 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAP-Based Automatic Word Naming Recognition in Post-Stroke Aphasia
Feb 16, 2026Conventional automatic word-naming recognition systems struggle to recognize words from post-stroke patients with aphasia because of disfluencies and mispronunciations, limiting reliable automated assessment in this population. In this paper, we propose a Contrastive Language-Audio Pretraining (CLAP) based approach for automatic word-naming recognition to address this challenge by leveraging text-audio alignment. Our approach treats word-naming recognition as an audio-text matching problem, projecting speech signals and textual prompts into a shared embedding space to identify intended words even in challenging recordings. Evaluated on two speech datasets of French post-stroke patients with aphasia, our approach achieves up to 90% accuracy, outperforming existing classification-based and automatic speech recognition-based baselines.
Data Augmentation for Pathological Speech Enhancement
Feb 16, 2026The performance of state-of-the-art speech enhancement (SE) models considerably degrades for pathological speech due to atypical acoustic characteristics and limited data availability. This paper systematically investigates data augmentation (DA) strategies to improve SE performance for pathological speakers, evaluating both predictive and generative SE models. We examine three DA categories, i.e., transformative, generative, and noise augmentation, assessing their impact with objective SE metrics. Experimental results show that noise augmentation consistently delivers the largest and most robust gains, transformative augmentations provide moderate improvements, while generative augmentation yields limited benefits and can harm performance as the amount of synthetic data increases. Furthermore, we show that the effectiveness of DA varies depending on the SE model, with DA being more beneficial for predictive SE models. While our results demonstrate that DA improves SE performance for pathological speakers, a performance gap between neurotypical and pathological speech persists, highlighting the need for future research on targeted DA strategies for pathological speech.
Towards interpretable emotion recognition: Identifying key features with machine learning
Aug 06, 2025Unsupervised methods, such as wav2vec2 and HuBERT, have achieved state-of-the-art performance in audio tasks, leading to a shift away from research on interpretable features. However, the lack of interpretability in these methods limits their applicability in critical domains like medicine, where understanding feature relevance is crucial. To better understand the features of unsupervised models, it remains critical to identify the interpretable features relevant to a given task. In this work, we focus on emotion recognition and use machine learning algorithms to identify and generalize the most important interpretable features for this task. While previous studies have explored feature relevance in emotion recognition, they are often constrained by narrow contexts and present inconsistent findings. Our approach aims to overcome these limitations, providing a broader and more robust framework for identifying the most important interpretable features.
Variational Autoencoder for Personalized Pathological Speech Enhancement
Mar 18, 2025
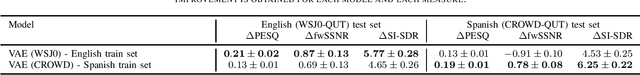

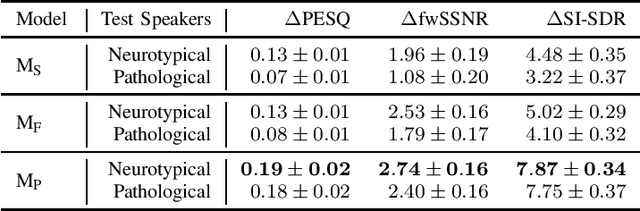
The generalizability of speech enhancement (SE) models across speaker conditions remains largely unexplored, despite its critical importance for broader applicability. This paper investigates the performance of the hybrid variational autoencoder (VAE)-non-negative matrix factorization (NMF) model for SE, focusing primarily on its generalizability to pathological speakers with Parkinson's disease. We show that VAE models trained on large neurotypical datasets perform poorly on pathological speech. While fine-tuning these pre-trained models with pathological speech improves performance, a performance gap remains between neurotypical and pathological speakers. To address this gap, we propose using personalized SE models derived from fine-tuning pre-trained models with only a few seconds of clean data from each speaker. Our results demonstrate that personalized models considerably enhance performance for all speakers, achieving comparable results for both neurotypical and pathological speakers.
