 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRODEO: Robust Outlier Detection via Exposing Adaptive Out-of-Distribution Samples
Jan 28, 2025In recent years, there have been significant improvements in various forms of image outlier detection. However, outlier detection performance under adversarial settings lags far behind that in standard settings. This is due to the lack of effective exposure to adversarial scenarios during training, especially on unseen outliers, leading to detection models failing to learn robust features. To bridge this gap, we introduce RODEO, a data-centric approach that generates effective outliers for robust outlier detection. More specifically, we show that incorporating outlier exposure (OE) and adversarial training can be an effective strategy for this purpose, as long as the exposed training outliers meet certain characteristics, including diversity, and both conceptual differentiability and analogy to the inlier samples. We leverage a text-to-image model to achieve this goal. We demonstrate both quantitatively and qualitatively that our adaptive OE method effectively generates ``diverse'' and ``near-distribution'' outliers, leveraging information from both text and image domains. Moreover, our experimental results show that utilizing our synthesized outliers significantly enhances the performance of the outlier detector, particularly in adversarial settings.
Universal Novelty Detection Through Adaptive Contrastive Learning
Aug 20, 2024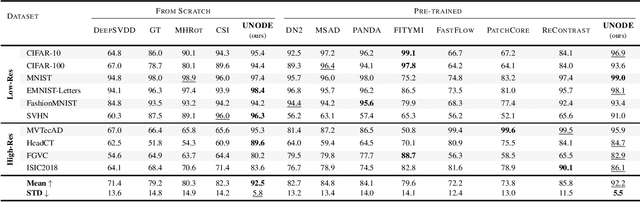
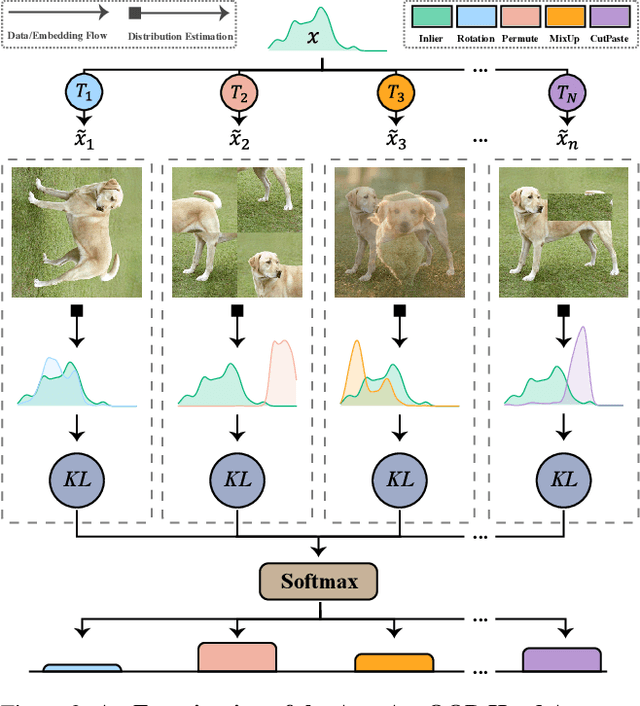


Novelty detection is a critical task for deploying machine learning models in the open world. A crucial property of novelty detection methods is universality, which can be interpreted as generalization across various distributions of training or test data. More precisely, for novelty detection, distribution shifts may occur in the training set or the test set. Shifts in the training set refer to cases where we train a novelty detector on a new dataset and expect strong transferability. Conversely, distribution shifts in the test set indicate the methods' performance when the trained model encounters a shifted test sample. We experimentally show that existing methods falter in maintaining universality, which stems from their rigid inductive biases. Motivated by this, we aim for more generalized techniques that have more adaptable inductive biases. In this context, we leverage the fact that contrastive learning provides an efficient framework to easily switch and adapt to new inductive biases through the proper choice of augmentations in forming the negative pairs. We propose a novel probabilistic auto-negative pair generation method AutoAugOOD, along with contrastive learning, to yield a universal novelty detector method. Our experiments demonstrate the superiority of our method under different distribution shifts in various image benchmark datasets. Notably, our method emerges universality in the lens of adaptability to different setups of novelty detection, including one-class, unlabeled multi-class, and labeled multi-class settings. Code: https://github.com/mojtaba-nafez/UNODE
Mitigating Overconfidence in Out-of-Distribution Detection by Capturing Extreme Activations
May 21, 2024Detecting out-of-distribution (OOD) instances is crucial for the reliable deployment of machine learning models in real-world scenarios. OOD inputs are commonly expected to cause a more uncertain prediction in the primary task; however, there are OOD cases for which the model returns a highly confident prediction. This phenomenon, denoted as "overconfidence", presents a challenge to OOD detection. Specifically, theoretical evidence indicates that overconfidence is an intrinsic property of certain neural network architectures, leading to poor OOD detection. In this work, we address this issue by measuring extreme activation values in the penultimate layer of neural networks and then leverage this proxy of overconfidence to improve on several OOD detection baselines. We test our method on a wide array of experiments spanning synthetic data and real-world data, tabular and image datasets, multiple architectures such as ResNet and Transformer, different training loss functions, and include the scenarios examined in previous theoretical work. Compared to the baselines, our method often grants substantial improvements, with double-digit increases in OOD detection AUC, and it does not damage performance in any scenario.
