 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISTIL: Data-Free Inversion of Suspicious Trojan Inputs via Latent Diffusion
Jul 30, 2025Deep neural networks have demonstrated remarkable success across numerous tasks, yet they remain vulnerable to Trojan (backdoor) attacks, raising serious concerns about their safety in real-world mission-critical applications. A common countermeasure is trigger inversion -- reconstructing malicious "shortcut" patterns (triggers) inserted by an adversary during training. Current trigger-inversion methods typically search the full pixel space under specific assumptions but offer no assurances that the estimated trigger is more than an adversarial perturbation that flips the model output. Here, we propose a data-free, zero-shot trigger-inversion strategy that restricts the search space while avoiding strong assumptions on trigger appearance. Specifically, we incorporate a diffusion-based generator guided by the target classifier; through iterative generation, we produce candidate triggers that align with the internal representations the model relies on for malicious behavior. Empirical evaluations, both quantitative and qualitative, show that our approach reconstructs triggers that effectively distinguish clean versus Trojaned models. DISTIL surpasses alternative methods by high margins, achieving up to 7.1% higher accuracy on the BackdoorBench dataset and a 9.4% improvement on trojaned object detection model scanning, offering a promising new direction for reliable backdoor defense without reliance on extensive data or strong prior assumptions about triggers. The code is available at https://github.com/AdaptiveMotorControlLab/DISTIL.
Scanning Trojaned Models Using Out-of-Distribution Samples
Jan 28, 2025



Scanning for trojan (backdoor) in deep neural networks is crucial due to their significant real-world applications. There has been an increasing focus on developing effective general trojan scanning methods across various trojan attacks. Despite advancements, there remains a shortage of methods that perform effectively without preconceived assumptions about the backdoor attack method. Additionally, we have observed that current methods struggle to identify classifiers trojaned using adversarial training. Motivated by these challenges, our study introduces a novel scanning method named TRODO (TROjan scanning by Detection of adversarial shifts in Out-of-distribution samples). TRODO leverages the concept of "blind spots"--regions where trojaned classifiers erroneously identify out-of-distribution (OOD) samples as in-distribution (ID). We scan for these blind spots by adversarially shifting OOD samples towards in-distribution. The increased likelihood of perturbed OOD samples being classified as ID serves as a signature for trojan detection. TRODO is both trojan and label mapping agnostic, effective even against adversarially trained trojaned classifiers. It is applicable even in scenarios where training data is absent, demonstrating high accuracy and adaptability across various scenarios and datasets, highlighting its potential as a robust trojan scanning strategy.
RODEO: Robust Outlier Detection via Exposing Adaptive Out-of-Distribution Samples
Jan 28, 2025In recent years, there have been significant improvements in various forms of image outlier detection. However, outlier detection performance under adversarial settings lags far behind that in standard settings. This is due to the lack of effective exposure to adversarial scenarios during training, especially on unseen outliers, leading to detection models failing to learn robust features. To bridge this gap, we introduce RODEO, a data-centric approach that generates effective outliers for robust outlier detection. More specifically, we show that incorporating outlier exposure (OE) and adversarial training can be an effective strategy for this purpose, as long as the exposed training outliers meet certain characteristics, including diversity, and both conceptual differentiability and analogy to the inlier samples. We leverage a text-to-image model to achieve this goal. We demonstrate both quantitatively and qualitatively that our adaptive OE method effectively generates ``diverse'' and ``near-distribution'' outliers, leveraging information from both text and image domains. Moreover, our experimental results show that utilizing our synthesized outliers significantly enhances the performance of the outlier detector, particularly in adversarial settings.
A Contrastive Teacher-Student Framework for Novelty Detection under Style Shifts
Jan 28, 2025



There have been several efforts to improve Novelty Detection (ND) performance. However, ND methods often suffer significant performance drops under minor distribution shifts caused by changes in the environment, known as style shifts. This challenge arises from the ND setup, where the absence of out-of-distribution (OOD) samples during training causes the detector to be biased toward the dominant style features in the in-distribution (ID) data. As a result, the model mistakenly learns to correlate style with core features, using this shortcut for detection. Robust ND is crucial for real-world applications like autonomous driving and medical imaging, where test samples may have different styles than the training data. Motivated by this, we propose a robust ND method that crafts an auxiliary OOD set with style features similar to the ID set but with different core features. Then, a task-based knowledge distillation strategy is utilized to distinguish core features from style features and help our model rely on core features for discriminating crafted OOD and ID sets. We verified the effectiveness of our method through extensive experimental evaluations on several datasets, including synthetic and real-world benchmarks, against nine different ND methods.
Mitigating Spurious Negative Pairs for Robust Industrial Anomaly Detection
Jan 26, 2025



