 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncluding local feature interactions in deep non-negative matrix factorization networks improves performance
Mar 26, 2025



The brain uses positive signals as a means of signaling. Forward interactions in the early visual cortex are also positive, realized by excitatory synapses. Only local interactions also include inhibition. Non-negative matrix factorization (NMF) captures the biological constraint of positive long-range interactions and can be implemented with stochastic spikes. While NMF can serve as an abstract formalization of early neural processing in the visual system, the performance of deep convolutional networks with NMF modules does not match that of CNNs of similar size. However, when the local NMF modules are each followed by a module that mixes the NMF's positive activities, the performances on the benchmark data exceed that of vanilla deep convolutional networks of similar size. This setting can be considered a biologically more plausible emulation of the processing in cortical (hyper-)columns with the potential to improve the performance of deep networks.
Revealing Model Biases: Assessing Deep Neural Networks via Recovered Sample Analysis
Jun 10, 2023



This paper proposes a straightforward and cost-effective approach to assess whether a deep neural network (DNN) relies on the primary concepts of training samples or simply learns discriminative, yet simple and irrelevant features that can differentiate between classes. The paper highlights that DNNs, as discriminative classifiers, often find the simplest features to discriminate between classes, leading to a potential bias towards irrelevant features and sometimes missing generalization. While a generalization test is one way to evaluate a trained model's performance, it can be costly and may not cover all scenarios to ensure that the model has learned the primary concepts. Furthermore, even after conducting a generalization test, identifying bias in the model may not be possible. Here, the paper proposes a method that involves recovering samples from the parameters of the trained model and analyzing the reconstruction quality. We believe that if the model's weights are optimized to discriminate based on some features, these features will be reflected in the reconstructed samples. If the recovered samples contain the primary concepts of the training data, it can be concluded that the model has learned the essential and determining features. On the other hand, if the recovered samples contain irrelevant features, it can be concluded that the model is biased towards these features. The proposed method does not require any test or generalization samples, only the parameters of the trained model and the training data that lie on the margin. Our experiments demonstrate that the proposed method can determine whether the model has learned the desired features of the training data. The paper highlights that our understanding of how these models work is limited, and the proposed approach addresses this issue.
BioLCNet: Reward-modulated Locally Connected Spiking Neural Networks
Sep 12, 2021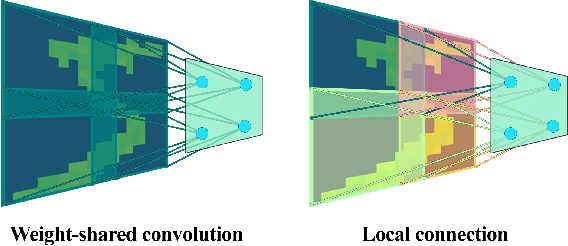
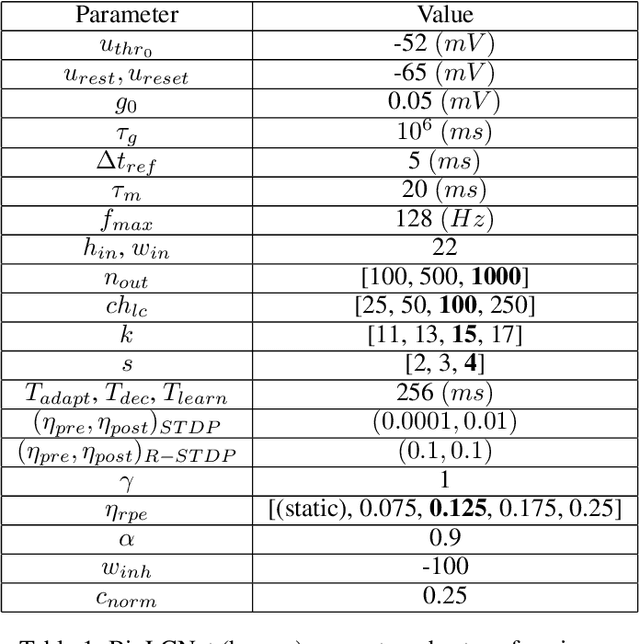
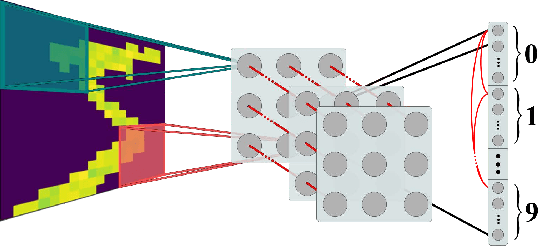