Spuriosity Rankings for Free: A Simple Framework for Last Layer Retraining Based on Object Detection
Oct 31, 2023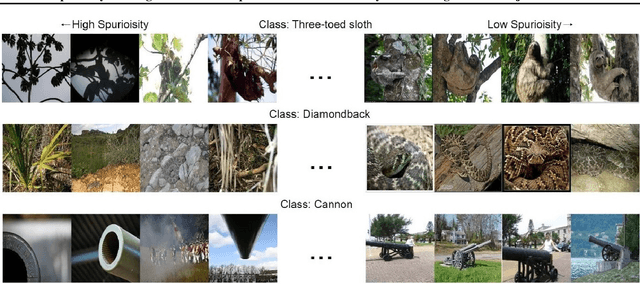

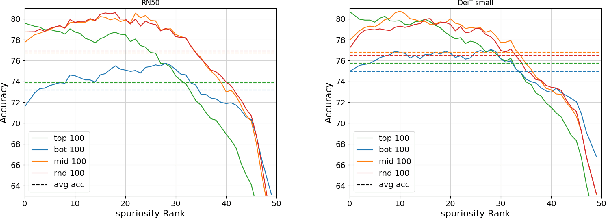
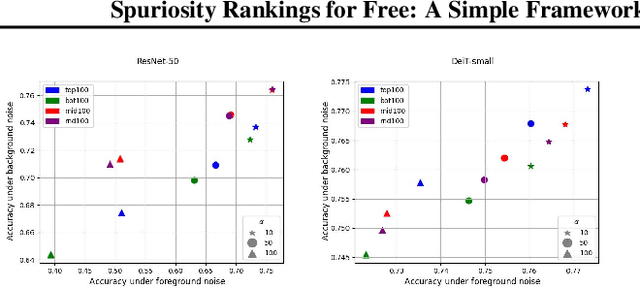
Deep neural networks have exhibited remarkable performance in various domains. However, the reliance of these models on spurious features has raised concerns about their reliability. A promising solution to this problem is last-layer retraining, which involves retraining the linear classifier head on a small subset of data without spurious cues. Nevertheless, selecting this subset requires human supervision, which reduces its scalability. Moreover, spurious cues may still exist in the selected subset. As a solution to this problem, we propose a novel ranking framework that leverages an open vocabulary object detection technique to identify images without spurious cues. More specifically, we use the object detector as a measure to score the presence of the target object in the images. Next, the images are sorted based on this score, and the last-layer of the model is retrained on a subset of the data with the highest scores. Our experiments on the ImageNet-1k dataset demonstrate the effectiveness of this ranking framework in sorting images based on spuriousness and using them for last-layer retraining.