A Differentiable Alignment Framework for Sequence-to-Sequence Modeling via Optimal Transport
Feb 03, 2025



Accurate sequence-to-sequence (seq2seq) alignment is critical for applications like medical speech analysis and language learning tools relying on automatic speech recognition (ASR). State-of-the-art end-to-end (E2E) ASR systems, such as the Connectionist Temporal Classification (CTC) and transducer-based models, suffer from peaky behavior and alignment inaccuracies. In this paper, we propose a novel differentiable alignment framework based on one-dimensional optimal transport, enabling the model to learn a single alignment and perform ASR in an E2E manner. We introduce a pseudo-metric, called Sequence Optimal Transport Distance (SOTD), over the sequence space and discuss its theoretical properties. Based on the SOTD, we propose Optimal Temporal Transport Classification (OTTC) loss for ASR and contrast its behavior with CTC. Experimental results on the TIMIT, AMI, and LibriSpeech datasets show that our method considerably improves alignment performance, though with a trade-off in ASR performance when compared to CTC. We believe this work opens new avenues for seq2seq alignment research, providing a solid foundation for further exploration and development within the community.
Deep Learning for Pathological Speech: A Survey
Jan 07, 2025
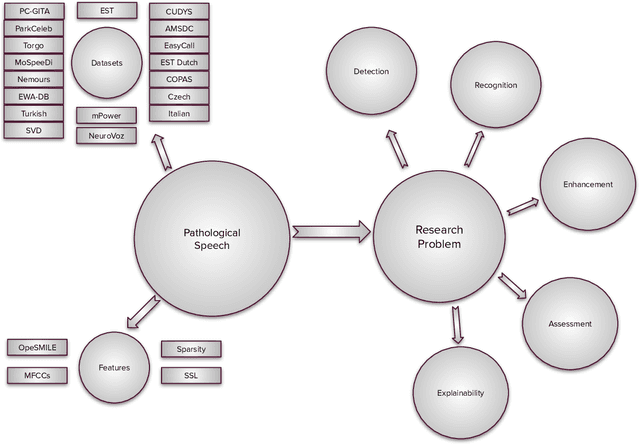

Advancements in spoken language technologies for neurodegenerative speech disorders are crucial for meeting both clinical and technological needs. This overview paper is vital for advancing the field, as it presents a comprehensive review of state-of-the-art methods in pathological speech detection, automatic speech recognition, pathological speech intelligibility enhancement, intelligibility and severity assessment, and data augmentation approaches for pathological speech. It also high-lights key challenges, such as ensuring robustness, privacy, and interpretability. The paper concludes by exploring promising future directions, including the adoption of multimodal approaches and the integration of graph neural networks and large language models to further advance speech technology for neurodegenerative speech disorders
Graph Neural Networks for Parkinsons Disease Detection
Sep 12, 2024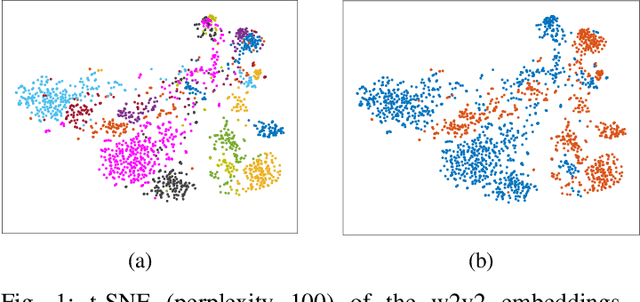
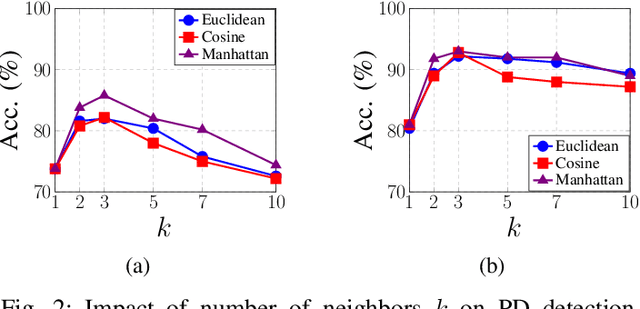
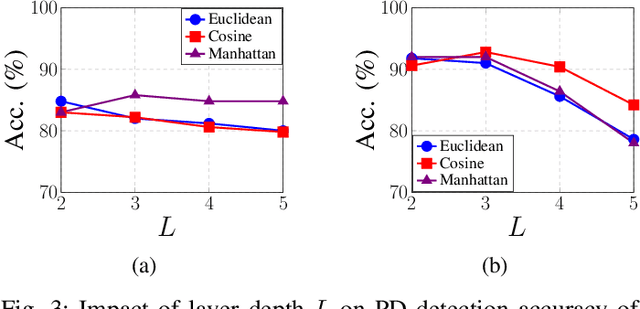
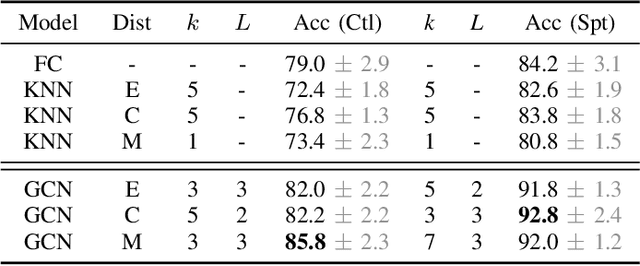
Despite the promising performance of state of the art approaches for Parkinsons Disease (PD) detection, these approaches often analyze individual speech segments in isolation, which can lead to suboptimal results. Dysarthric cues that characterize speech impairments from PD patients are expected to be related across segments from different speakers. Isolated segment analysis fails to exploit these inter segment relationships. Additionally, not all speech segments from PD patients exhibit clear dysarthric symptoms, introducing label noise that can negatively affect the performance and generalizability of current approaches. To address these challenges, we propose a novel PD detection framework utilizing Graph Convolutional Networks (GCNs). By representing speech segments as nodes and capturing the similarity between segments through edges, our GCN model facilitates the aggregation of dysarthric cues across the graph, effectively exploiting segment relationships and mitigating the impact of label noise. Experimental results demonstrate theadvantages of the proposed GCN model for PD detection and provide insights into its underlying mechanisms
Suppressing Noise Disparity in Training Data for Automatic Pathological Speech Detection