Recent studies have shown that convolutional neural networks (CNNs) are not the only feasible solution for image classification. Furthermore, weight sharing and backpropagation used in CNNs do not correspond to the mechanisms present in the primate visual system. To propose a more biologically plausible solution, we designed a locally connected spiking neural network (SNN) trained using spike-timing-dependent plasticity (STDP) and its reward-modulated variant (R-STDP) learning rules. The use of spiking neurons and local connections along with reinforcement learning (RL) led us to the nomenclature BioLCNet for our proposed architecture. Our network consists of a rate-coded input layer followed by a locally connected hidden layer and a decoding output layer. A spike population-based voting scheme is adopted for decoding in the output layer. We used the MNIST dataset to obtain image classification accuracy and to assess the robustness of our rewarding system to varying target responses.
Toward Real-World BCI: CCSPNet, A Compact Subject-Independent Motor Imagery Framework
Jan 02, 2021
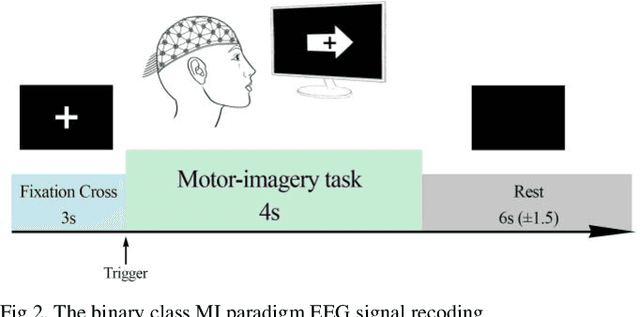
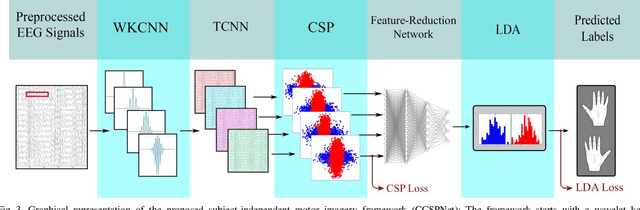
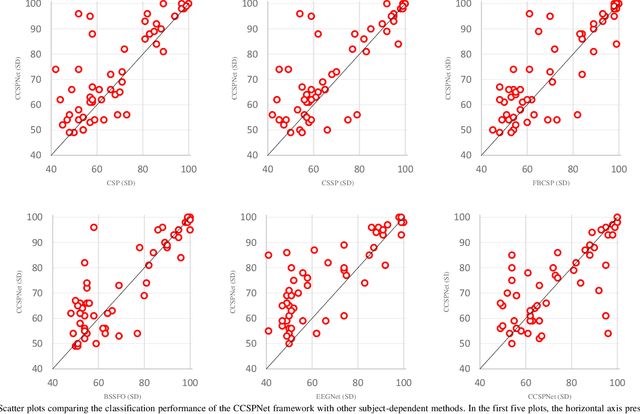
A conventional brain-computer interface (BCI) requires a complete data gathering, training, and calibration phase for each user before it can be used. This preliminary phase is time-consuming and should be done under the supervision of technical experts commonly in laboratories for the BCI to function properly. In recent years, a number of subject-independent (SI) BCIs have been developed. However, there are many problems preventing them from being used in real-world BCI applications. A lower accuracy than the subject-dependent (SD) approach and a relatively high run-time of models with a large number of model parameters are the most important ones. Therefore, a real-world BCI application would greatly benefit from a compact subject-independent BCI framework, ready to use immediately after the user puts it on, and suitable for low-power edge-computing and applications in the emerging area of internet of things (IoT). We propose a novel subject-independent BCI framework named CCSPNet (Convolutional Common Spatial Pattern Network) that is trained on the motor imagery (MI) paradigm of a large-scale EEG signals database consisting of 400 trials for every 54 subjects performing two-class hand-movement MI tasks. The proposed framework applies a wavelet kernel convolutional neural network (WKCNN) and a temporal convolutional neural network (TCNN) in order to represent and extract the diverse frequency behavior and spectral patterns of EEG signals. The convolutional layers outputs go through a CSP algorithm for class discrimination and spatial feature extraction. The number of CSP features is reduced by a dense neural network, and the final class label is determined by an LDA. The final SD and SI classification accuracies of the proposed framework match the best results obtained on the largest motor-imagery dataset present in the BCI literature, with 99.993 percent fewer model parameters.