 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersian-Phi: Efficient Cross-Lingual Adaptation of Compact LLMs via Curriculum Learning
Dec 08, 2025The democratization of AI is currently hindered by the immense computational costs required to train Large Language Models (LLMs) for low-resource languages. This paper presents Persian-Phi, a 3.8B parameter model that challenges the assumption that robust multilingual capabilities require massive model sizes or multilingual baselines. We demonstrate how Microsoft Phi-3 Mini -- originally a monolingual English model -- can be effectively adapted to Persian through a novel, resource-efficient curriculum learning pipeline. Our approach employs a unique "warm-up" stage using bilingual narratives (Tiny Stories) to align embeddings prior to heavy training, followed by continual pretraining and instruction tuning via Parameter-Efficient Fine-Tuning (PEFT). Despite its compact size, Persian-Phi achieves competitive results on Open Persian LLM Leaderboard in HuggingFace. Our findings provide a validated, scalable framework for extending the reach of state-of-the-art LLMs to underrepresented languages with minimal hardware resources. The Persian-Phi model is publicly available at https://huggingface.co/amirakhlaghiqqq/PersianPhi.
Backpropagation-free Spiking Neural Networks with the Forward-Forward Algorithm
Feb 19, 2025Spiking Neural Networks (SNNs) offer a biologically inspired computational paradigm that emulates neuronal activity through discrete spike-based processing. Despite their advantages, training SNNs with traditional backpropagation (BP) remains challenging due to computational inefficiencies and a lack of biological plausibility. This study explores the Forward-Forward (FF) algorithm as an alternative learning framework for SNNs. Unlike backpropagation, which relies on forward and backward passes, the FF algorithm employs two forward passes, enabling localized learning, enhanced computational efficiency, and improved compatibility with neuromorphic hardware. We introduce an FF-based SNN training framework and evaluate its performance across both non-spiking (MNIST, Fashion-MNIST, CIFAR-10) and spiking (Neuro-MNIST, SHD) datasets. Experimental results demonstrate that our model surpasses existing FF-based SNNs by over 5% on MNIST and Fashion-MNIST while achieving accuracy comparable to state-of-the-art backpropagation-trained SNNs. On more complex tasks such as CIFAR-10 and SHD, our approach outperforms other SNN models by up to 6% and remains competitive with leading backpropagation-trained SNNs. These findings highlight the FF algorithm's potential to advance SNN training methodologies and neuromorphic computing by addressing key limitations of backpropagation.
Meta-Learning in Spiking Neural Networks with Reward-Modulated STDP
Jun 07, 2023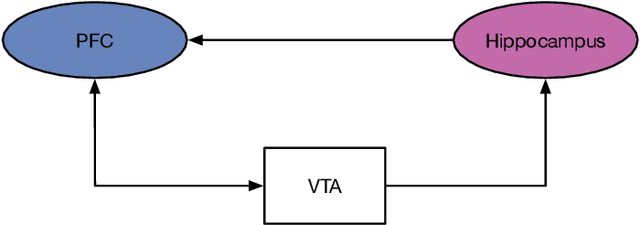
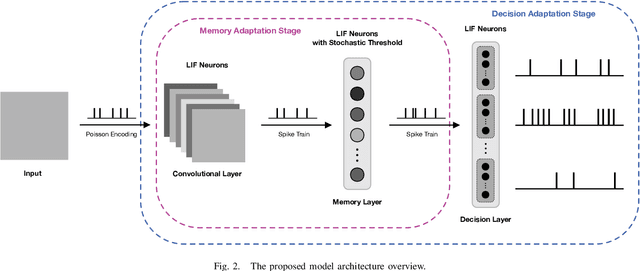


The human brain constantly learns and rapidly adapts to new situations by integrating acquired knowledge and experiences into memory. Developing this capability in machine learning models is considered an important goal of AI research since deep neural networks perform poorly when there is limited data or when they need to adapt quickly to new unseen tasks. Meta-learning models are proposed to facilitate quick learning in low-data regimes by employing absorbed information from the past. Although some models have recently been introduced that reached high-performance levels, they are not biologically plausible. We have proposed a bio-plausible meta-learning model inspired by the hippocampus and the prefrontal cortex using spiking neural networks with a reward-based learning system. Our proposed model includes a memory designed to prevent catastrophic forgetting, a phenomenon that occurs when meta-learning models forget what they have learned as soon as the new task begins. Also, our new model can easily be applied to spike-based neuromorphic devices and enables fast learning in neuromorphic hardware. The final analysis will discuss the implications and predictions of the model for solving few-shot classification tasks. In solving these tasks, our model has demonstrated the ability to compete with the existing state-of-the-art meta-learning techniques.
