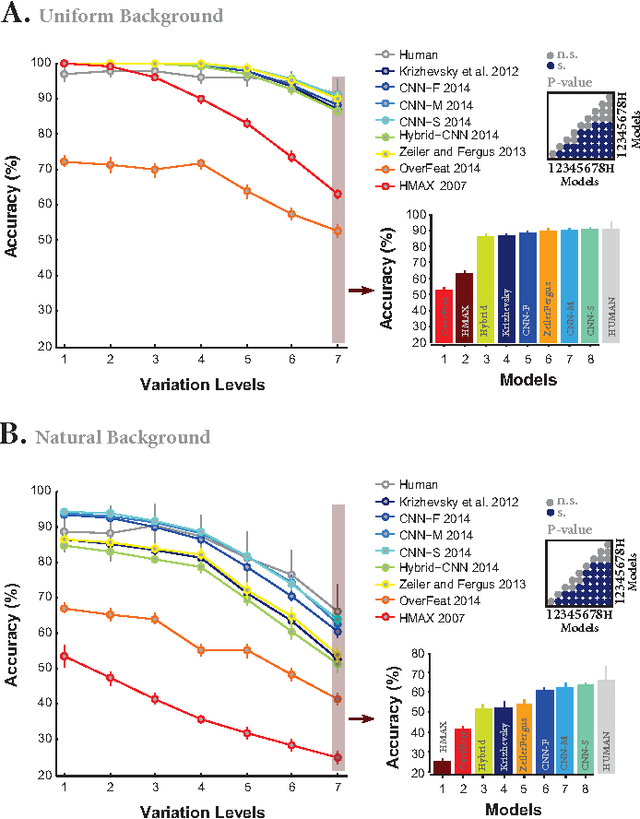
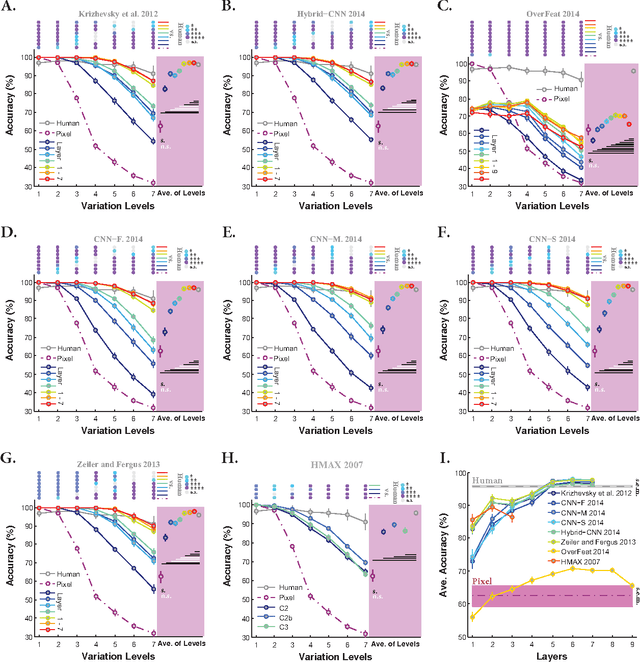
Deep convolutional neural networks (DCNNs) have attracted much attention recently, and have shown to be able to recognize thousands of object categories in natural image databases. Their architecture is somewhat similar to that of the human visual system: both use restricted receptive fields, and a hierarchy of layers which progressively extract more and more abstracted features. Yet it is unknown whether DCNNs match human performance at the task of view-invariant object recognition, whether they make similar errors and use similar representations for this task, and whether the answers depend on the magnitude of the viewpoint variations. To investigate these issues, we benchmarked eight state-of-the-art DCNNs, the HMAX model, and a baseline shallow model and compared their results to those of humans with backward masking. Unlike in all previous DCNN studies, we carefully controlled the magnitude of the viewpoint variations to demonstrate that shallow nets can outperform deep nets and humans when variations are weak. When facing larger variations, however, more layers were needed to match human performance and error distributions, and to have representations that are consistent with human behavior. A very deep net with 18 layers even outperformed humans at the highest variation level, using the most human-like representations.