 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISTIL: Data-Free Inversion of Suspicious Trojan Inputs via Latent Diffusion
Jul 30, 2025Deep neural networks have demonstrated remarkable success across numerous tasks, yet they remain vulnerable to Trojan (backdoor) attacks, raising serious concerns about their safety in real-world mission-critical applications. A common countermeasure is trigger inversion -- reconstructing malicious "shortcut" patterns (triggers) inserted by an adversary during training. Current trigger-inversion methods typically search the full pixel space under specific assumptions but offer no assurances that the estimated trigger is more than an adversarial perturbation that flips the model output. Here, we propose a data-free, zero-shot trigger-inversion strategy that restricts the search space while avoiding strong assumptions on trigger appearance. Specifically, we incorporate a diffusion-based generator guided by the target classifier; through iterative generation, we produce candidate triggers that align with the internal representations the model relies on for malicious behavior. Empirical evaluations, both quantitative and qualitative, show that our approach reconstructs triggers that effectively distinguish clean versus Trojaned models. DISTIL surpasses alternative methods by high margins, achieving up to 7.1% higher accuracy on the BackdoorBench dataset and a 9.4% improvement on trojaned object detection model scanning, offering a promising new direction for reliable backdoor defense without reliance on extensive data or strong prior assumptions about triggers. The code is available at https://github.com/AdaptiveMotorControlLab/DISTIL.
RODEO: Robust Outlier Detection via Exposing Adaptive Out-of-Distribution Samples
Jan 28, 2025In recent years, there have been significant improvements in various forms of image outlier detection. However, outlier detection performance under adversarial settings lags far behind that in standard settings. This is due to the lack of effective exposure to adversarial scenarios during training, especially on unseen outliers, leading to detection models failing to learn robust features. To bridge this gap, we introduce RODEO, a data-centric approach that generates effective outliers for robust outlier detection. More specifically, we show that incorporating outlier exposure (OE) and adversarial training can be an effective strategy for this purpose, as long as the exposed training outliers meet certain characteristics, including diversity, and both conceptual differentiability and analogy to the inlier samples. We leverage a text-to-image model to achieve this goal. We demonstrate both quantitatively and qualitatively that our adaptive OE method effectively generates ``diverse'' and ``near-distribution'' outliers, leveraging information from both text and image domains. Moreover, our experimental results show that utilizing our synthesized outliers significantly enhances the performance of the outlier detector, particularly in adversarial settings.
GS-VTON: Controllable 3D Virtual Try-on with Gaussian Splatting
Oct 07, 2024
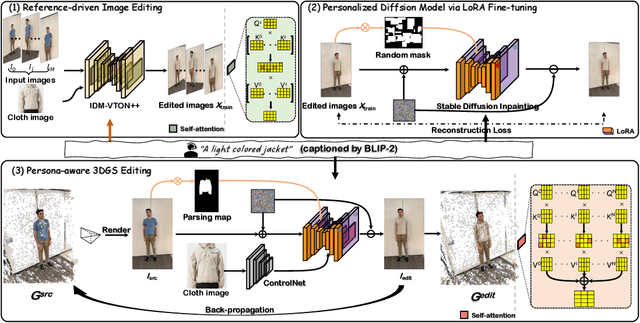


Diffusion-based 2D virtual try-on (VTON) techniques have recently demonstrated strong performance, while the development of 3D VTON has largely lagged behind. Despite recent advances in text-guided 3D scene editing, integrating 2D VTON into these pipelines to achieve vivid 3D VTON remains challenging. The reasons are twofold. First, text prompts cannot provide sufficient details in describing clothing. Second, 2D VTON results generated from different viewpoints of the same 3D scene lack coherence and spatial relationships, hence frequently leading to appearance inconsistencies and geometric distortions. To resolve these problems, we introduce an image-prompted 3D VTON method (dubbed GS-VTON) which, by leveraging 3D Gaussian Splatting (3DGS) as the 3D representation, enables the transfer of pre-trained knowledge from 2D VTON models to 3D while improving cross-view consistency. (1) Specifically, we propose a personalized diffusion model that utilizes low-rank adaptation (LoRA) fine-tuning to incorporate personalized information into pre-trained 2D VTON models. To achieve effective LoRA training, we introduce a reference-driven image editing approach that enables the simultaneous editing of multi-view images while ensuring consistency. (2) Furthermore, we propose a persona-aware 3DGS editing framework to facilitate effective editing while maintaining consistent cross-view appearance and high-quality 3D geometry. (3) Additionally, we have established a new 3D VTON benchmark, 3D-VTONBench, which facilitates comprehensive qualitative and quantitative 3D VTON evaluations. Through extensive experiments and comparative analyses with existing methods, the proposed \OM has demonstrated superior fidelity and advanced editing capabilities, affirming its effectiveness for 3D VTON.