Despite significant progress in Anomaly Detection (AD), the robustness of existing detection methods against adversarial attacks remains a challenge, compromising their reliability in critical real-world applications such as autonomous driving. This issue primarily arises from the AD setup, which assumes that training data is limited to a group of unlabeled normal samples, making the detectors vulnerable to adversarial anomaly samples during testing. Additionally, implementing adversarial training as a safeguard encounters difficulties, such as formulating an effective objective function without access to labels. An ideal objective function for adversarial training in AD should promote strong perturbations both within and between the normal and anomaly groups to maximize margin between normal and anomaly distribution. To address these issues, we first propose crafting a pseudo-anomaly group derived from normal group samples. Then, we demonstrate that adversarial training with contrastive loss could serve as an ideal objective function, as it creates both inter- and intra-group perturbations. However, we notice that spurious negative pairs compromise the conventional contrastive loss to achieve robust AD. Spurious negative pairs are those that should be closely mapped but are erroneously separated. These pairs introduce noise and misguide the direction of inter-group adversarial perturbations. To overcome the effect of spurious negative pairs, we define opposite pairs and adversarially pull them apart to strengthen inter-group perturbations. Experimental results demonstrate our superior performance in both clean and adversarial scenarios, with a 26.1% improvement in robust detection across various challenging benchmark datasets. The implementation of our work is available at: https://github.com/rohban-lab/COBRA.
Killing it with Zero-Shot: Adversarially Robust Novelty Detection
Jan 25, 2025



Novelty Detection (ND) plays a crucial role in machine learning by identifying new or unseen data during model inference. This capability is especially important for the safe and reliable operation of automated systems. Despite advances in this field, existing techniques often fail to maintain their performance when subject to adversarial attacks. Our research addresses this gap by marrying the merits of nearest-neighbor algorithms with robust features obtained from models pretrained on ImageNet. We focus on enhancing the robustness and performance of ND algorithms. Experimental results demonstrate that our approach significantly outperforms current state-of-the-art methods across various benchmarks, particularly under adversarial conditions. By incorporating robust pretrained features into the k-NN algorithm, we establish a new standard for performance and robustness in the field of robust ND. This work opens up new avenues for research aimed at fortifying machine learning systems against adversarial vulnerabilities. Our implementation is publicly available at https://github.com/rohban-lab/ZARND.
Backdooring Outlier Detection Methods: A Novel Attack Approach
Dec 06, 2024