Blacksmith: Fast Adversarial Training of Vision Transformers via a Mixture of Single-step and Multi-step Methods
Oct 29, 2023



Despite the remarkable success achieved by deep learning algorithms in various domains, such as computer vision, they remain vulnerable to adversarial perturbations. Adversarial Training (AT) stands out as one of the most effective solutions to address this issue; however, single-step AT can lead to Catastrophic Overfitting (CO). This scenario occurs when the adversarially trained network suddenly loses robustness against multi-step attacks like Projected Gradient Descent (PGD). Although several approaches have been proposed to address this problem in Convolutional Neural Networks (CNNs), we found out that they do not perform well when applied to Vision Transformers (ViTs). In this paper, we propose Blacksmith, a novel training strategy to overcome the CO problem, specifically in ViTs. Our approach utilizes either of PGD-2 or Fast Gradient Sign Method (FGSM) randomly in a mini-batch during the adversarial training of the neural network. This will increase the diversity of our training attacks, which could potentially mitigate the CO issue. To manage the increased training time resulting from this combination, we craft the PGD-2 attack based on only the first half of the layers, while FGSM is applied end-to-end. Through our experiments, we demonstrate that our novel method effectively prevents CO, achieves PGD-2 level performance, and outperforms other existing techniques including N-FGSM, which is the state-of-the-art method in fast training for CNNs.
Seeking Next Layer Neurons' Attention for Error-Backpropagation-Like Training in a Multi-Agent Network Framework
Oct 15, 2023
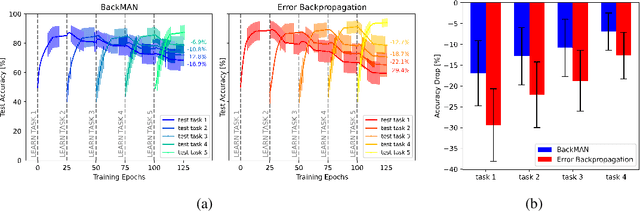

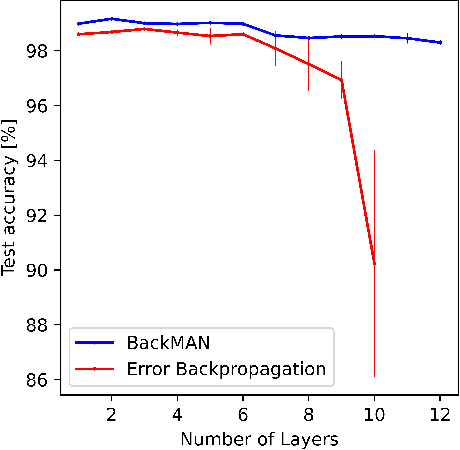
Despite considerable theoretical progress in the training of neural networks viewed as a multi-agent system of neurons, particularly concerning biological plausibility and decentralized training, their applicability to real-world problems remains limited due to scalability issues. In contrast, error-backpropagation has demonstrated its effectiveness for training deep networks in practice. In this study, we propose a local objective for neurons that, when pursued by neurons individually, align them to exhibit similarities to error-backpropagation in terms of efficiency and scalability during training. For this purpose, we examine a neural network comprising decentralized, self-interested neurons seeking to maximize their local objective -- attention from subsequent layer neurons -- and identify the optimal strategy for neurons. We also analyze the relationship between this strategy and backpropagation, establishing conditions under which the derived strategy is equivalent to error-backpropagation. Lastly, we demonstrate the learning capacity of these multi-agent neural networks through experiments on three datasets and showcase their superior performance relative to error-backpropagation in a catastrophic forgetting benchmark.
Unmasking the Chameleons: A Benchmark for Out-of-Distribution Detection in Medical Tabular Data
Sep 28, 2023Despite their success, Machine Learning (ML) models do not generalize effectively to data not originating from the training distribution. To reliably employ ML models in real-world healthcare systems and avoid inaccurate predictions on out-of-distribution (OOD) data, it is crucial to detect OOD samples. Numerous OOD detection approaches have been suggested in other fields - especially in computer vision - but it remains unclear whether the challenge is resolved when dealing with medical tabular data. To answer this pressing need, we propose an extensive reproducible benchmark to compare different methods across a suite of tests including both near and far OODs. Our benchmark leverages the latest versions of eICU and MIMIC-IV, two public datasets encompassing tens of thousands of ICU patients in several hospitals. We consider a wide array of density-based methods and SOTA post-hoc detectors across diverse predictive architectures, including MLP, ResNet, and Transformer. Our findings show that i) the problem appears to be solved for far-OODs, but remains open for near-OODs; ii) post-hoc methods alone perform poorly, but improve substantially when coupled with distance-based mechanisms; iii) the transformer architecture is far less overconfident compared to MLP and ResNet.
