 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Are We Really Measuring? Rethinking Dataset Bias in Web-Scale Natural Image Collections via Unsupervised Semantic Clustering
Apr 15, 2026In computer vision, a prevailing method for quantifying dataset bias is to train a model to distinguish between datasets. High classification accuracy is then interpreted as evidence of meaningful semantic differences. This approach assumes that standard image augmentations successfully suppress low-level, non-semantic cues, and that any remaining performance must therefore reflect true semantic divergence. We demonstrate that this fundamental assumption is flawed within the domain of large-scale natural image collections. High classification accuracy is often driven by resolution-based artifacts, which are structural fingerprints arising from native image resolution distributions and interpolation effects during resizing. These artifacts form robust, dataset-specific signatures that persist despite conventional image corruptions. Through controlled experiments, we show that models achieve strong dataset classification even on non-semantic, procedurally generated images, proving their reliance on superficial cues. To address this issue, we revisit this decades-old idea of dataset separability, but not with supervised classification. Instead, we introduce an unsupervised approach that measures true semantic separability. Our framework directly assesses semantic similarity by clustering semantically-rich features from foundational vision models, deliberately bypassing supervised classification on dataset labels. When applied to major web-scale datasets, the primary focus of this work, the high separability reported by supervised methods largely vanishes, with clustering accuracy dropping to near-chance levels. This reveals that conventional classification-based evaluation systematically overstates semantic bias by an overwhelming margin.
Exploiting Layer-Specific Vulnerabilities to Backdoor Attack in Federated Learning
Feb 16, 2026Federated learning (FL) enables distributed model training across edge devices while preserving data locality. This decentralized approach has emerged as a promising solution for collaborative learning on sensitive user data, effectively addressing the longstanding privacy concerns inherent in centralized systems. However, the decentralized nature of FL exposes new security vulnerabilities, especially backdoor attacks that threaten model integrity. To investigate this critical concern, this paper presents the Layer Smoothing Attack (LSA), a novel backdoor attack that exploits layer-specific vulnerabilities in neural networks. First, a Layer Substitution Analysis methodology systematically identifies backdoor-critical (BC) layers that contribute most significantly to backdoor success. Subsequently, LSA strategically manipulates these BC layers to inject persistent backdoors while remaining undetected by state-of-the-art defense mechanisms. Extensive experiments across diverse model architectures and datasets demonstrate that LSA achieves a remarkably backdoor success rate of up to 97% while maintaining high model accuracy on the primary task, consistently bypassing modern FL defenses. These findings uncover fundamental vulnerabilities in current FL security frameworks, demonstrating that future defenses must incorporate layer-aware detection and mitigation strategies.
TIPS Over Tricks: Simple Prompts for Effective Zero-shot Anomaly Detection