Drastically Reducing the Number of Trainable Parameters in Deep CNNs by Inter-layer Kernel-sharing
Oct 23, 2022



Deep convolutional neural networks (DCNNs) have become the state-of-the-art (SOTA) approach for many computer vision tasks: image classification, object detection, semantic segmentation, etc. However, most SOTA networks are too large for edge computing. Here, we suggest a simple way to reduce the number of trainable parameters and thus the memory footprint: sharing kernels between multiple convolutional layers. Kernel-sharing is only possible between ``isomorphic" layers, i.e.layers having the same kernel size, input and output channels. This is typically the case inside each stage of a DCNN. Our experiments on CIFAR-10 and CIFAR-100, using the ConvMixer and SE-ResNet architectures show that the number of parameters of these models can drastically be reduced with minimal cost on accuracy. The resulting networks are appealing for certain edge computing applications that are subject to severe memory constraints, and even more interesting if leveraging "frozen weights" hardware accelerators. Kernel-sharing is also an efficient regularization method, which can reduce overfitting. The codes are publicly available at https://github.com/AlirezaAzadbakht/kernel-sharing.
Spiking neural networks trained via proxy
Sep 27, 2021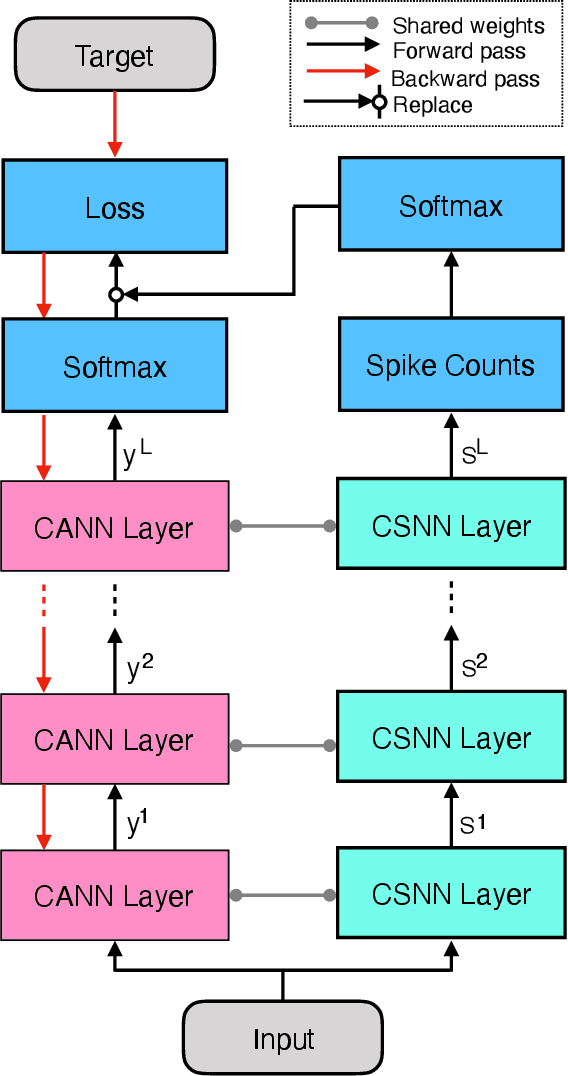

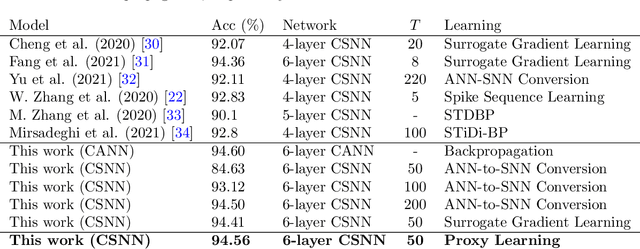

We propose a new learning algorithm to train spiking neural networks (SNN) using conventional artificial neural networks (ANN) as proxy. We couple two SNN and ANN networks, respectively, made of integrate-and-fire (IF) and ReLU neurons with the same network architectures and shared synaptic weights. The forward passes of the two networks are totally independent. By assuming IF neuron with rate-coding as an approximation of ReLU, we backpropagate the error of the SNN in the proxy ANN to update the shared weights, simply by replacing the ANN final output with that of the SNN. We applied the proposed proxy learning to deep convolutional SNNs and evaluated it on two benchmarked datasets of Fahion-MNIST and Cifar10 with 94.56% and 93.11% classification accuracy, respectively. The proposed networks could outperform other deep SNNs trained with tandem learning, surrogate gradient learning, or converted from deep ANNs. Converted SNNs require long simulation times to reach reasonable accuracies while our proxy learning leads to efficient SNNs with much shorter simulation times.