A Data-Centric Approach for Improving Adversarial Training Through the Lens of Out-of-Distribution Detection
Jan 25, 2023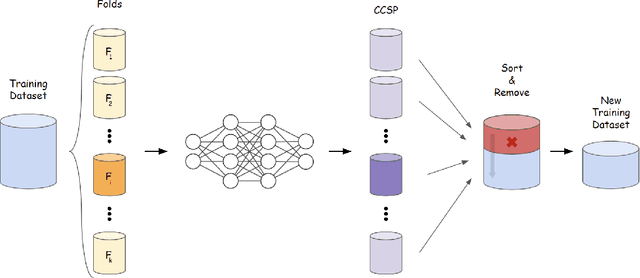

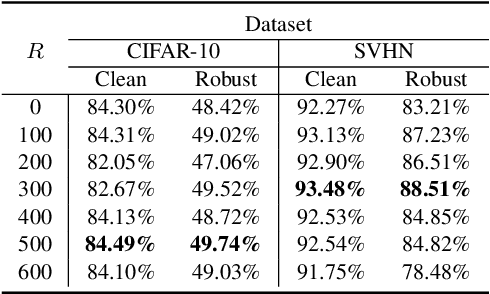
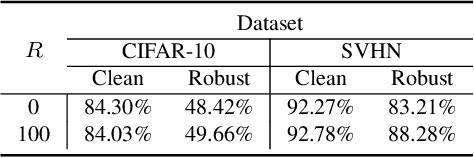
Current machine learning models achieve super-human performance in many real-world applications. Still, they are susceptible against imperceptible adversarial perturbations. The most effective solution for this problem is adversarial training that trains the model with adversarially perturbed samples instead of original ones. Various methods have been developed over recent years to improve adversarial training such as data augmentation or modifying training attacks. In this work, we examine the same problem from a new data-centric perspective. For this purpose, we first demonstrate that the existing model-based methods can be equivalent to applying smaller perturbation or optimization weights to the hard training examples. By using this finding, we propose detecting and removing these hard samples directly from the training procedure rather than applying complicated algorithms to mitigate their effects. For detection, we use maximum softmax probability as an effective method in out-of-distribution detection since we can consider the hard samples as the out-of-distribution samples for the whole data distribution. Our results on SVHN and CIFAR-10 datasets show the effectiveness of this method in improving the adversarial training without adding too much computational cost.
Your Out-of-Distribution Detection Method is Not Robust!
Sep 30, 2022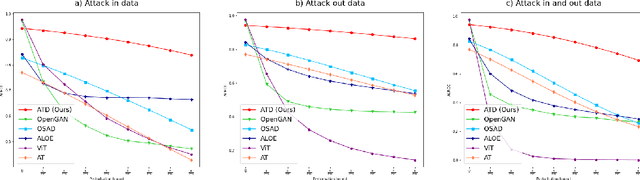
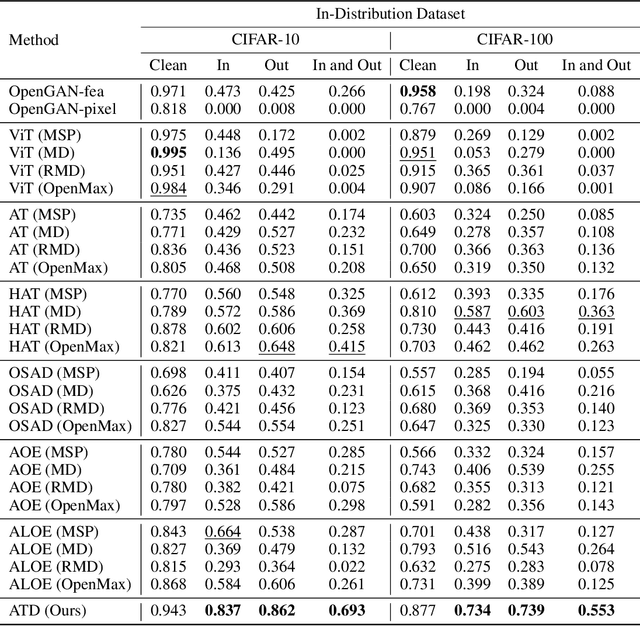
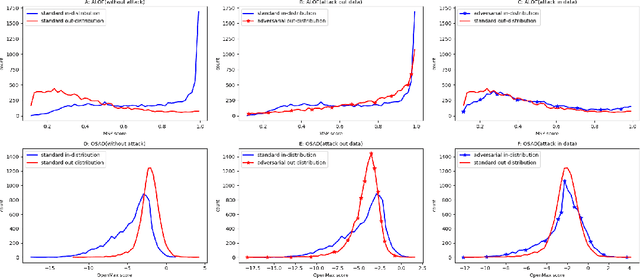

Out-of-distribution (OOD) detection has recently gained substantial attention due to the importance of identifying out-of-domain samples in reliability and safety. Although OOD detection methods have advanced by a great deal, they are still susceptible to adversarial examples, which is a violation of their purpose. To mitigate this issue, several defenses have recently been proposed. Nevertheless, these efforts remained ineffective, as their evaluations are based on either small perturbation sizes, or weak attacks. In this work, we re-examine these defenses against an end-to-end PGD attack on in/out data with larger perturbation sizes, e.g. up to commonly