 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Limitations and Optimization Approach in 1-Bit RIS Design at 28 GHz
Jun 10, 2025Reconfigurable intelligent surfaces (RIS) have emerged as a transformative technology for electromagnetic (EM) wave manipulation, offering unprecedented control over wave reflections compared to traditional metallic reflectors. By utilizing an array of tunable elements, RIS can steer and shape electromagnetic waves to enhance signal quality in wireless communication and radar systems. However, practical implementations face significant challenges due to hardware limitations and phase quantization errors. In this work, a 1-bit RIS prototype operating at 28 GHz is developed to experimentally evaluate the impact of hardware constraints on RIS performance. Unlike conventional studies that model RIS as an ideal phase-shift matrix, this study accounts for physical parameters that influence the actual reflection pattern. In particular, the presence of specular reflection due to hardware limitations is investigated. Additionally, the effects of phase quantization errors, which stem from the discrete nature of RIS elements, are analyzed, and a genetic algorithm (GA)-based optimization is introduced to mitigate these errors. The proposed optimization strategy effectively reduces gain degradation at the desired angle caused by 1-bit quantization, enhancing the overall performance of RIS. The effectiveness of the approach is validated through measurements, underscoring the importance of advanced phase control techniques in improving the functionality of RIS.
Continual Learning: Less Forgetting, More OOD Generalization via Adaptive Contrastive Replay
Oct 09, 2024



Machine learning models often suffer from catastrophic forgetting of previously learned knowledge when learning new classes. Various methods have been proposed to mitigate this issue. However, rehearsal-based learning, which retains samples from previous classes, typically achieves good performance but tends to memorize specific instances, struggling with Out-of-Distribution (OOD) generalization. This often leads to high forgetting rates and poor generalization. Surprisingly, the OOD generalization capabilities of these methods have been largely unexplored. In this paper, we highlight this issue and propose a simple yet effective strategy inspired by contrastive learning and data-centric principles to address it. We introduce Adaptive Contrastive Replay (ACR), a method that employs dual optimization to simultaneously train both the encoder and the classifier. ACR adaptively populates the replay buffer with misclassified samples while ensuring a balanced representation of classes and tasks. By refining the decision boundary in this way, ACR achieves a balance between stability and plasticity. Our method significantly outperforms previous approaches in terms of OOD generalization, achieving an improvement of 13.41\% on Split CIFAR-100, 9.91\% on Split Mini-ImageNet, and 5.98\% on Split Tiny-ImageNet.
Class-Adaptive Sampling Policy for Efficient Continual Learning
Nov 27, 2023
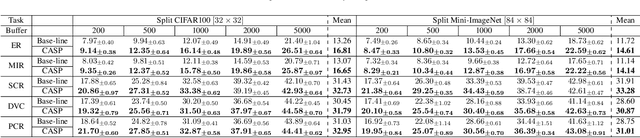


Continual learning (CL) aims to acquire new knowledge while preserving information from previous experiences without forgetting. Though buffer-based methods (i.e., retaining samples from previous tasks) have achieved acceptable performance, determining how to allocate the buffer remains a critical challenge. Most recent research focuses on refining these methods but often fails to sufficiently consider the varying influence of samples on the learning process, and frequently overlooks the complexity of the classes/concepts being learned. Generally, these methods do not directly take into account the contribution of individual classes. However, our investigation indicates that more challenging classes necessitate preserving a larger number of samples compared to less challenging ones. To address this issue, we propose a novel method and policy named 'Class-Adaptive Sampling Policy' (CASP), which dynamically allocates storage space within the buffer. By utilizing concepts of class contribution and difficulty, CASP adaptively manages buffer space, allowing certain classes to occupy a larger portion of the buffer while reducing storage for others. This approach significantly improves the efficiency of knowledge retention and utilization. CASP provides a versatile solution to boost the performance and efficiency of CL. It meets the demand for dynamic buffer allocation, accommodating the varying contributions of different classes and their learning complexities over time.
Quantifying Overfitting: Evaluating Neural Network Performance through Analysis of Null Space
May 30, 2023Machine learning models that are overfitted/overtrained are more vulnerable to knowledge leakage, which poses a risk to privacy. Suppose we download or receive a model from a third-party collaborator without knowing its training accuracy. How can we determine if it has been overfitted or overtrained on its training data? It's possible that the model was intentionally over-trained to make it vulnerable during testing. While an overfitted or overtrained model may perform well on testing data and even some generalization tests, we can't be sure it's not over-fitted. Conducting a comprehensive generalization test is also expensive. The goal of this paper is to address these issues and ensure the privacy and generalization of our method using only testing data. To achieve this, we analyze the null space in the last layer of neural networks, which enables us to quantify overfitting without access to training data or knowledge of the accuracy of those data. We evaluated our approach on various architectures and datasets and observed a distinct pattern in the angle of null space when models are overfitted. Furthermore, we show that models with poor generalization exhibit specific characteristics in this space. Our work represents the first attempt to quantify overfitting without access to training data or knowing any knowledge about the training samples.
Wireless End-to-End Image Transmission System using Semantic Communications
Feb 27, 2023



Semantic communication is considered the future of mobile communication, which aims to transmit data beyond Shannon's theorem of communications by transmitting the semantic meaning of the data rather than the bit-by-bit reconstruction of the data at the receiver's end. The semantic communication paradigm aims to bridge the gap of limited bandwidth problems in modern high-volume multimedia application content transmission. Integrating AI technologies with the 6G communications networks paved the way to develop semantic communication-based end-to-end communication systems. In this study, we have implemented a semantic communication-based end-to-end image transmission system, and we discuss potential design considerations in developing semantic communication systems in conjunction with physical channel characteristics. A Pre-trained GAN network is used at the receiver as the transmission task to reconstruct the realistic image based on the Semantic segmented image at the receiver input. The semantic segmentation task at the transmitter (encoder) and the GAN network at the receiver (decoder) is trained on a common knowledge base, the COCO-Stuff dataset. The research shows that the resource gain in the form of bandwidth saving is immense when transmitting the semantic segmentation map through the physical channel instead of the ground truth image in contrast to conventional communication systems. Furthermore, the research studies the effect of physical channel distortions and quantization noise on semantic communication-based multimedia content transmission.