BioLCNet: Reward-modulated Locally Connected Spiking Neural Networks
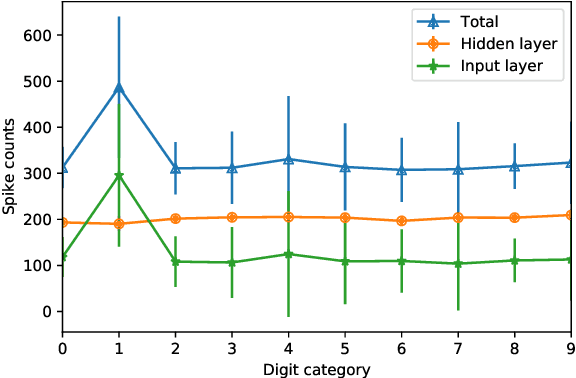
Sep 12, 2021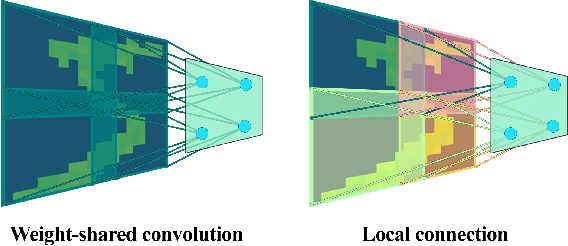
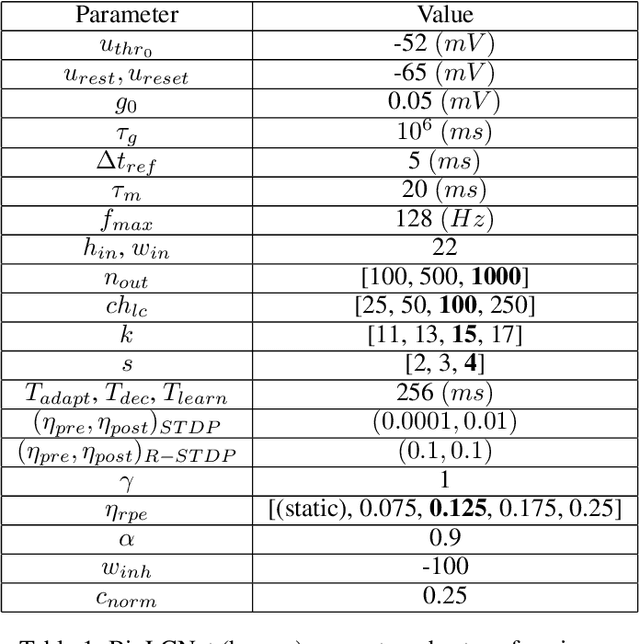
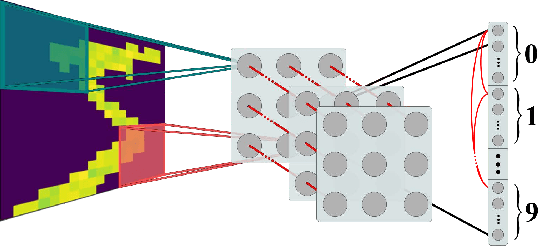

Recent studies have shown that convolutional neural networks (CNNs) are not the only feasible solution for image classification. Furthermore, weight sharing and backpropagation used in CNNs do not correspond to the mechanisms present in the primate visual system. To propose a more biologically plausible solution, we designed a locally connected spiking neural network (SNN) trained using spike-timing-dependent plasticity (STDP) and its reward-modulated variant (R-STDP) learning rules. The use of spiking neurons and local connections along with reinforcement learning (RL) led us to the nomenclature BioLCNet for our proposed architecture. Our network consists of a rate-coded input layer followed by a locally connected hidden layer and a decoding output layer. A spike population-based voting scheme is adopted for decoding in the output layer. We used the MNIST dataset to obtain image classification accuracy and to assess the robustness of our rewarding system to varying target responses.