Sep 02, 2024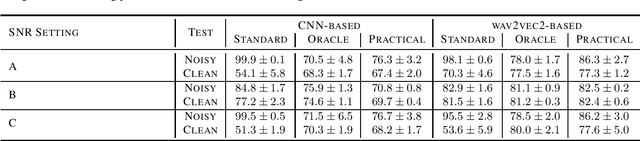
Although automatic pathological speech detection approaches show promising results when clean recordings are available, they are vulnerable to additive noise. Recently it has been shown that databases commonly used to develop and evaluate such approaches are noisy, with the noise characteristics between healthy and pathological recordings being different. Consequently, automatic approaches trained on these databases often learn to discriminate noise rather than speech pathology. This paper introduces a method to mitigate this noise disparity in training data. Using noise estimates from recordings from one group of speakers to augment recordings from the other group, the noise characteristics become consistent across all recordings. Experimental results demonstrate the efficacy of this approach in mitigating noise disparity in training data, thereby enabling automatic pathological speech detection to focus on pathology-discriminant cues rather than noise-discriminant ones.
Impact of Speech Mode in Automatic Pathological Speech Detection
Jun 14, 2024
Automatic pathological speech detection approaches yield promising results in identifying various pathologies. These approaches are typically designed and evaluated for phonetically-controlled speech scenarios, where speakers are prompted to articulate identical phonetic content. While gathering controlled speech recordings can be laborious, spontaneous speech can be conveniently acquired as potential patients navigate their daily routines. Further, spontaneous speech can be valuable in detecting subtle and abstract cues of pathological speech. Nonetheless, the efficacy of automatic pathological speech detection for spontaneous speech remains unexplored. This paper analyzes the influence of speech mode on pathological speech detection approaches, examining two distinct categories of approaches, i.e., classical machine learning and deep learning. Results indicate that classical approaches may struggle to capture pathology-discriminant cues in spontaneous speech. In contrast, deep learning approaches demonstrate superior performance, managing to extract additional cues that were previously inaccessible in non-spontaneous speech
On using the UA-Speech and TORGO databases to validate automatic dysarthric speech classification approaches
Nov 16, 2022Although the UA-Speech and TORGO databases of control and dysarthric speech are invaluable resources made available to the research community with the objective of developing robust automatic speech recognition systems, they have also been used to validate a considerable number of automatic dysarthric speech classification approaches. Such approaches typically rely on the underlying assumption that recordings from control and dysarthric speakers are collected in the same noiseless environment using the same recording setup. In this paper, we show that this assumption is violated for the UA-Speech and TORGO databases. Using voice activity detection to extract speech and non-speech segments, we show that the majority of state-of-the-art dysarthria classification approaches achieve the same or a considerably better performance when using the non-speech segments of these databases than when using the speech segments. These results demonstrate that such approaches trained and validated on the UA-Speech and TORGO databases are potentially learning characteristics of the recording environment or setup rather than dysarthric speech characteristics. We hope that these results raise awareness in the research community about the importance of the quality of recordings when developing and evaluating automatic dysarthria classification approaches.