 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuppressing Noise Disparity in Training Data for Automatic Pathological Speech Detection
Sep 02, 2024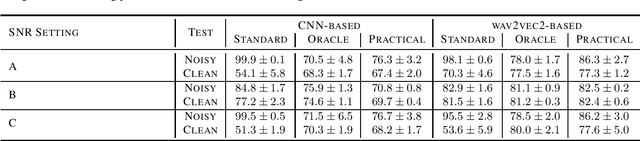
Although automatic pathological speech detection approaches show promising results when clean recordings are available, they are vulnerable to additive noise. Recently it has been shown that databases commonly used to develop and evaluate such approaches are noisy, with the noise characteristics between healthy and pathological recordings being different. Consequently, automatic approaches trained on these databases often learn to discriminate noise rather than speech pathology. This paper introduces a method to mitigate this noise disparity in training data. Using noise estimates from recordings from one group of speakers to augment recordings from the other group, the noise characteristics become consistent across all recordings. Experimental results demonstrate the efficacy of this approach in mitigating noise disparity in training data, thereby enabling automatic pathological speech detection to focus on pathology-discriminant cues rather than noise-discriminant ones.
Spuriosity Rankings for Free: A Simple Framework for Last Layer Retraining Based on Object Detection
Oct 31, 2023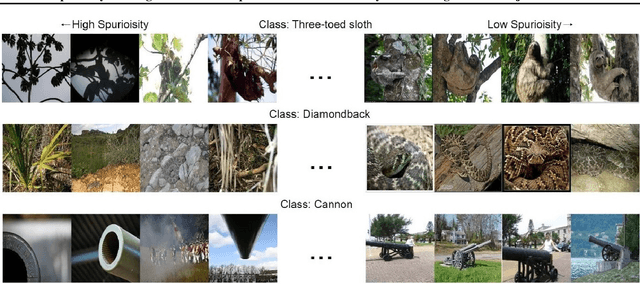

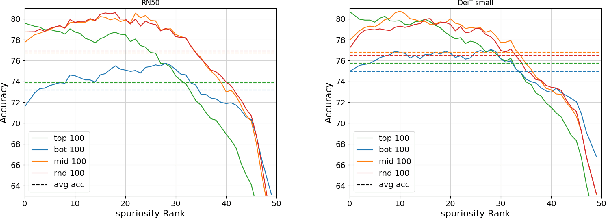
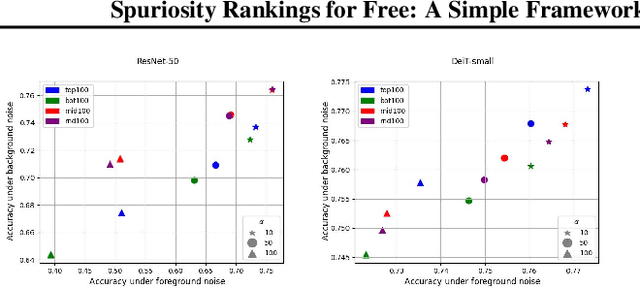
Deep neural networks have exhibited remarkable performance in various domains. However, the reliance of these models on spurious features has raised concerns about their reliability. A promising solution to this problem is last-layer retraining, which involves retraining the linear classifier head on a small subset of data without spurious cues. Nevertheless, selecting this subset requires human supervision, which reduces its scalability. Moreover, spurious cues may still exist in the selected subset. As a solution to this problem, we propose a novel ranking framework that leverages an open vocabulary object detection technique to identify images without spurious cues. More specifically, we use the object detector as a measure to score the presence of the target object in the images. Next, the images are sorted based on this score, and the last-layer of the model is retrained on a subset of the data with the highest scores. Our experiments on the ImageNet-1k dataset demonstrate the effectiveness of this ranking framework in sorting images based on spuriousness and using them for last-layer retraining.
Blacksmith: Fast Adversarial Training of Vision Transformers via a Mixture of Single-step and Multi-step Methods
Oct 29, 2023



Despite the remarkable success achieved by deep learning algorithms in various domains, such as computer vision, they remain vulnerable to adversarial perturbations. Adversarial Training (AT) stands out as one of the most effective solutions to address this issue; however, single-step AT can lead to Catastrophic Overfitting (CO). This scenario occurs when the adversarially trained network suddenly loses robustness against multi-step attacks like Projected Gradient Descent (PGD). Although several approaches have been proposed to address this problem in Convolutional Neural Networks (CNNs), we found out that they do not perform well when applied to Vision Transformers (ViTs). In this paper, we propose Blacksmith, a novel training strategy to overcome the CO problem, specifically in ViTs. Our approach utilizes either of PGD-2 or Fast Gradient Sign Method (FGSM) randomly in a mini-batch during the adversarial training of the neural network. This will increase the diversity of our training attacks, which could potentially mitigate the CO issue. To manage the increased training time resulting from this combination, we craft the PGD-2 attack based on only the first half of the layers, while FGSM is applied end-to-end. Through our experiments, we demonstrate that our novel method effectively prevents CO, achieves PGD-2 level performance, and outperforms other existing techniques including N-FGSM, which is the state-of-the-art method in fast training for CNNs.