Spike time displacement based error backpropagation in convolutional spiking neural networks
Aug 31, 2021



We recently proposed the STiDi-BP algorithm, which avoids backward recursive gradient computation, for training multi-layer spiking neural networks (SNNs) with single-spike-based temporal coding. The algorithm employs a linear approximation to compute the derivative of the spike latency with respect to the membrane potential and it uses spiking neurons with piecewise linear postsynaptic potential to reduce the computational cost and the complexity of neural processing. In this paper, we extend the STiDi-BP algorithm to employ it in deeper and convolutional architectures. The evaluation results on the image classification task based on two popular benchmarks, MNIST and Fashion-MNIST datasets with the accuracies of respectively 99.2% and 92.8%, confirm that this algorithm has been applicable in deep SNNs. Another issue we consider is the reduction of memory storage and computational cost. To do so, we consider a convolutional SNN (CSNN) with two sets of weights: real-valued weights that are updated in the backward pass and their signs, binary weights, that are employed in the feedforward process. We evaluate the binary CSNN on two datasets of MNIST and Fashion-MNIST and obtain acceptable performance with a negligible accuracy drop with respect to real-valued weights (about $0.6%$ and $0.8%$ drops, respectively).
BS4NN: Binarized Spiking Neural Networks with Temporal Coding and Learning
Jul 08, 2020


We recently proposed the S4NN algorithm, essentially an adaptation of backpropagation to multilayer spiking neural networks that use simple non-leaky integrate-and-fire neurons and a form of temporal coding known as time-to-first-spike coding. With this coding scheme, neurons fire at most once per stimulus, but the firing order carries information. Here, we introduce BS4NN, a modification of S4NN in which the synaptic weights are constrained to be binary (+1 or -1), in order to decrease memory and computation footprints. This was done using two sets of weights: firstly, real-valued weights, updated by gradient descent, and used in the backward pass of backpropagation, and secondly, their signs, used in the forward pass. Similar strategies have been used to train (non-spiking) binarized neural networks. The main difference is that BS4NN operates in the time domain: spikes are propagated sequentially, and different neurons may reach their threshold at different times, which increases computational power. We validated BS4NN on two popular benchmarks, MNIST and Fashion MNIST, and obtained state-of-the-art accuracies for this sort of networks (97.0% and 87.3% respectively) with a negligible accuracy drop with respect to real-valued weights (0.4% and 0.7%, respectively). We also demonstrated that BS4NN outperforms a simple BNN with the same architectures on those two datasets (by 0.2% and 0.9% respectively), presumably because it leverages the temporal dimension.
