 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuppressing Noise Disparity in Training Data for Automatic Pathological Speech Detection
Paper and Code
Sep 02, 2024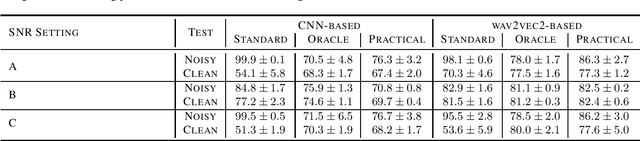
Although automatic pathological speech detection approaches show promising results when clean recordings are available, they are vulnerable to additive noise. Recently it has been shown that databases commonly used to develop and evaluate such approaches are noisy, with the noise characteristics between healthy and pathological recordings being different. Consequently, automatic approaches trained on these databases often learn to discriminate noise rather than speech pathology. This paper introduces a method to mitigate this noise disparity in training data. Using noise estimates from recordings from one group of speakers to augment recordings from the other group, the noise characteristics become consistent across all recordings. Experimental results demonstrate the efficacy of this approach in mitigating noise disparity in training data, thereby enabling automatic pathological speech detection to focus on pathology-discriminant cues rather than noise-discriminant ones.