Feb 03, 2026Anomaly detection identifies departures from expected behavior in safety-critical settings. When target-domain normal data are unavailable, zero-shot anomaly detection (ZSAD) leverages vision-language models (VLMs). However, CLIP's coarse image-text alignment limits both localization and detection due to (i) spatial misalignment and (ii) weak sensitivity to fine-grained anomalies; prior work compensates with complex auxiliary modules yet largely overlooks the choice of backbone. We revisit the backbone and use TIPS-a VLM trained with spatially aware objectives. While TIPS alleviates CLIP's issues, it exposes a distributional gap between global and local features. We address this with decoupled prompts-fixed for image-level detection and learnable for pixel-level localization-and by injecting local evidence into the global score. Without CLIP-specific tricks, our TIPS-based pipeline improves image-level performance by 1.1-3.9% and pixel-level by 1.5-6.9% across seven industrial datasets, delivering strong generalization with a lean architecture. Code is available at github.com/AlirezaSalehy/Tipsomaly.
FrameShield: Adversarially Robust Video Anomaly Detection
Oct 24, 2025Weakly Supervised Video Anomaly Detection (WSVAD) has achieved notable advancements, yet existing models remain vulnerable to adversarial attacks, limiting their reliability. Due to the inherent constraints of weak supervision, where only video-level labels are provided despite the need for frame-level predictions, traditional adversarial defense mechanisms, such as adversarial training, are not effective since video-level adversarial perturbations are typically weak and inadequate. To address this limitation, pseudo-labels generated directly from the model can enable frame-level adversarial training; however, these pseudo-labels are inherently noisy, significantly degrading performance. We therefore introduce a novel Pseudo-Anomaly Generation method called Spatiotemporal Region Distortion (SRD), which creates synthetic anomalies by applying severe augmentations to localized regions in normal videos while preserving temporal consistency. Integrating these precisely annotated synthetic anomalies with the noisy pseudo-labels substantially reduces label noise, enabling effective adversarial training. Extensive experiments demonstrate that our method significantly enhances the robustness of WSVAD models against adversarial attacks, outperforming state-of-the-art methods by an average of 71.0\% in overall AUROC performance across multiple benchmarks. The implementation and code are publicly available at https://github.com/rohban-lab/FrameShield.
* 28 page, 5 figures
APML: Adaptive Probabilistic Matching Loss for Robust 3D Point Cloud Reconstruction
Sep 09, 2025Training deep learning models for point cloud prediction tasks such as shape completion and generation depends critically on loss functions that measure discrepancies between predicted and ground-truth point sets. Commonly used functions such as Chamfer Distance (CD), HyperCD, and InfoCD rely on nearest-neighbor assignments, which often induce many-to-one correspondences, leading to point congestion in dense regions and poor coverage in sparse regions. These losses also involve non-differentiable operations due to index selection, which may affect gradient-based optimization. Earth Mover Distance (EMD) enforces one-to-one correspondences and captures structural similarity more effectively, but its cubic computational complexity limits its practical use. We propose the Adaptive Probabilistic Matching Loss (APML), a fully differentiable approximation of one-to-one matching that leverages Sinkhorn iterations on a temperature-scaled similarity matrix derived from pairwise distances. We analytically compute the temperature to guarantee a minimum assignment probability, eliminating manual tuning. APML achieves near-quadratic runtime, comparable to Chamfer-based losses, and avoids non-differentiable operations. When integrated into state-of-the-art architectures (PoinTr, PCN, FoldingNet) on ShapeNet benchmarks and on a spatiotemporal Transformer (CSI2PC) that generates 3D human point clouds from WiFi CSI measurements, APM loss yields faster convergence, superior spatial distribution, especially in low-density regions, and improved or on-par quantitative performance without additional hyperparameter search. The code is available at: https://github.com/apm-loss/apml.
PhiNet v2: A Mask-Free Brain-Inspired Vision Foundation Model from Video
May 16, 2025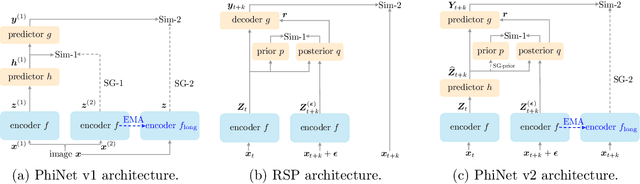