Action Recognition Using Supervised Spiking Neural Networks
Nov 09, 2019
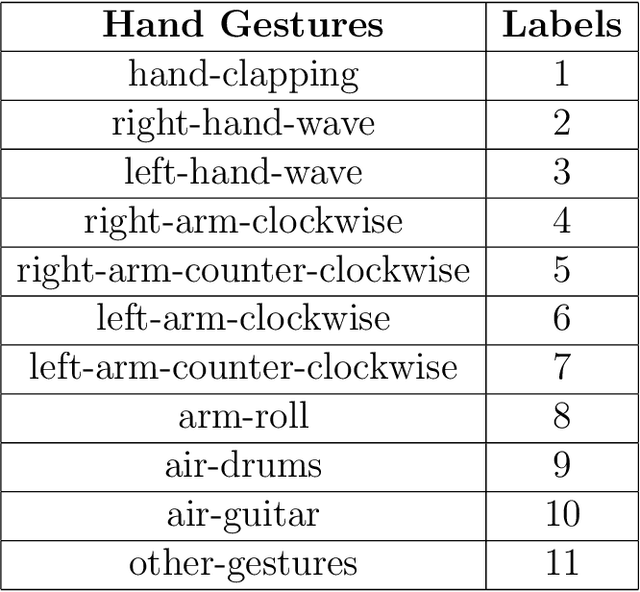
Biological neurons use spikes to process and learn temporally dynamic inputs in an energy and computationally efficient way. However, applying the state-of-the-art gradient-based supervised algorithms to spiking neural networks (SNN) is a challenge due to the non-differentiability of the activation function of spiking neurons. Employing surrogate gradients is one of the main solutions to overcome this challenge. Although SNNs naturally work in the temporal domain, recent studies have focused on developing SNNs to solve static image categorization tasks. In this paper, we employ a surrogate gradient descent learning algorithm to recognize twelve human hand gestures recorded by dynamic vision sensor (DVS) cameras. The proposed SNN could reach 97.2% recognition accuracy on test data.
S4NN: temporal backpropagation for spiking neural networks with one spike per neuron
Oct 21, 2019


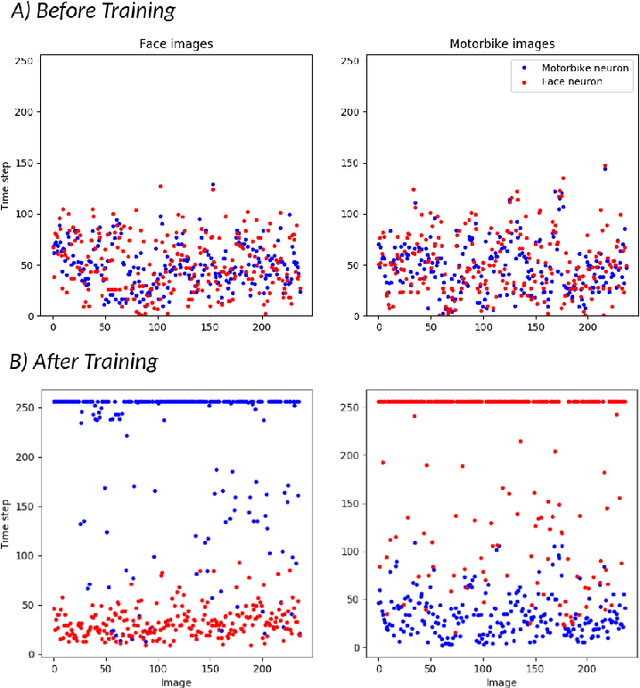
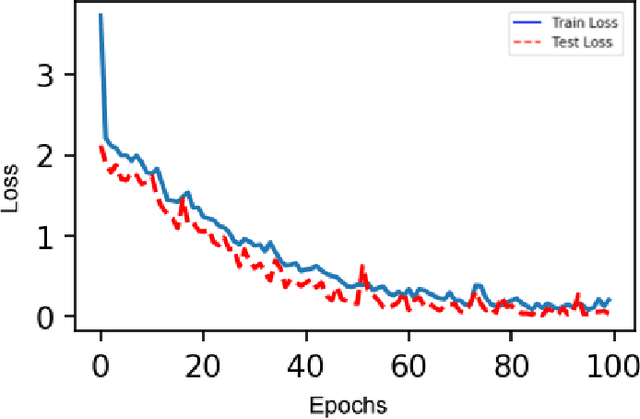
We propose a new supervised learning rule for multilayer spiking neural networks (SNN) that use a form of temporal coding known as rank-order-coding. With this coding scheme, all neurons fire exactly one spike per stimulus, but the firing order carries information. In particular, in the readout layer, the first neuron to fire determines the class of the stimulus. We derive a new learning rule for this sort of network, termed S4NN, akin to traditional error backpropagation, yet based on latencies. We show how approximate error gradients can be computed backward in a feedforward network with an arbitrary number of layers. This approach reaches state-of-the-art performance with SNNs: test accuracy of 97.4% for the MNIST dataset, and of 99.2% for the Caltech Face/Motorbike dataset. Yet the neuron model we use, non-leaky integrate-and-fire, are simpler and more hardware friendly than the one used in all previous similar proposals.