There have been several efforts in backdoor attacks, but these have primarily focused on the closed-set performance of classifiers (i.e., classification). This has left a gap in addressing the threat to classifiers' open-set performance, referred to as outlier detection in the literature. Reliable outlier detection is crucial for deploying classifiers in critical real-world applications such as autonomous driving and medical image analysis. First, we show that existing backdoor attacks fall short in affecting the open-set performance of classifiers, as they have been specifically designed to confuse intra-closed-set decision boundaries. In contrast, an effective backdoor attack for outlier detection needs to confuse the decision boundary between the closed and open sets. Motivated by this, in this study, we propose BATOD, a novel Backdoor Attack targeting the Outlier Detection task. Specifically, we design two categories of triggers to shift inlier samples to outliers and vice versa. We evaluate BATOD using various real-world datasets and demonstrate its superior ability to degrade the open-set performance of classifiers compared to previous attacks, both before and after applying defenses.
Adversarially Robust Out-of-Distribution Detection Using Lyapunov-Stabilized Embeddings
Oct 14, 2024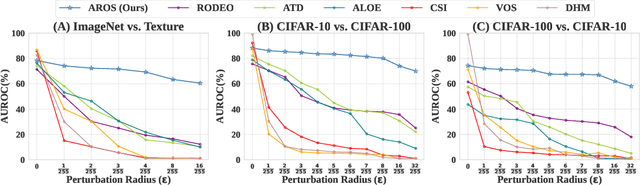
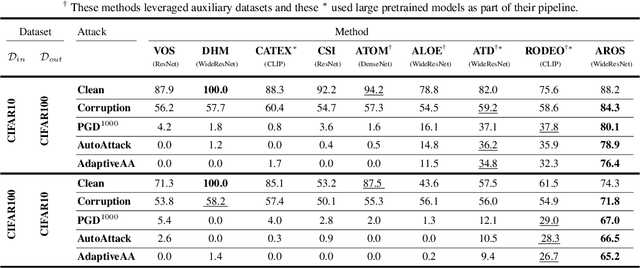
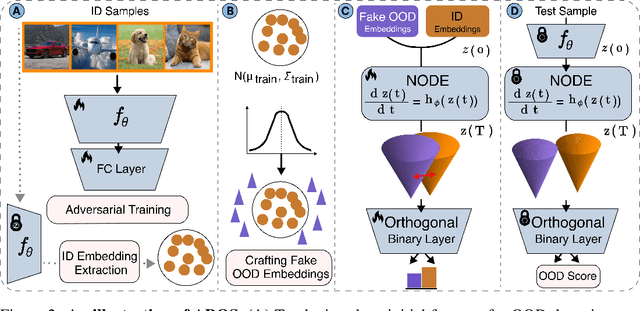
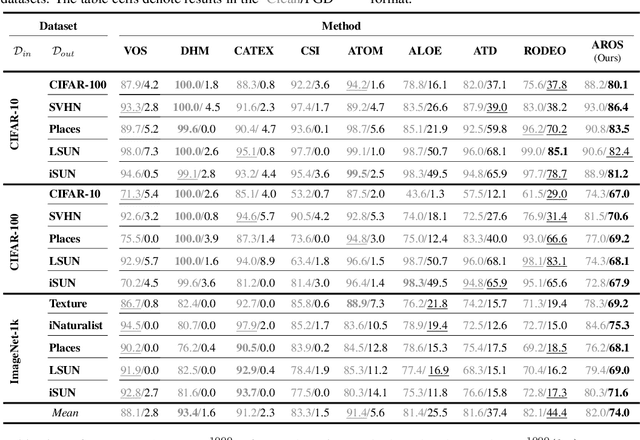
Despite significant advancements in out-of-distribution (OOD) detection, existing methods still struggle to maintain robustness against adversarial attacks, compromising their reliability in critical real-world applications. Previous studies have attempted to address this challenge by exposing detectors to auxiliary OOD datasets alongside adversarial training. However, the increased data complexity inherent in adversarial training, and the myriad of ways that OOD samples can arise during testing, often prevent these approaches from establishing robust decision boundaries. To address these limitations, we propose AROS, a novel approach leveraging neural ordinary differential equations (NODEs) with Lyapunov stability theorem in order to obtain robust embeddings for OOD detection. By incorporating a tailored loss function, we apply Lyapunov stability theory to ensure that both in-distribution (ID) and OOD data converge to stable equilibrium points within the dynamical system. This approach encourages any perturbed input to return to its stable equilibrium, thereby enhancing the model's robustness against adversarial perturbations. To not use additional data, we generate fake OOD embeddings by sampling from low-likelihood regions of the ID data feature space, approximating the boundaries where OOD data are likely to reside. To then further enhance robustness, we propose the use of an orthogonal binary layer following the stable feature space, which maximizes the separation between the equilibrium points of ID and OOD samples. We validate our method through extensive experiments across several benchmarks, demonstrating superior performance, particularly under adversarial attacks. Notably, our approach improves robust detection performance from 37.8% to 80.1% on CIFAR-10 vs. CIFAR-100 and from 29.0% to 67.0% on CIFAR-100 vs. CIFAR-10.
Universal Novelty Detection Through Adaptive Contrastive Learning
Aug 20, 2024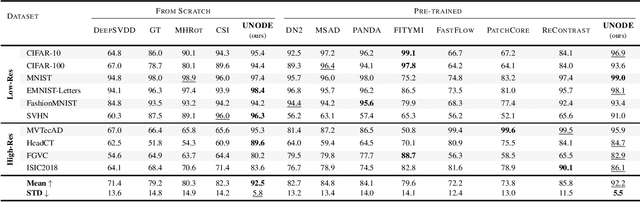
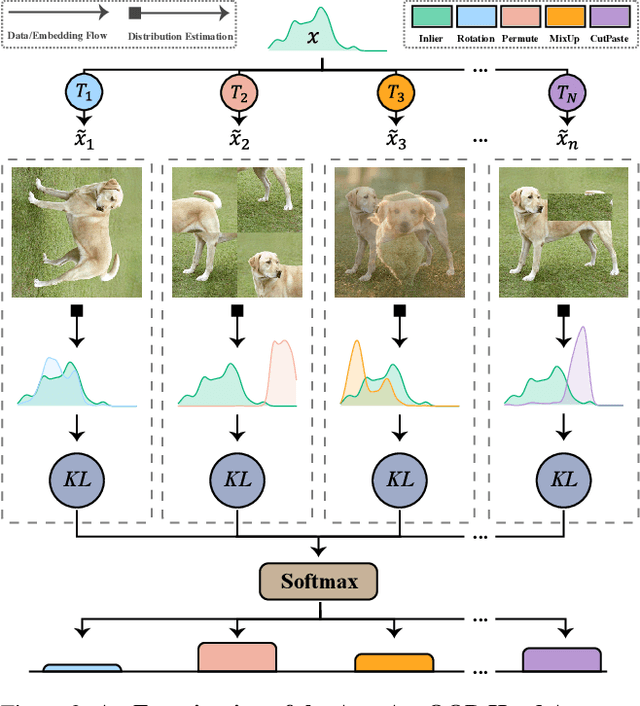