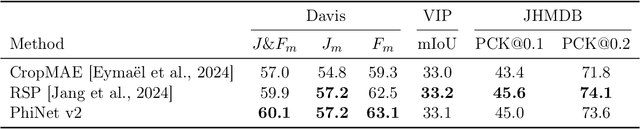

Recent advances in self-supervised learning (SSL) have revolutionized computer vision through innovative architectures and learning objectives, yet they have not fully leveraged insights from biological visual processing systems. Recently, a brain-inspired SSL model named PhiNet was proposed; it is based on a ResNet backbone and operates on static image inputs with strong augmentation. In this paper, we introduce PhiNet v2, a novel Transformer-based architecture that processes temporal visual input (that is, sequences of images) without relying on strong augmentation. Our model leverages variational inference to learn robust visual representations from continuous input streams, similar to human visual processing. Through extensive experimentation, we demonstrate that PhiNet v2 achieves competitive performance compared to state-of-the-art vision foundation models, while maintaining the ability to learn from sequential input without strong data augmentation. This work represents a significant step toward more biologically plausible computer vision systems that process visual information in a manner more closely aligned with human cognitive processes.
Crane: Context-Guided Prompt Learning and Attention Refinement for Zero-Shot Anomaly Detections
Apr 15, 2025



Anomaly Detection (AD) involves identifying deviations from normal data distributions and is critical in fields such as medical diagnostics and industrial defect detection. Traditional AD methods typically require the availability of normal training samples; however, this assumption is not always feasible, as collecting such data can be impractical. Additionally, these methods often struggle to generalize across different domains. Recent advancements, such as AnomalyCLIP and AdaCLIP, utilize the zero-shot generalization capabilities of CLIP but still face a performance gap between image-level and pixel-level anomaly detection. To address this gap, we propose a novel approach that conditions the prompts of the text encoder based on image context extracted from the vision encoder. Also, to capture fine-grained variations more effectively, we have modified the CLIP vision encoder and altered the extraction of dense features. These changes ensure that the features retain richer spatial and structural information for both normal and anomalous prompts. Our method achieves state-of-the-art performance, improving performance by 2% to 29% across different metrics on 14 datasets. This demonstrates its effectiveness in both image-level and pixel-level anomaly detection.
Scanning Trojaned Models Using Out-of-Distribution Samples
Jan 28, 2025



Scanning for trojan (backdoor) in deep neural networks is crucial due to their significant real-world applications. There has been an increasing focus on developing effective general trojan scanning methods across various trojan attacks. Despite advancements, there remains a shortage of methods that perform effectively without preconceived assumptions about the backdoor attack method. Additionally, we have observed that current methods struggle to identify classifiers trojaned using adversarial training. Motivated by these challenges, our study introduces a novel scanning method named TRODO (TROjan scanning by Detection of adversarial shifts in Out-of-distribution samples). TRODO leverages the concept of "blind spots"--regions where trojaned classifiers erroneously identify out-of-distribution (OOD) samples as in-distribution (ID). We scan for these blind spots by adversarially shifting OOD samples towards in-distribution. The increased likelihood of perturbed OOD samples being classified as ID serves as a signature for trojan detection. TRODO is both trojan and label mapping agnostic, effective even against adversarially trained trojaned classifiers. It is applicable even in scenarios where training data is absent, demonstrating high accuracy and adaptability across various scenarios and datasets, highlighting its potential as a robust trojan scanning strategy.
A Contrastive Teacher-Student Framework for Novelty Detection under Style Shifts
Jan 28, 2025



There have been several efforts to improve Novelty Detection (ND) performance. However, ND methods often suffer significant performance drops under minor distribution shifts caused by changes in the environment, known as style shifts. This challenge arises from the ND setup, where the absence of out-of-distribution (OOD) samples during training causes the detector to be biased toward the dominant style features in the in-distribution (ID) data. As a result, the model mistakenly learns to correlate style with core features, using this shortcut for detection. Robust ND is crucial for real-world applications like autonomous driving and medical imaging, where test samples may have different styles than the training data. Motivated by this, we propose a robust ND method that crafts an auxiliary OOD set with style features similar to the ID set but with different core features. Then, a task-based knowledge distillation strategy is utilized to distinguish core features from style features and help our model rely on core features for discriminating crafted OOD and ID sets. We verified the effectiveness of our method through extensive experimental evaluations on several datasets, including synthetic and real-world benchmarks, against nine different ND methods.
Mitigating Spurious Negative Pairs for Robust Industrial Anomaly Detection
Jan 26, 2025



Despite significant progress in Anomaly Detection (AD), the robustness of existing detection methods against adversarial attacks remains a challenge, compromising their reliability in critical real-world applications such as autonomous driving. This issue primarily arises from the AD setup, which assumes that training data is limited to a group of unlabeled normal samples, making the detectors vulnerable to adversarial anomaly samples during testing. Additionally, implementing adversarial training as a safeguard encounters difficulties, such as formulating an effective objective function without access to labels. An ideal objective function for adversarial training in AD should promote strong perturbations both within and between the normal and anomaly groups to maximize margin between normal and anomaly distribution. To address these issues, we first propose crafting a pseudo-anomaly group derived from normal group samples. Then, we demonstrate that adversarial training with contrastive loss could serve as an ideal objective function, as it creates both inter- and intra-group perturbations. However, we notice that spurious negative pairs compromise the conventional contrastive loss to achieve robust AD. Spurious negative pairs are those that should be closely mapped but are erroneously separated. These pairs introduce noise and misguide the direction of inter-group adversarial perturbations. To overcome the effect of spurious negative pairs, we define opposite pairs and adversarially pull them apart to strengthen inter-group perturbations. Experimental results demonstrate our superior performance in both clean and adversarial scenarios, with a 26.1% improvement in robust detection across various challenging benchmark datasets. The implementation of our work is available at: https://github.com/rohban-lab/COBRA.