used $\epsilon=8/255$ for the CIFAR-10 dataset. Surprisingly, almost all of these defenses perform worse than a random detection under the adversarial setting. Next, we aim to provide a robust OOD detection method. In an ideal defense, the training should expose the model to almost all possible adversarial perturbations, which can be achieved through adversarial training. That is, such training perturbations should based on both in- and out-of-distribution samples. Therefore, unlike OOD detection in the standard setting, access to OOD, as well as in-distribution, samples sounds necessary in the adversarial training setup. These tips lead us to adopt generative OOD detection methods, such as OpenGAN, as a baseline. We subsequently propose the Adversarially Trained Discriminator (ATD), which utilizes a pre-trained robust model to extract robust features, and a generator model to create OOD samples. Using ATD with CIFAR-10 and CIFAR-100 as the in-distribution data, we could significantly outperform all previous methods in the robust AUROC while maintaining high standard AUROC and classification accuracy. The code repository is available at https://github.com/rohban-lab/ATD .
PIAT: Physics Informed Adversarial Training for Solving Partial Differential Equations
Jul 14, 2022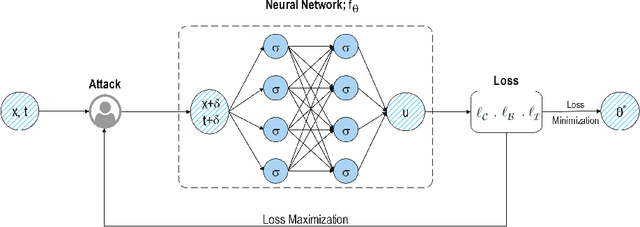

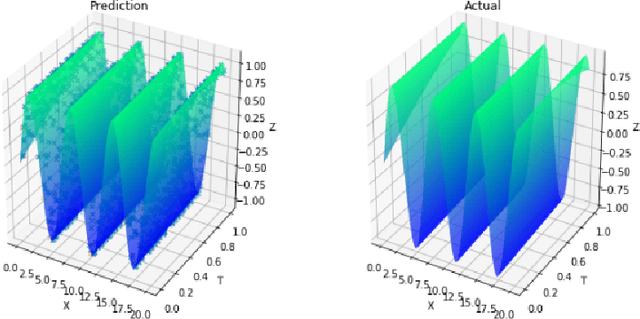

In this paper, we propose the physics informed adversarial training (PIAT) of neural networks for solving nonlinear differential equations (NDE). It is well-known that the standard training of neural networks results in non-smooth functions. Adversarial training (AT) is an established defense mechanism against adversarial attacks, which could also help in making the solution smooth. AT include augmenting the training mini-batch with a perturbation that makes the network output mismatch the desired output adversarially. Unlike formal AT, which relies only on the training data, here we encode the governing physical laws in the form of nonlinear differential equations using automatic differentiation in the adversarial network architecture. We compare PIAT with PINN to indicate the effectiveness of our method in solving NDEs for up to 10 dimensions. Moreover, we propose weight decay and Gaussian smoothing to demonstrate the PIAT advantages. The code repository is available at https://github.com/rohban-lab/PIAT.