Novelty detection is a critical task for deploying machine learning models in the open world. A crucial property of novelty detection methods is universality, which can be interpreted as generalization across various distributions of training or test data. More precisely, for novelty detection, distribution shifts may occur in the training set or the test set. Shifts in the training set refer to cases where we train a novelty detector on a new dataset and expect strong transferability. Conversely, distribution shifts in the test set indicate the methods' performance when the trained model encounters a shifted test sample. We experimentally show that existing methods falter in maintaining universality, which stems from their rigid inductive biases. Motivated by this, we aim for more generalized techniques that have more adaptable inductive biases. In this context, we leverage the fact that contrastive learning provides an efficient framework to easily switch and adapt to new inductive biases through the proper choice of augmentations in forming the negative pairs. We propose a novel probabilistic auto-negative pair generation method AutoAugOOD, along with contrastive learning, to yield a universal novelty detector method. Our experiments demonstrate the superiority of our method under different distribution shifts in various image benchmark datasets. Notably, our method emerges universality in the lens of adaptability to different setups of novelty detection, including one-class, unlabeled multi-class, and labeled multi-class settings. Code: https://github.com/mojtaba-nafez/UNODE
Seeking Next Layer Neurons' Attention for Error-Backpropagation-Like Training in a Multi-Agent Network Framework
Oct 15, 2023
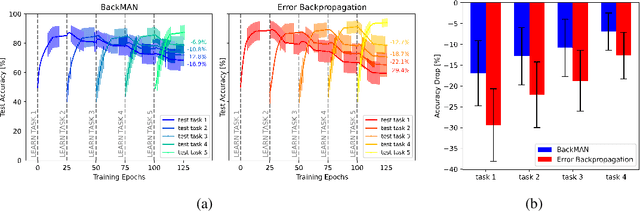

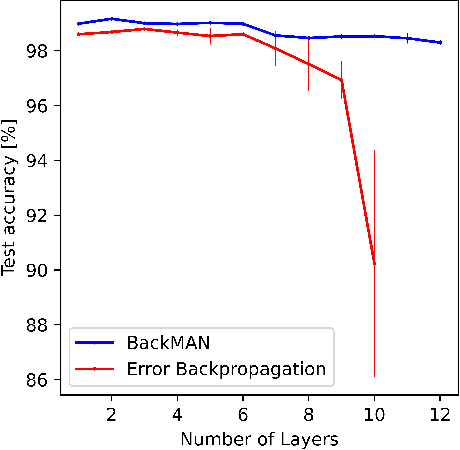
Despite considerable theoretical progress in the training of neural networks viewed as a multi-agent system of neurons, particularly concerning biological plausibility and decentralized training, their applicability to real-world problems remains limited due to scalability issues. In contrast, error-backpropagation has demonstrated its effectiveness for training deep networks in practice. In this study, we propose a local objective for neurons that, when pursued by neurons individually, align them to exhibit similarities to error-backpropagation in terms of efficiency and scalability during training. For this purpose, we examine a neural network comprising decentralized, self-interested neurons seeking to maximize their local objective -- attention from subsequent layer neurons -- and identify the optimal strategy for neurons. We also analyze the relationship between this strategy and backpropagation, establishing conditions under which the derived strategy is equivalent to error-backpropagation. Lastly, we demonstrate the learning capacity of these multi-agent neural networks through experiments on three datasets and showcase their superior performance relative to error-backpropagation in a catastrophic forgetting benchmark.